



Apache Beamモバイルゲームパイプライン例
このセクションでは、基本的なWordCount例よりも複雑な機能を示す、一連のApache Beamパイプラインの例について説明します。このセクションのパイプラインは、ユーザーが携帯電話でプレイする架空のゲームからのデータを処理します。パイプラインは、複雑さのレベルが徐々に高くなるように処理を示しています。たとえば、最初のパイプラインは、比較的単純なスコアデータを取得するためにバッチ分析ジョブを実行する方法を示していますが、後のパイプラインでは、Beamのウィンドウ処理とトリガー機能を使用して、低遅延データ分析とユーザーのプレイパターンのより複雑なインテリジェンスを提供します。
注記:これらの例は、Beamプログラミングモデルについてのある程度の知識を前提としています。まだの場合は、プログラミングモデルのドキュメントをよく理解し、基本的な例を実行してから続行することをお勧めします。また、これらの例ではJava 8ラムダ構文を使用しているため、Java 8が必要です。ただし、Java 7を使用して同等の機能を持つパイプラインを作成できます。
注記:これらの例は、Beamプログラミングモデルについてのある程度の知識を前提としています。まだの場合は、プログラミングモデルのドキュメントをよく理解し、基本的な例を実行してから続行することをお勧めします。
注記:MobileGamingはまだGo SDKでは利用できません。これについては未解決の問題があります(Issue 18806)。
ユーザーが架空のモバイルゲームのインスタンスをプレイするたびに、データイベントを生成します。各データイベントは、次の情報で構成されます。
- ゲームをプレイしているユーザーの一意のID。
- ユーザーが所属するチームのチームID。
- その特定のプレイインスタンスのスコア値。
- 特定のプレイインスタンスが発生した時間を記録するタイムスタンプ。これは、各ゲームデータイベントのイベント時間です。
ユーザーがゲームのインスタンスを完了すると、電話機はデータイベントをゲームサーバーに送信し、そこでデータがログに記録され、ファイルに保存されます。一般的に、データは完了と同時にゲームサーバーに送信されます。ただし、さまざまなポイントでネットワークに遅延が発生することがあります。別のシナリオとして、ユーザーがサーバーと通信していない状態でゲームを「オフライン」でプレイする場合があります(飛行機内、またはネットワークカバレッジエリア外など)。ユーザーの携帯電話がゲームサーバーと再び通信できるようになると、携帯電話は蓄積されたすべてのゲームデータを送信します。これらの場合、一部のデータイベントは遅延して順序外で到着することがあります。
次の図は、理想的な状況(イベントは発生したとおりに処理される)と現実(処理される前にタイムラグがあることがよくある)を示しています。
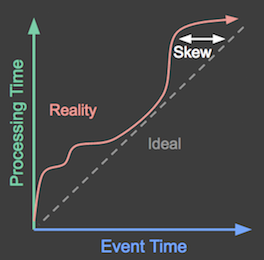
図1:X軸はイベント時間(ゲームイベントが発生した実際の時間)を表します。Y軸は処理時間(ゲームイベントが処理された時間)を表します。理想的には、イベントは発生したとおりに処理されるべきであり、図の点線で示されています。しかし、実際にはそうではなく、理想的な線の上の赤い波線のように見えます。
データイベントは、ユーザーが生成してからかなり後にゲームサーバーによって受信される場合があります。この時間差(**スキュー**と呼ばれる)は、各スコアが生成された時点を考慮した計算を行うパイプラインに処理上の影響を与える可能性があります。たとえば、そのようなパイプラインは、1日の各時間帯に生成されたスコアを追跡したり、ユーザーがゲームを連続してプレイしている時間を計算したりする可能性があります。これらは両方とも、各データレコードのイベント時間に依存しています。
例として挙げたパイプラインの一部は、入力としてデータファイル(ゲームサーバーからのログなど)を使用するため、各ゲームのイベントタイムスタンプはデータに埋め込まれている可能性があります。つまり、各データレコードのフィールドです。これらのパイプラインは、入力ファイルから読み込んだ後、各データレコードからイベントタイムスタンプを解析する必要があります。
無制限のソースから無制限のゲームデータを読み取るパイプラインの場合、データソースは各PCollection要素の固有のタイムスタンプを適切なイベント時間に設定します。
モバイルゲームの例として挙げたパイプラインは、単純なバッチ分析から、リアルタイム分析や不正検知を実行できるより複雑なパイプラインまで、複雑さが異なります。このセクションでは、各例について説明し、ウィンドウ処理やトリガーなどのBeam機能を使用してパイプラインの機能を拡張する方法を示します。
UserScore:バッチでの基本的なスコア処理
UserScoreパイプラインは、モバイルゲームデータを処理するための最も単純な例です。UserScoreは、有限のデータセット(たとえば、ゲームサーバーに保存されている1日分のスコア)にわたるユーザーごとの合計スコアを決定します。UserScoreのようなパイプラインは、関連するすべてのデータが収集された後、定期的に実行するのが最適です。たとえば、UserScoreは、その日に収集されたデータに対して毎晩ジョブとして実行できます。
注記:完全な例となるパイプラインプログラムについては、GitHubのUserScoreを参照してください。
注記:完全な例となるパイプラインプログラムについては、GitHubのUserScoreを参照してください。
UserScoreは何をするのか?
1日分のスコアリングデータでは、各ユーザーIDに複数のレコードが含まれている場合があります(ユーザーが分析ウィンドウ中にゲームを複数回プレイした場合)、それぞれに独自のスコア値とタイムスタンプがあります。1日にユーザーがプレイしたすべてのインスタンスにわたる合計スコアを決定したい場合、パイプラインはすべてのレコードを個々のユーザーごとにグループ化する必要があります。
パイプラインは各イベントを処理するときに、イベントスコアはその特定のユーザーの合計に追加されます。
UserScoreは、各レコードから必要なデータのみ、具体的にはユーザーIDとスコア値を解析します。パイプラインは、レコードのイベント時間を考慮しません。パイプラインが実行されたときに指定した入力ファイルにあるすべてのデータを単純に処理します。
注記:
UserScoreパイプラインを効果的に使用するには、目的のイベント期間で既にグループ化されている入力データを提供する必要があります。つまり、対象とする日からのデータのみが含まれる入力ファイルを指定する必要があります。
UserScoreの基本的なパイプラインフローは、次のことを行います。
- テキストファイルから1日分のスコアデータを読み取ります。
- 各ゲームイベントをユーザーIDでグループ化し、スコア値を組み合わせてその特定のユーザーの合計スコアを取得することにより、各固有ユーザーのスコア値を合計します。
- 結果データをテキストファイルに書き込みます。
次の図は、パイプライン分析期間における複数のユーザーのスコアデータを示しています。図では、各データポイントは、ユーザー/スコアのペアを1つ生成するイベントです。
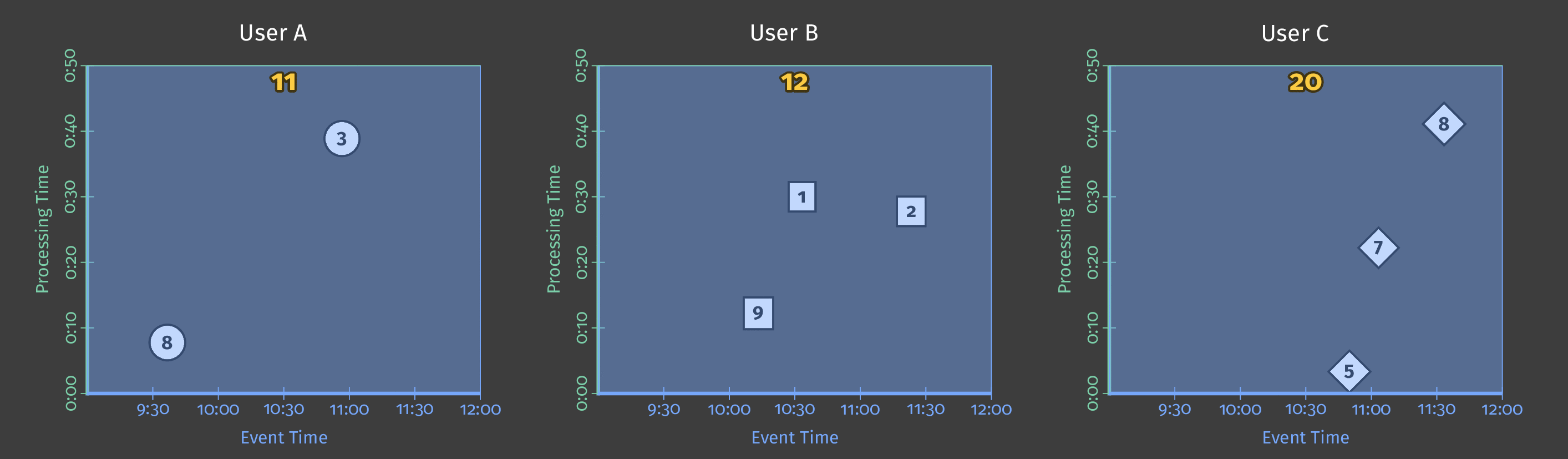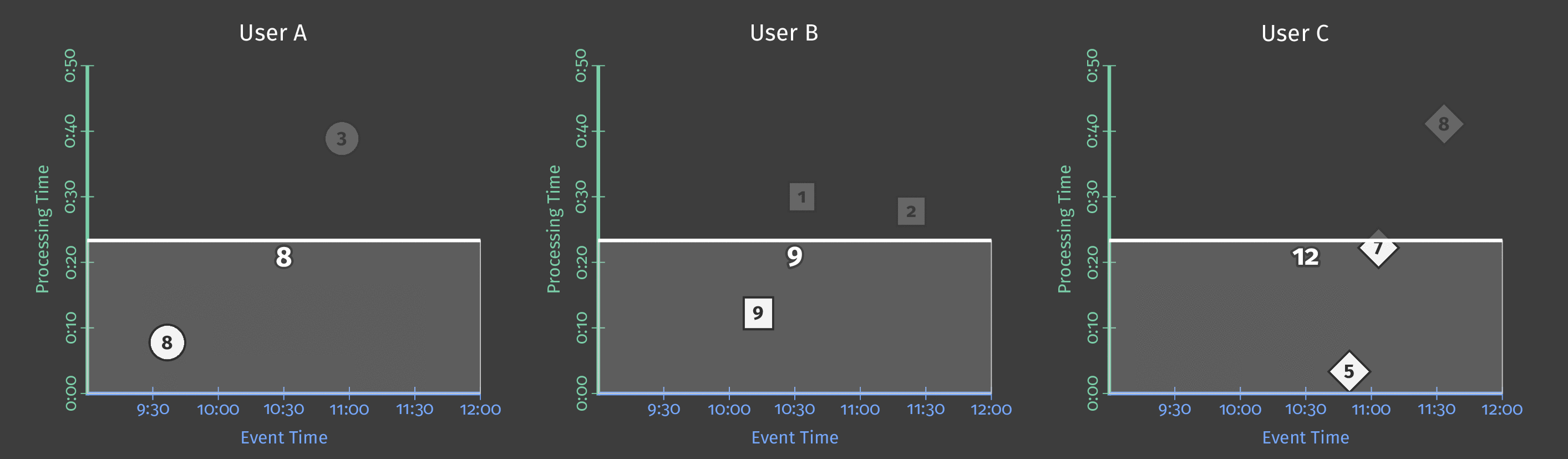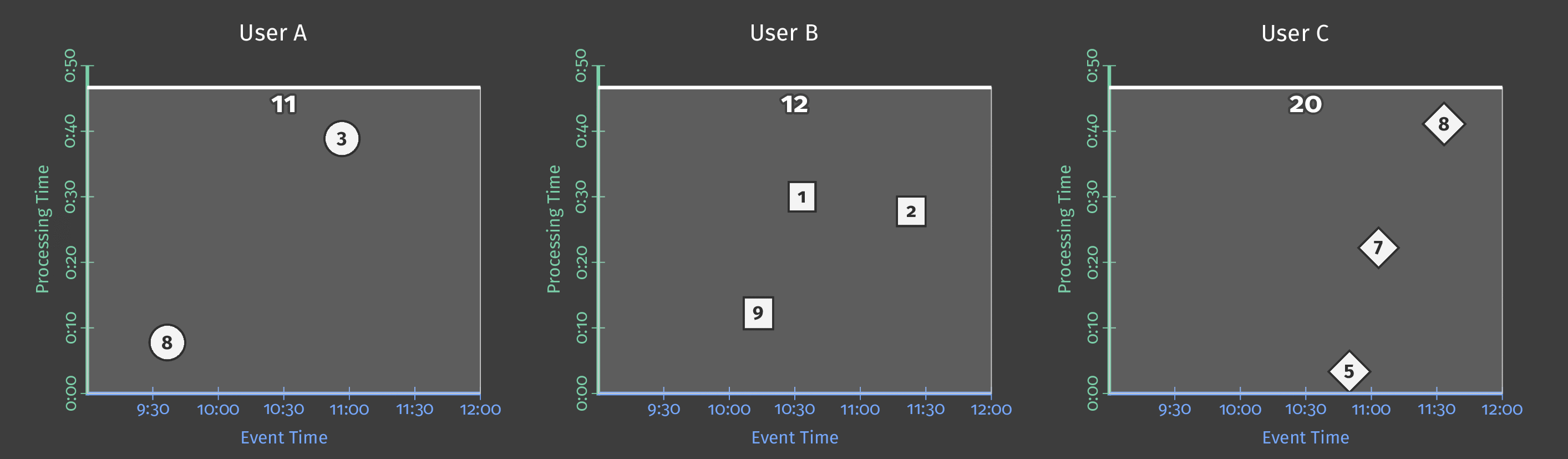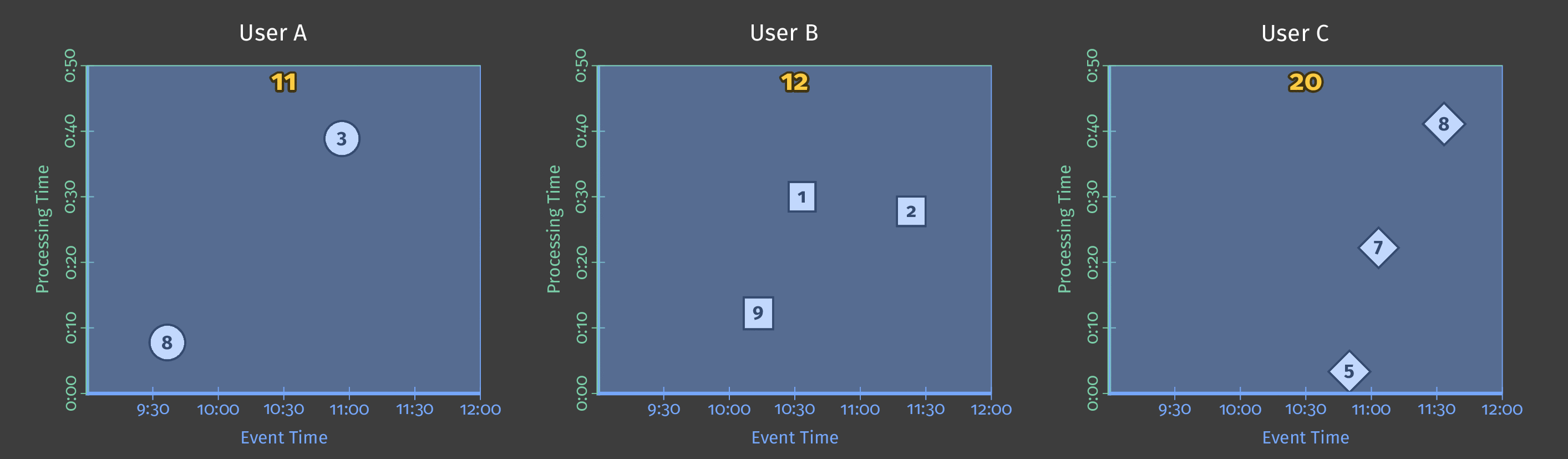
図2:3人のユーザーのスコアデータ。
この例ではバッチ処理を使用しており、図のY軸は処理時間を表しています。パイプラインは、Y軸の下にあるイベントを先に処理し、上にあるイベントを後で処理します。図のX軸は、そのイベントのタイムスタンプで示される各ゲームイベントのイベント時間を表しています。図の個々のイベントは、(タイムスタンプに従って)発生したのと同じ順序でパイプラインによって処理されるとは限りません。
入力ファイルからスコアイベントを読み込んだ後、パイプラインはそれらのユーザー/スコアペアをすべてグループ化し、一意のユーザーごとにスコア値を合計値に集計します。UserScore は、ユーザー定義の複合トランスフォームであるExtractAndSumScoreとして、そのステップの中核となるロジックをカプセル化しています。
public static class ExtractAndSumScore
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final String field;
ExtractAndSumScore(String field) {
this.field = field;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> gameInfo) {
return gameInfo
.apply(
MapElements.into(
TypeDescriptors.kvs(TypeDescriptors.strings(), TypeDescriptors.integers()))
.via((GameActionInfo gInfo) -> KV.of(gInfo.getKey(field), gInfo.getScore())))
.apply(Sum.integersPerKey());
}
}class ExtractAndSumScore(beam.PTransform):
"""A transform to extract key/score information and sum the scores.
The constructor argument `field` determines whether 'team' or 'user' info is
extracted.
"""
def __init__(self, field):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.field = field
def expand(self, pcoll):
return (
pcoll
| beam.Map(lambda elem: (elem[self.field], elem['score']))
| beam.CombinePerKey(sum))ExtractAndSumScore は、データをグループ化するフィールド(ゲームの場合は一意のユーザーまたは一意のチーム)を指定できるよう、より汎用的に記述されています。これは、たとえば、チーム別にスコアデータをグループ化する他のパイプラインでExtractAndSumScoreを再利用できることを意味します。
パイプラインの3つのステップすべてを適用する方法を示す、UserScoreのメインメソッドを次に示します。
public static void main(String[] args) throws Exception {
// Begin constructing a pipeline configured by commandline flags.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline pipeline = Pipeline.create(options);
// Read events from a text file and parse them.
pipeline
.apply(TextIO.read().from(options.getInput()))
.apply("ParseGameEvent", ParDo.of(new ParseEventFn()))
// Extract and sum username/score pairs from the event data.
.apply("ExtractUserScore", new ExtractAndSumScore("user"))
.apply(
"WriteUserScoreSums", new WriteToText<>(options.getOutput(), configureOutput(), false));
// Run the batch pipeline.
pipeline.run().waitUntilFinish();
}def run(argv=None, save_main_session=True):
"""Main entry point; defines and runs the user_score pipeline."""
parser = argparse.ArgumentParser()
# The default maps to two large Google Cloud Storage files (each ~12GB)
# holding two subsequent day's worth (roughly) of data.
parser.add_argument(
'--input',
type=str,
default='gs://apache-beam-samples/game/small/gaming_data.csv',
help='Path to the data file(s) containing game data.')
parser.add_argument(
'--output', type=str, required=True, help='Path to the output file(s).')
args, pipeline_args = parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
# We use the save_main_session option because one or more DoFn's in this
# workflow rely on global context (e.g., a module imported at module level).
options.view_as(SetupOptions).save_main_session = save_main_session
with beam.Pipeline(options=options) as p:
def format_user_score_sums(user_score):
(user, score) = user_score
return 'user: %s, total_score: %s' % (user, score)
( # pylint: disable=expression-not-assigned
p
| 'ReadInputText' >> beam.io.ReadFromText(args.input)
| 'UserScore' >> UserScore()
| 'FormatUserScoreSums' >> beam.Map(format_user_score_sums)
| 'WriteUserScoreSums' >> beam.io.WriteToText(args.output))制限事項
例にあるように、UserScoreパイプラインにはいくつかの制限があります。
一部のスコアデータはオフラインプレイヤーによって生成され、日々のカットオフ後に送信される可能性があるため、ゲームデータの場合、
UserScoreパイプラインによって生成される結果データは**不完全な可能性があります**。UserScoreは、パイプラインの実行時に、入力ファイルに存在する固定された入力セットのみを処理します。UserScoreは、処理時に入力ファイルに存在するすべてのデータイベントを処理し、**イベント時間に基づいてイベントを検査したり、エラーチェックを行ったりしません**。したがって、結果には、前日の遅延記録など、関連する分析期間外にイベント時間が含まれる値が含まれる場合があります。UserScoreはすべてのデータが収集された後にのみ実行されるため、ユーザーがデータイベントを生成する時点(イベント時間)と結果が計算される時点(処理時間)との間に**高いレイテンシ**があります。UserScoreは、1日全体の合計結果のみを報告し、データが1日の間にどのように蓄積されたかについての詳細な情報は提供しません。
次のパイプラインの例から、Beamの機能を使用してこれらの制限に対処する方法について説明します。
HourlyTeamScore:ウィンドウ処理によるバッチでの高度な処理
HourlyTeamScoreパイプラインは、UserScoreパイプラインで使用されている基本的なバッチ分析原則を拡張し、そのいくつかの制限を改善しています。HourlyTeamScoreは、Beam SDKの追加機能を使用し、ゲームデータのより多くの側面を考慮に入れることで、より詳細な分析を実行します。たとえば、HourlyTeamScoreは、関連する分析期間に含まれないデータをフィルタリングできます。
UserScoreと同様に、HourlyTeamScoreは、関連するすべてのデータが収集された後(たとえば、1日に1回)に定期的に実行されるジョブとして考えるのが最適です。パイプラインはファイルから固定されたデータセットを読み取り、結果をテキストファイルに書き込みますGoogle Cloud BigQueryテーブルに書き込みます。
注記:完全な例となるパイプラインプログラムについては、GitHubのHourlyTeamScoreを参照してください。
注記:完全な例となるパイプラインプログラムについては、GitHubのHourlyTeamScoreを参照してください。
HourlyTeamScoreは何をするのか?
HourlyTeamScoreは、固定されたデータセット(1日分のデータなど)において、チームごと、時間ごとの合計スコアを計算します。
HourlyTeamScoreは、一度にデータセット全体を操作するのではなく、入力データを論理的なウィンドウに分割し、それらのウィンドウに対して計算を実行します。これにより、HourlyUserScoreは、各ウィンドウが時間内の固定間隔(1時間ごとなど)のゲームスコアの進捗状況を表すウィンドウごとのスコアリングデータに関する情報を提供できます。HourlyTeamScoreは、イベント時間(埋め込まれたタイムスタンプで示される)が関連する分析期間内にあるかどうかを基に、データイベントをフィルタリングします。基本的に、パイプラインは各ゲームイベントのタイムスタンプをチェックし、分析したい範囲(この場合は問題の1日)内にあることを確認します。前日のデータイベントは破棄され、合計スコアに含まれません。これにより、HourlyTeamScoreは、UserScoreよりも堅牢になり、誤った結果データが発生する可能性が低くなります。また、パイプラインは、関連する分析期間内にタイムスタンプを持つ遅延データに対処することもできます。
以下では、HourlyTeamScoreのこれらの機能強化を詳しく見ていきます。
固定時間ウィンドウ
固定時間ウィンドウを使用すると、パイプラインは分析期間中にデータセットにイベントがどのように蓄積されたかについてのより良い情報を提供できます。私たちの場合、それは、1日のどの時点で各チームがアクティブで、その時点でチームがどれだけ得点したかを教えてくれます。
次の図は、固定時間ウィンドウを適用した後、パイプラインが1日分の単一チームのスコアリングデータをどのように処理するかを示しています。
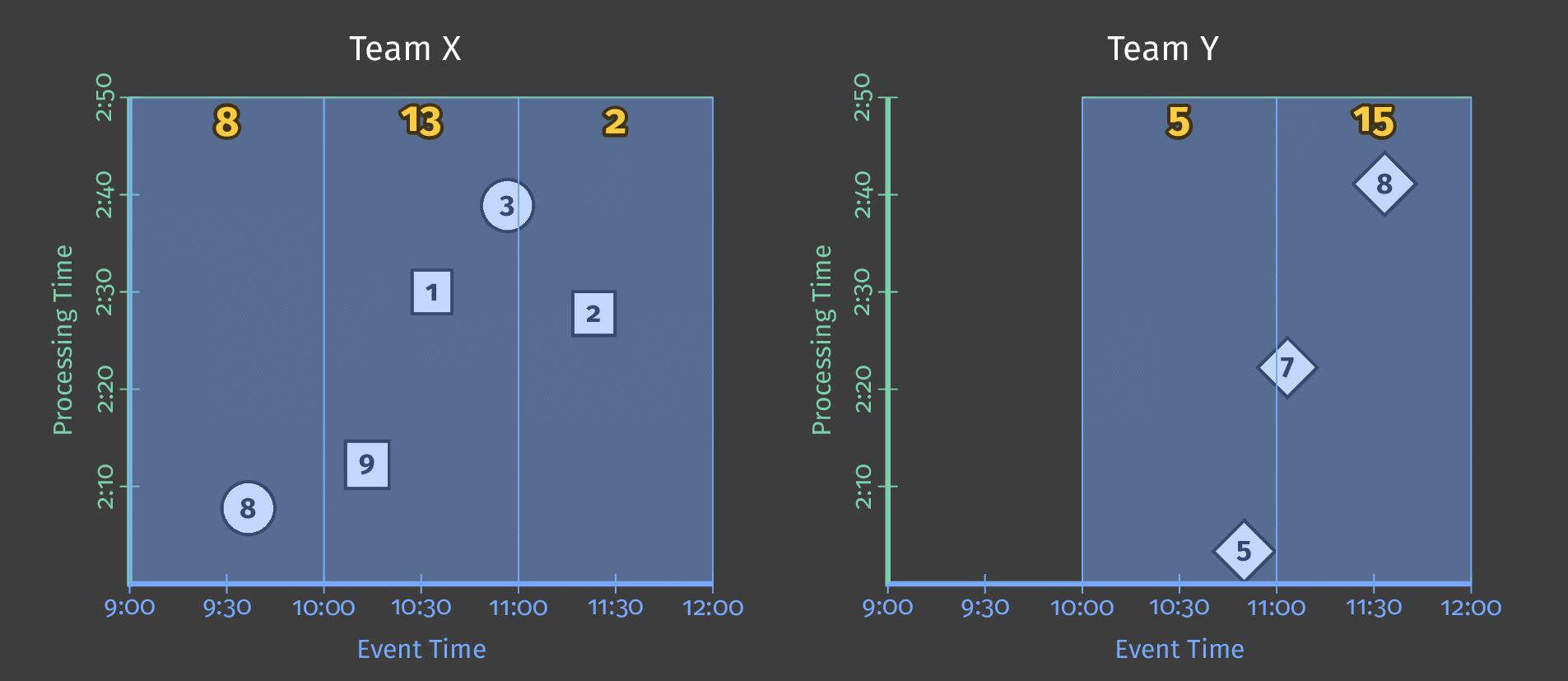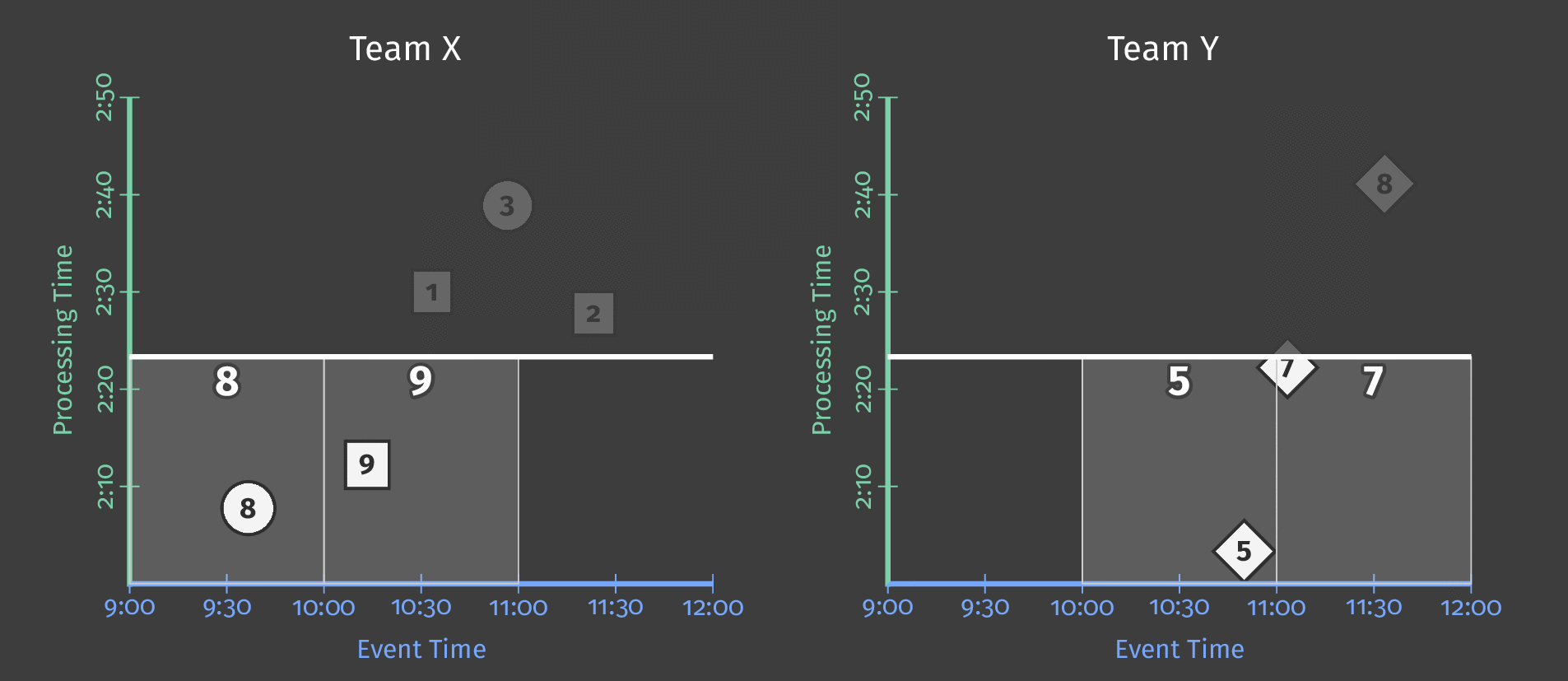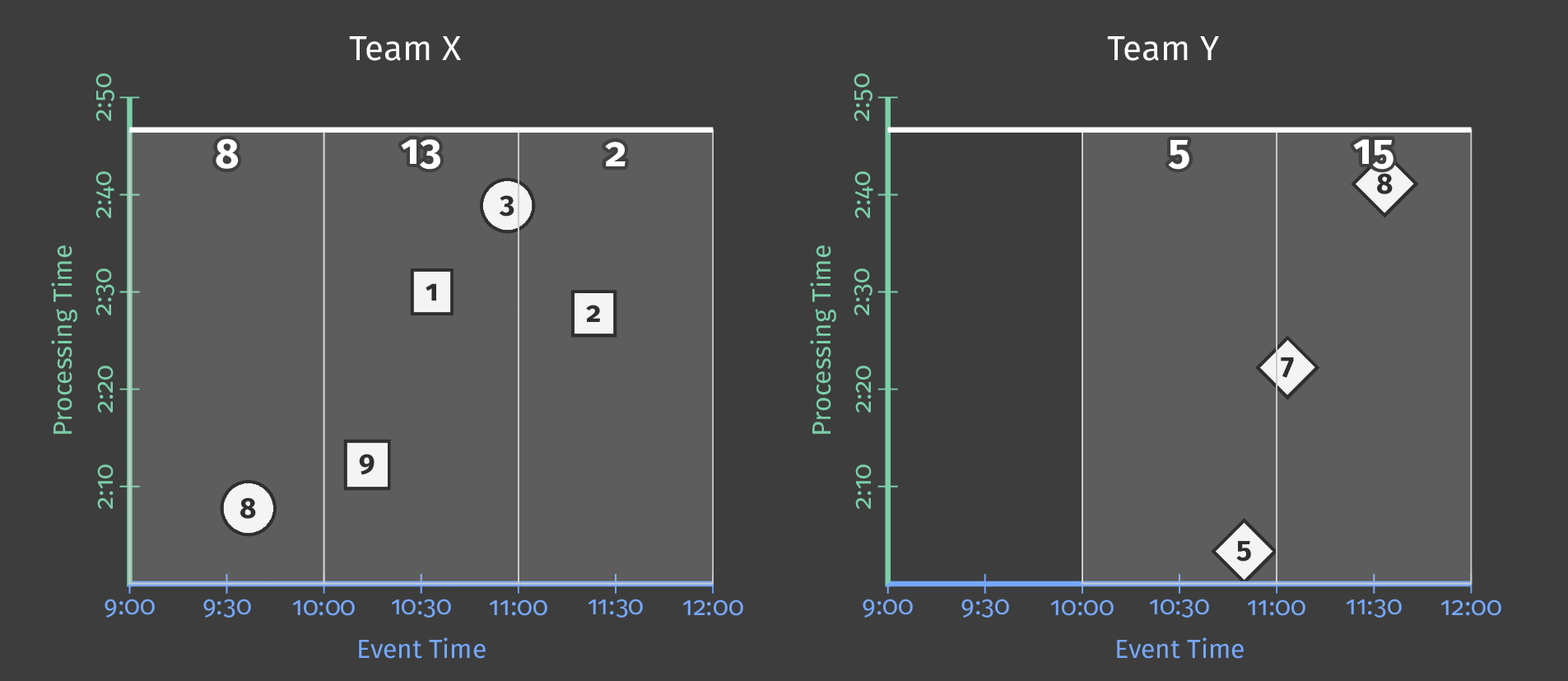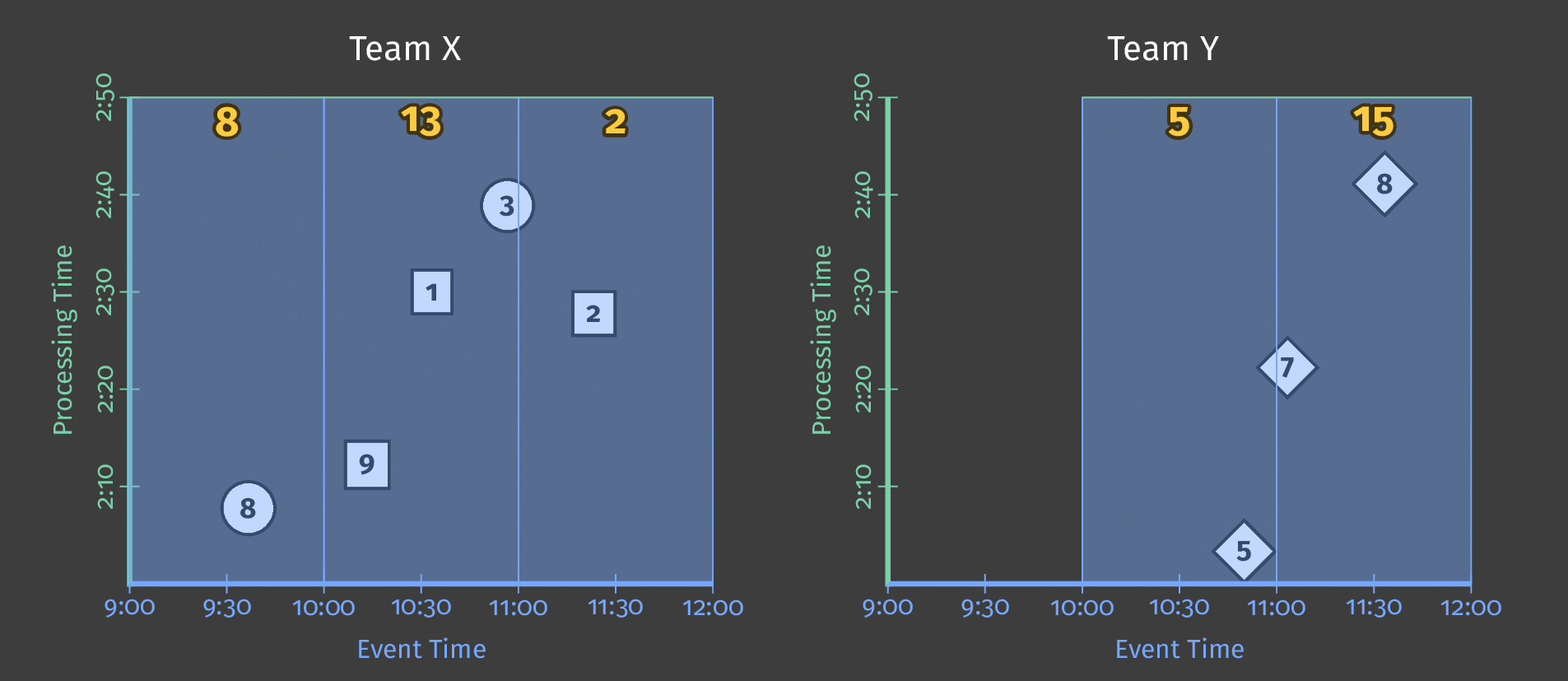
図3:2つのチームのスコアデータ。各チームのスコアは、それらのスコアが発生したイベント時間に基づいて論理的なウィンドウに分割されます。
処理時間が進むにつれて、合計値はウィンドウごとになります。各ウィンドウは、スコアが発生した1日中のイベント時間の1時間を表します。
注記:上記の図に示されているように、ウィンドウを使用すると、各間隔の独立した合計値(この場合は1時間ごと)が生成されます。
HourlyTeamScoreは、各時間におけるデータセット全体の累積合計を提供するのではなく、その時間内でのみ発生したすべてのイベントの合計スコアを提供します。
Beamのウィンドウ機能は、PCollectionの各要素に添付された固有のタイムスタンプ情報を使用します。パイプラインをイベント時間に基づいてウィンドウ化したいので、まず各データレコードに埋め込まれているタイムスタンプを抽出し、それをスコアデータのPCollection内の対応する要素に適用する必要があります。その後、パイプラインはウィンドウ化関数を適用してPCollectionを論理的なウィンドウに分割できます。
HourlyTeamScoreは、WithTimestampsとWindowトランスフォームを使用してこれらの操作を実行します。
HourlyTeamScoreは、window.pyにあるFixedWindowsトランスフォームを使用してこれらの操作を実行します。
次のコードはこれを示しています。
// Add an element timestamp based on the event log, and apply fixed windowing.
.apply(
"AddEventTimestamps",
WithTimestamps.of((GameActionInfo i) -> new Instant(i.getTimestamp())))
.apply(
"FixedWindowsTeam",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowDuration()))))# Add an element timestamp based on the event log, and apply fixed
# windowing.
| 'AddEventTimestamps' >> beam.Map(
lambda elem: beam.window.TimestampedValue(elem, elem['timestamp']))
| 'FixedWindowsTeam' >> beam.WindowInto(
beam.window.FixedWindows(self.window_duration_in_seconds))パイプラインがウィンドウ化を指定するために使用するトランスフォームは、実際のデータ処理トランスフォーム(ExtractAndSumScoresなど)とは別であることに注意してください。この機能により、Beamパイプラインの設計に柔軟性があり、異なるウィンドウ化特性を持つデータセットに対して既存のトランスフォームを実行できます。
イベント時間に基づくフィルタリング
HourlyTeamScoreは、フィルタリングを使用して、タイムスタンプが関連する分析期間内(つまり、興味のある日に生成されていない)にないデータセットのイベントを削除します。これにより、たとえば、前日にオフラインで生成されたが、当日にゲームサーバーに送信されたデータが誤って含まれるのを防ぎます。
また、パイプラインは関連する遅延データ(有効なタイムスタンプを持つデータイベントだが、分析期間の終了後に到着したもの)を含めることができます。たとえば、パイプラインのカットオフ時間が午前12時の場合、午前2時にパイプラインを実行する可能性がありますが、タイムスタンプが午前12時のカットオフ後であることを示すイベントはフィルタリングします。遅延して午前12時1分から午前2時の間に到着しましたが、タイムスタンプが午前12時のカットオフ前に発生したことを示すデータイベントは、パイプライン処理に含まれます。
HourlyTeamScoreはこの操作を実行するためにFilterトランスフォームを使用します。Filterを適用する際には、各データレコードが比較される述語を指定します。比較に合格したデータレコードは含まれ、比較に失敗したイベントは除外されます。私たちの場合、述語は指定したカットオフ時間であり、データの一部であるタイムスタンプフィールドのみを比較します。
次のコードは、HourlyTeamScoreがFilterトランスフォームを使用して、関連する分析期間の前または後に発生するイベントをフィルタリングする方法を示しています。
.apply(
"FilterStartTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() > startMinTimestamp.getMillis()))
.apply(
"FilterEndTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() < stopMinTimestamp.getMillis()))| 'FilterStartTime' >>
beam.Filter(lambda elem: elem['timestamp'] > self.start_timestamp)
| 'FilterEndTime' >>
beam.Filter(lambda elem: elem['timestamp'] < self.stop_timestamp)ウィンドウごとのチームごとのスコアの計算
HourlyTeamScoreは、UserScoreパイプラインと同じExtractAndSumScoresトランスフォームを使用しますが、異なるキー(ユーザーではなくチーム)を渡します。また、パイプラインは入力データに固定時間1時間ウィンドウを適用した後にExtractAndSumScoresを適用するため、データはチームとウィンドウの両方でグループ化されます。HourlyTeamScoreのメインメソッドでは、トランスフォームの完全なシーケンスを確認できます。
public static void main(String[] args) throws Exception {
// Begin constructing a pipeline configured by commandline flags.
Options options = PipelineOptionsFactory.fromArgs(args).withValidation().as(Options.class);
Pipeline pipeline = Pipeline.create(options);
final Instant stopMinTimestamp = new Instant(minFmt.parseMillis(options.getStopMin()));
final Instant startMinTimestamp = new Instant(minFmt.parseMillis(options.getStartMin()));
// Read 'gaming' events from a text file.
pipeline
.apply(TextIO.read().from(options.getInput()))
// Parse the incoming data.
.apply("ParseGameEvent", ParDo.of(new ParseEventFn()))
// Filter out data before and after the given times so that it is not included
// in the calculations. As we collect data in batches (say, by day), the batch for the day
// that we want to analyze could potentially include some late-arriving data from the
// previous day.
// If so, we want to weed it out. Similarly, if we include data from the following day
// (to scoop up late-arriving events from the day we're analyzing), we need to weed out
// events that fall after the time period we want to analyze.
// [START DocInclude_HTSFilters]
.apply(
"FilterStartTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() > startMinTimestamp.getMillis()))
.apply(
"FilterEndTime",
Filter.by(
(GameActionInfo gInfo) -> gInfo.getTimestamp() < stopMinTimestamp.getMillis()))
// [END DocInclude_HTSFilters]
// [START DocInclude_HTSAddTsAndWindow]
// Add an element timestamp based on the event log, and apply fixed windowing.
.apply(
"AddEventTimestamps",
WithTimestamps.of((GameActionInfo i) -> new Instant(i.getTimestamp())))
.apply(
"FixedWindowsTeam",
Window.into(FixedWindows.of(Duration.standardMinutes(options.getWindowDuration()))))
// [END DocInclude_HTSAddTsAndWindow]
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))
.apply(
"WriteTeamScoreSums", new WriteToText<>(options.getOutput(), configureOutput(), true));
pipeline.run().waitUntilFinish();
}class HourlyTeamScore(beam.PTransform):
def __init__(self, start_min, stop_min, window_duration):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.start_timestamp = str2timestamp(start_min)
self.stop_timestamp = str2timestamp(stop_min)
self.window_duration_in_seconds = window_duration * 60
def expand(self, pcoll):
return (
pcoll
| 'ParseGameEventFn' >> beam.ParDo(ParseGameEventFn())
# Filter out data before and after the given times so that it is not
# included in the calculations. As we collect data in batches (say, by
# day), the batch for the day that we want to analyze could potentially
# include some late-arriving data from the previous day. If so, we want
# to weed it out. Similarly, if we include data from the following day
# (to scoop up late-arriving events from the day we're analyzing), we
# need to weed out events that fall after the time period we want to
# analyze.
# [START filter_by_time_range]
| 'FilterStartTime' >>
beam.Filter(lambda elem: elem['timestamp'] > self.start_timestamp)
| 'FilterEndTime' >>
beam.Filter(lambda elem: elem['timestamp'] < self.stop_timestamp)
# [END filter_by_time_range]
# [START add_timestamp_and_window]
# Add an element timestamp based on the event log, and apply fixed
# windowing.
| 'AddEventTimestamps' >> beam.Map(
lambda elem: beam.window.TimestampedValue(elem, elem['timestamp']))
| 'FixedWindowsTeam' >> beam.WindowInto(
beam.window.FixedWindows(self.window_duration_in_seconds))
# [END add_timestamp_and_window]
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team'))
def run(argv=None, save_main_session=True):
"""Main entry point; defines and runs the hourly_team_score pipeline."""
parser = argparse.ArgumentParser()
# The default maps to two large Google Cloud Storage files (each ~12GB)
# holding two subsequent day's worth (roughly) of data.
parser.add_argument(
'--input',
type=str,
default='gs://apache-beam-samples/game/gaming_data*.csv',
help='Path to the data file(s) containing game data.')
parser.add_argument(
'--dataset',
type=str,
required=True,
help='BigQuery Dataset to write tables to. '
'Must already exist.')
parser.add_argument(
'--table_name',
default='leader_board',
help='The BigQuery table name. Should not already exist.')
parser.add_argument(
'--window_duration',
type=int,
default=60,
help='Numeric value of fixed window duration, in minutes')
parser.add_argument(
'--start_min',
type=str,
default='1970-01-01-00-00',
help='String representation of the first minute after '
'which to generate results in the format: '
'yyyy-MM-dd-HH-mm. Any input data timestamped '
'prior to that minute won\'t be included in the '
'sums.')
parser.add_argument(
'--stop_min',
type=str,
default='2100-01-01-00-00',
help='String representation of the first minute for '
'which to generate results in the format: '
'yyyy-MM-dd-HH-mm. Any input data timestamped '
'after to that minute won\'t be included in the '
'sums.')
args, pipeline_args = parser.parse_known_args(argv)
options = PipelineOptions(pipeline_args)
# We also require the --project option to access --dataset
if options.view_as(GoogleCloudOptions).project is None:
parser.print_usage()
print(sys.argv[0] + ': error: argument --project is required')
sys.exit(1)
# We use the save_main_session option because one or more DoFn's in this
# workflow rely on global context (e.g., a module imported at module level).
options.view_as(SetupOptions).save_main_session = save_main_session
with beam.Pipeline(options=options) as p:
( # pylint: disable=expression-not-assigned
p
| 'ReadInputText' >> beam.io.ReadFromText(args.input)
| 'HourlyTeamScore' >> HourlyTeamScore(
args.start_min, args.stop_min, args.window_duration)
| 'TeamScoresDict' >> beam.ParDo(TeamScoresDict())
| 'WriteTeamScoreSums' >> WriteToBigQuery(
args.table_name,
args.dataset,
{
'team': 'STRING',
'total_score': 'INTEGER',
'window_start': 'STRING',
},
options.view_as(GoogleCloudOptions).project))制限事項
記述されているように、HourlyTeamScoreはまだ制限があります。
HourlyTeamScoreは、バッチパイプラインとして、すべてのデータイベントが存在するまで処理を開始する必要があるため、データイベントが発生する時点(イベント時間)と結果が生成される時点(処理時間)との間に依然として高いレイテンシがあります。
LeaderBoard:リアルタイムゲームデータによるストリーミング処理
UserScoreおよびHourlyTeamScoreパイプラインに存在するレイテンシの問題に対処する1つの方法は、無制限のソースからスコアデータを読み取ることです。LeaderBoardパイプラインは、ゲームサーバー上のファイルではなく、無限の量のデータを生成する無制限のソースからゲームスコアデータを読み取ることで、ストリーミング処理を導入します。
LeaderBoardパイプラインは、処理時間とイベント時間の両方の観点からゲームスコアデータを処理する方法も示しています。LeaderBoardは、個々のユーザーのスコアとチームのスコアの両方に関するデータを、それぞれ異なる時間枠に関して出力します。
LeaderBoardパイプラインは、データが生成されると同時に無制限のソースからゲームデータを読み取るため、パイプラインはゲームプロセスと同時に実行される継続的なジョブとして考えることができます。したがって、LeaderBoardは、ユーザーがゲームをプレイしている方法に関する低レイテンシの洞察を提供できます。たとえば、ユーザーがプレイしながら他のユーザーとの進捗状況を追跡できるように、ライブのWebベースのスコアボードを提供する場合に役立ちます。
注記:完全な例となるパイプラインプログラムについては、GitHubのLeaderBoardを参照してください。
注記:完全な例となるパイプラインプログラムについては、GitHubのLeaderBoardを参照してください。
LeaderBoardは何をするのか?
LeaderBoardパイプラインは、ほぼリアルタイムで無限の量のデータを生成する無制限のソースに公開されたゲームデータを読み取り、そのデータを使用して2つの別々の処理タスクを実行します。
LeaderBoardは、一意のユーザーごとに合計スコアを計算し、処理時間の10分ごとに推測結果を公開します。つまり、データを受信してから10分後、パイプラインは現在までに処理したユーザーごとの合計スコアを出力します。この計算により、実際のゲームイベントがいつ生成されたかに関係なく、ほぼリアルタイムで実行中の「リーダーボード」を提供します。LeaderBoardは、パイプラインが実行される各時間ごとにチームのスコアを計算します。これは、たとえば、プレイ時間の各時間ごとに最高得点のチームに報酬を与えたい場合に役立ちます。チームスコアの計算では、固定時間ウィンドウを使用して、データがパイプラインに到着する際に、イベント時間(タイムスタンプで示される)に基づいて入力データを1時間の長さの有限ウィンドウに分割します。さらに、チームスコアの計算では、Beamのトリガーメカニズムを使用して、各時間ごとに推測結果を提供し(時間が経過するまで5分ごとに更新)、遅延データを取得して、それに属する特定の1時間の長さのウィンドウに追加します。
以下では、これらのタスクの両方を詳しく見ていきます。
処理時間に基づくユーザースコアの計算
パイプラインは、処理時間の10分ごとに、各ユーザーの累積合計スコアを出力する必要があります。この計算では、ユーザーのプレイインスタンスによって実際のスコアがいつ生成されたかは考慮されません。単に、現在までにパイプラインに到着したそのユーザーのすべてのスコアの合計を出力します。遅延データは、パイプラインの実行中に到着するたびに計算に含まれます。
計算を更新するたびにパイプラインに到着したすべてのデータが必要なため、単一のグローバルウィンドウでユーザーのスコアデータすべてをパイプラインで考慮しています。単一のグローバルウィンドウは無制限ですが、処理時間トリガーを使用することで、10分ごとの計算ごとに一時的なカットオフポイントを指定できます。
単一のグローバルウィンドウに10分間の処理時間トリガーを指定すると、トリガーが起動されるたびに、パイプラインはウィンドウの内容の「スナップショット」を効果的に取得します。このスナップショットは、データ受信から10分経過後に発生します。データが到着しなかった場合、パイプラインは要素が到着してから10分後に次の「スナップショット」を取得します。単一のグローバルウィンドウを使用しているため、各スナップショットにはその時点までに収集されたすべてのデータが含まれています。次の図は、単一のグローバルウィンドウに対する処理時間トリガーの使用効果を示しています。
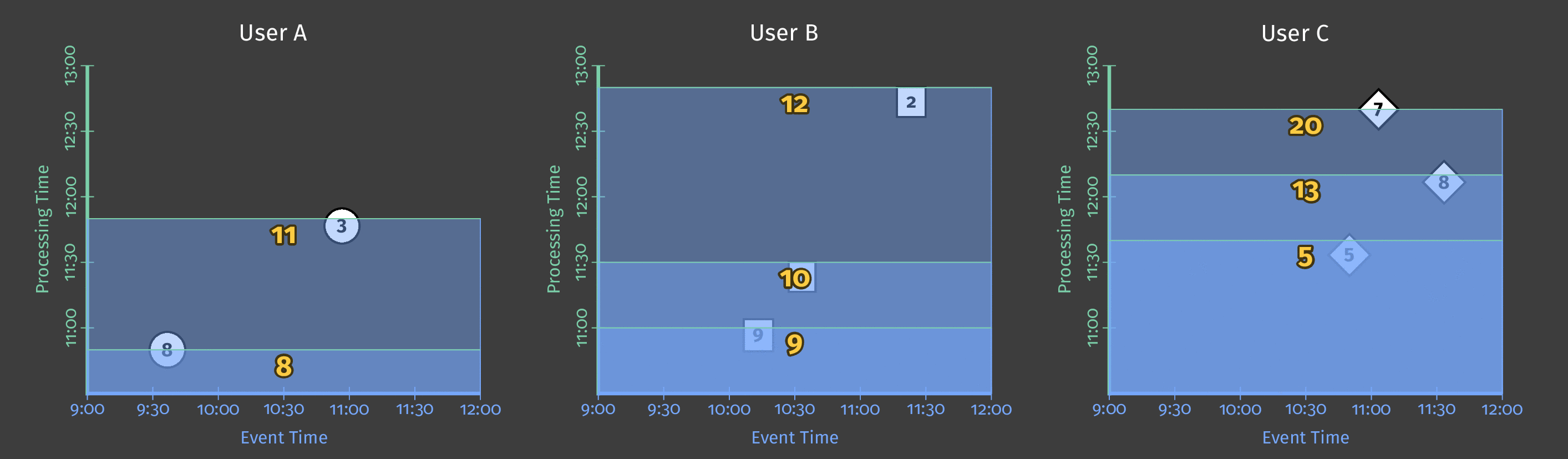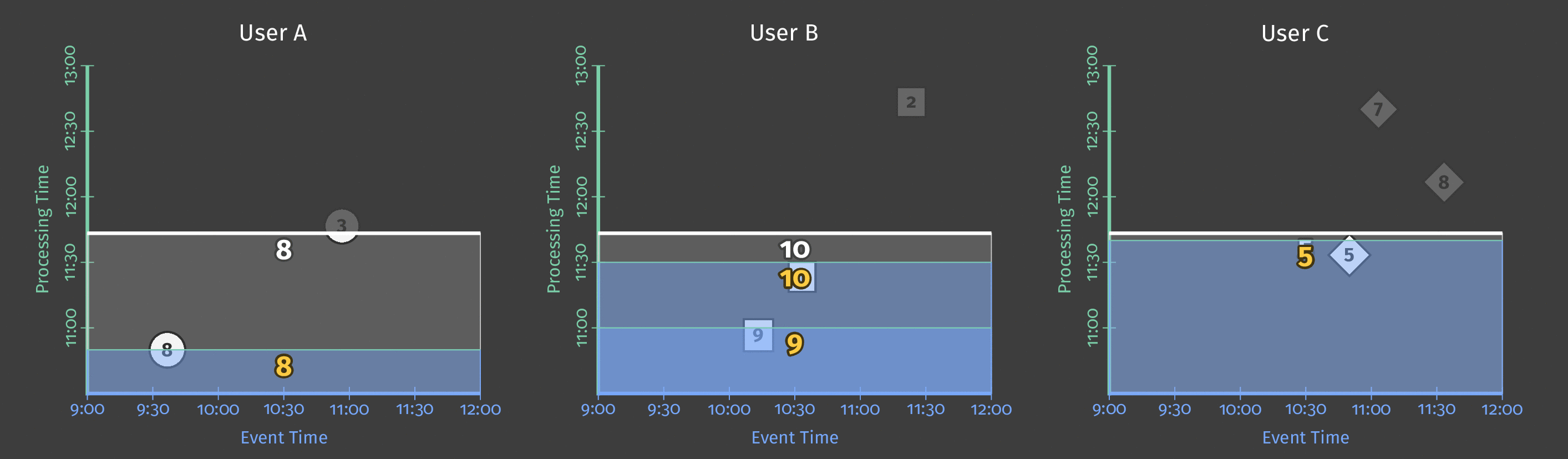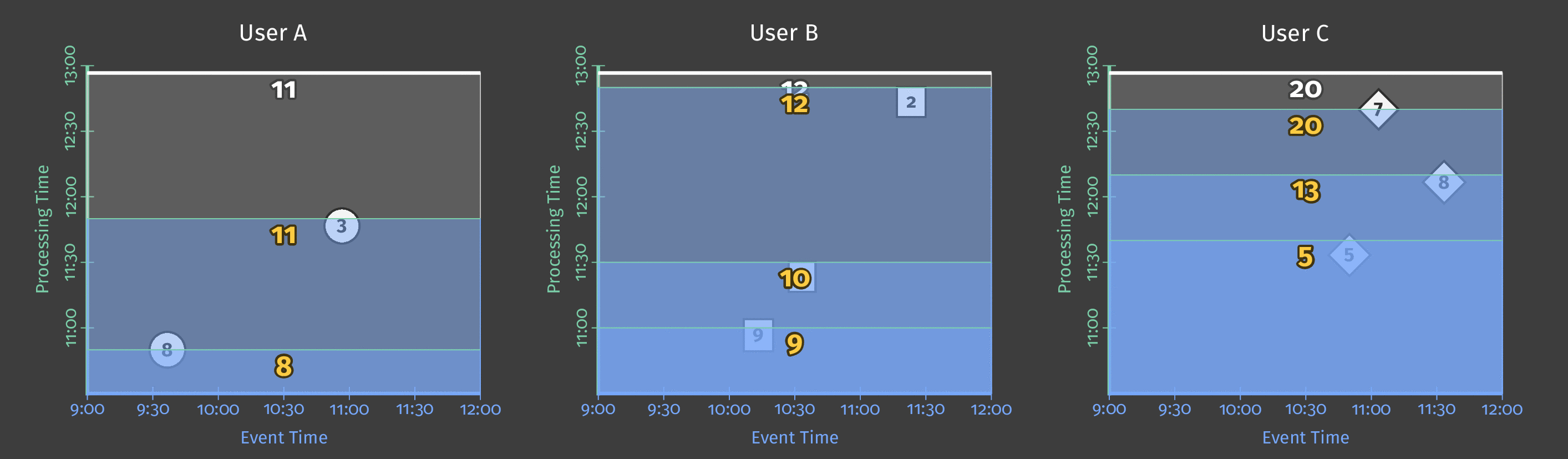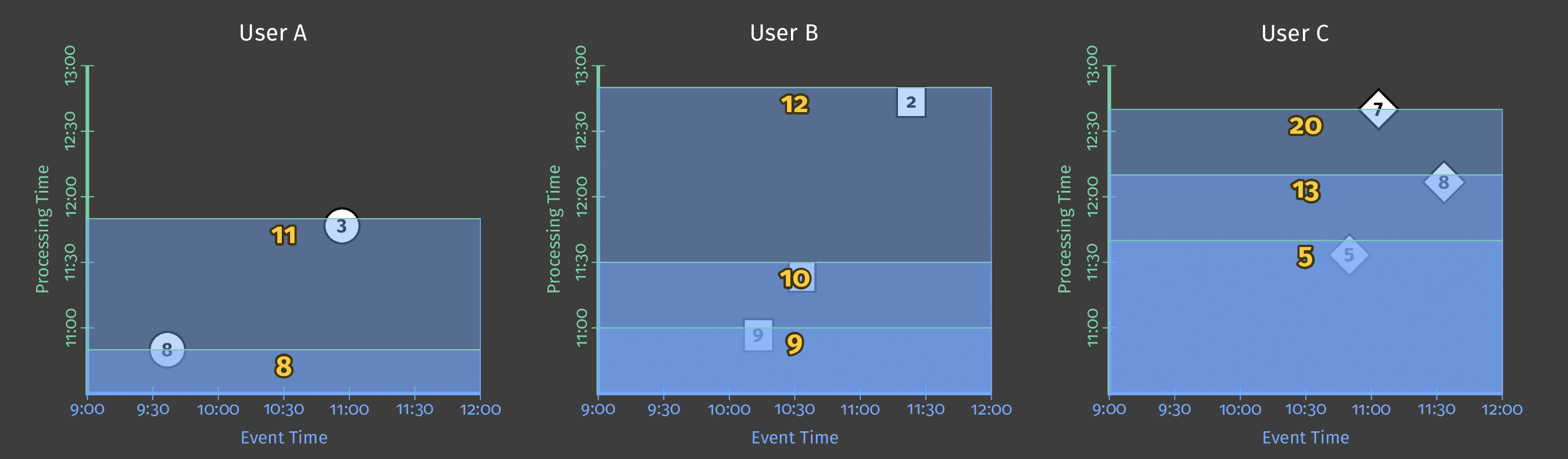
図4:3人のユーザーのスコアデータ。各ユーザーのスコアは、データ受信後10分後にスナップショットを出力するトリガーを使用して、単一のグローバルウィンドウにグループ化されています。
処理時間が進み、より多くのスコアが処理されると、トリガーは各ユーザーの更新された合計を出力します。
次のコード例は、LeaderBoardが処理時間トリガーを設定してユーザースコアのデータを出力する方法を示しています。
/**
* Extract user/score pairs from the event stream using processing time, via global windowing. Get
* periodic updates on all users' running scores.
*/
@VisibleForTesting
static class CalculateUserScores
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final Duration allowedLateness;
CalculateUserScores(Duration allowedLateness) {
this.allowedLateness = allowedLateness;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> input) {
return input
.apply(
"LeaderboardUserGlobalWindow",
Window.<GameActionInfo>into(new GlobalWindows())
// Get periodic results every ten minutes.
.triggering(
Repeatedly.forever(
AfterProcessingTime.pastFirstElementInPane().plusDelayOf(TEN_MINUTES)))
.accumulatingFiredPanes()
.withAllowedLateness(allowedLateness))
// Extract and sum username/score pairs from the event data.
.apply("ExtractUserScore", new ExtractAndSumScore("user"));
}
}class CalculateUserScores(beam.PTransform):
"""Extract user/score pairs from the event stream using processing time, via
global windowing. Get periodic updates on all users' running scores.
"""
def __init__(self, allowed_lateness):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.allowed_lateness_seconds = allowed_lateness * 60
def expand(self, pcoll):
# NOTE: the behavior does not exactly match the Java example
# TODO: allowed_lateness not implemented yet in FixedWindows
# TODO: AfterProcessingTime not implemented yet, replace AfterCount
return (
pcoll
# Get periodic results every ten events.
| 'LeaderboardUserGlobalWindows' >> beam.WindowInto(
beam.window.GlobalWindows(),
trigger=trigger.Repeatedly(trigger.AfterCount(10)),
accumulation_mode=trigger.AccumulationMode.ACCUMULATING)
# Extract and sum username/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('user'))LeaderBoardはウィンドウの累積モードを、トリガーが起動されたときにウィンドウペインを累積するように設定します。この累積モードは、トリガーの設定時に.accumulatingFiredPanesを呼び出すaccumulation_mode=trigger.AccumulationMode.ACCUMULATINGを使用することで設定され、パイプラインは以前に出力されたデータと、前回のトリガー起動以降に到着した新しいデータをまとめて累積します。これにより、LeaderBoardは個々の合計の集合ではなく、ユーザースコアの累積合計になります。
イベント時間に基づくチームスコアの計算
パイプラインは、プレイ時間ごとにチームごとの合計スコアも出力する必要があります。ユーザーのスコア計算とは異なり、チームのスコアについては、各スコアが実際に発生したイベント時間が重要です。各プレイ時間を個別に考慮する必要があるためです。また、各時間が経過するにつれて推測的な更新を提供し、遅延データ(特定の時間のデータが完了していると見なされた後も到着するデータ)を計算に含めることができます。
各時間を個別に考慮するため、HourlyTeamScoreと同様に、入力データに固定時間ウィンドウ処理を適用できます。推測的な更新と遅延データの更新を提供するために、追加のトリガーパラメーターを指定します。トリガーにより、各ウィンドウは指定された間隔(この場合は5分ごと)で結果を計算して出力し、遅延データに対応するために、ウィンドウが「完了」と見なされた後もトリガーし続けます。ユーザーのスコア計算と同様に、トリガーを累積モードに設定して、1時間ごとのウィンドウの累積合計を取得します。
推測的な更新と遅延データのトリガーは、時間ずれの問題に対処するのに役立ちます。パイプラインのイベントは、タイムスタンプに従って実際に発生した順序で処理されるとは限りません。順序が間違っているか、遅れて到着することがあります(ユーザーの電話がネットワークと接続されていない間に生成された場合)。Beamは、特定のウィンドウに「すべて」のデータがあると合理的に想定できるときの決定方法が必要です。これはウォーターマークと呼ばれます。
理想的には、すべてのデータは発生時にすぐに処理されるため、処理時間はイベント時間と等しくなります(または少なくとも線形関係にあります)。ただし、分散システムには固有の不正確性(遅延報告の電話など)があるため、Beamは多くの場合、ヒューリスティックなウォーターマークを使用します。
次の図は、進行中の処理時間と2つのチームの各スコアのイベント時間の関係を示しています。
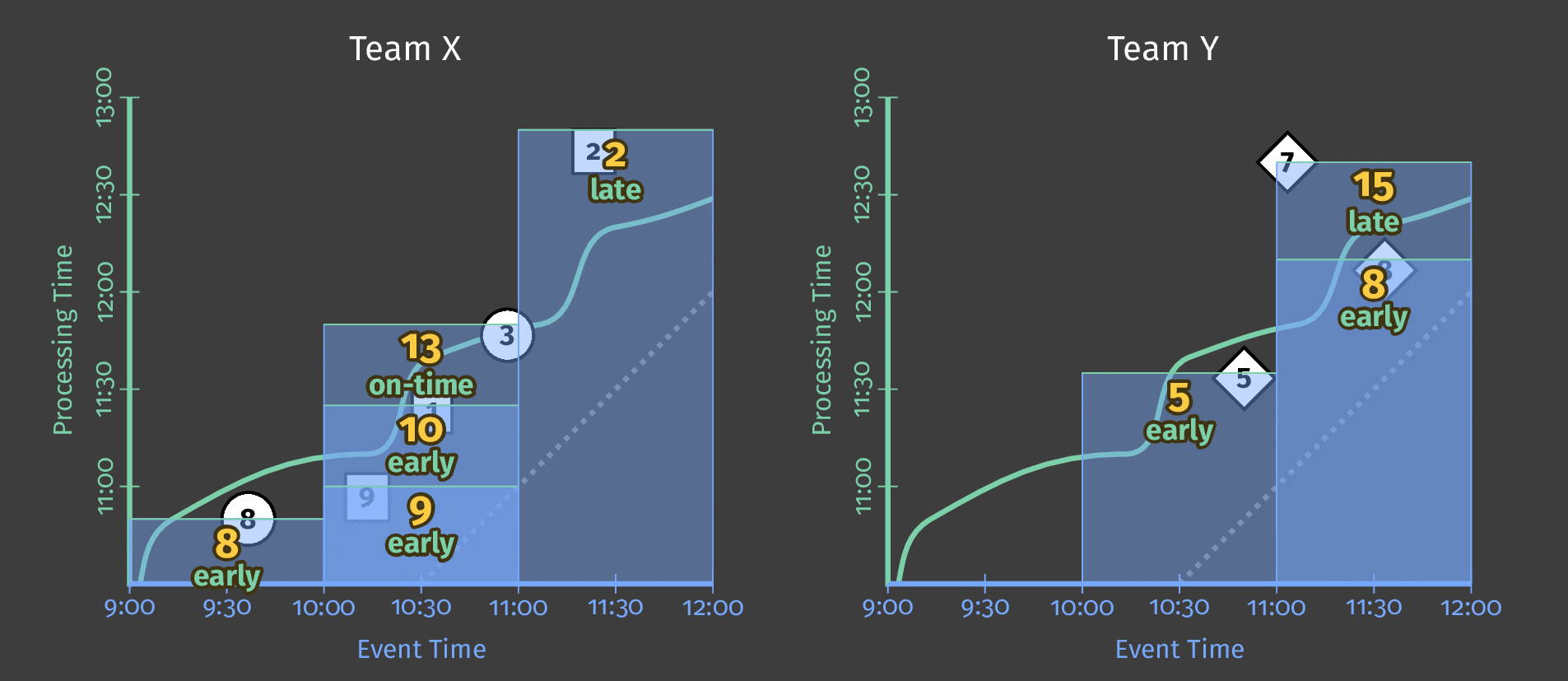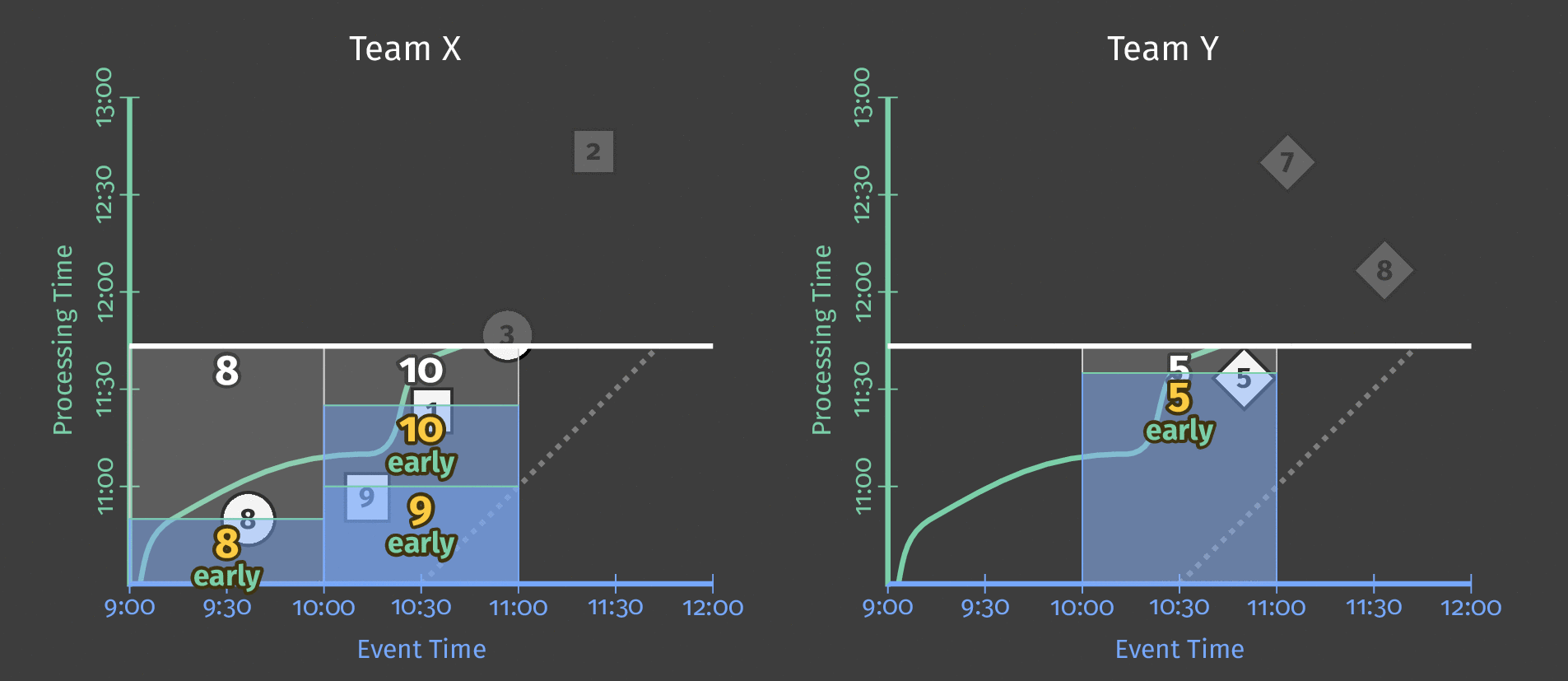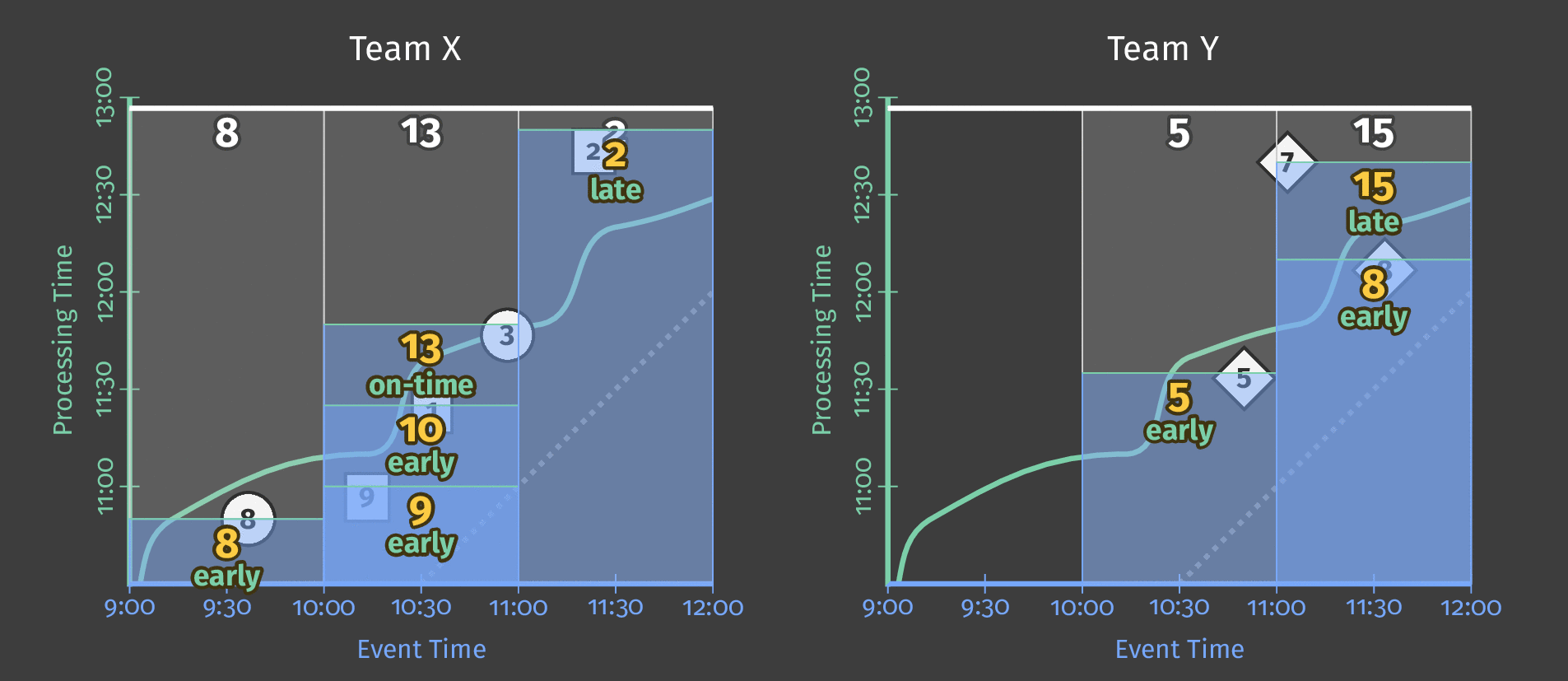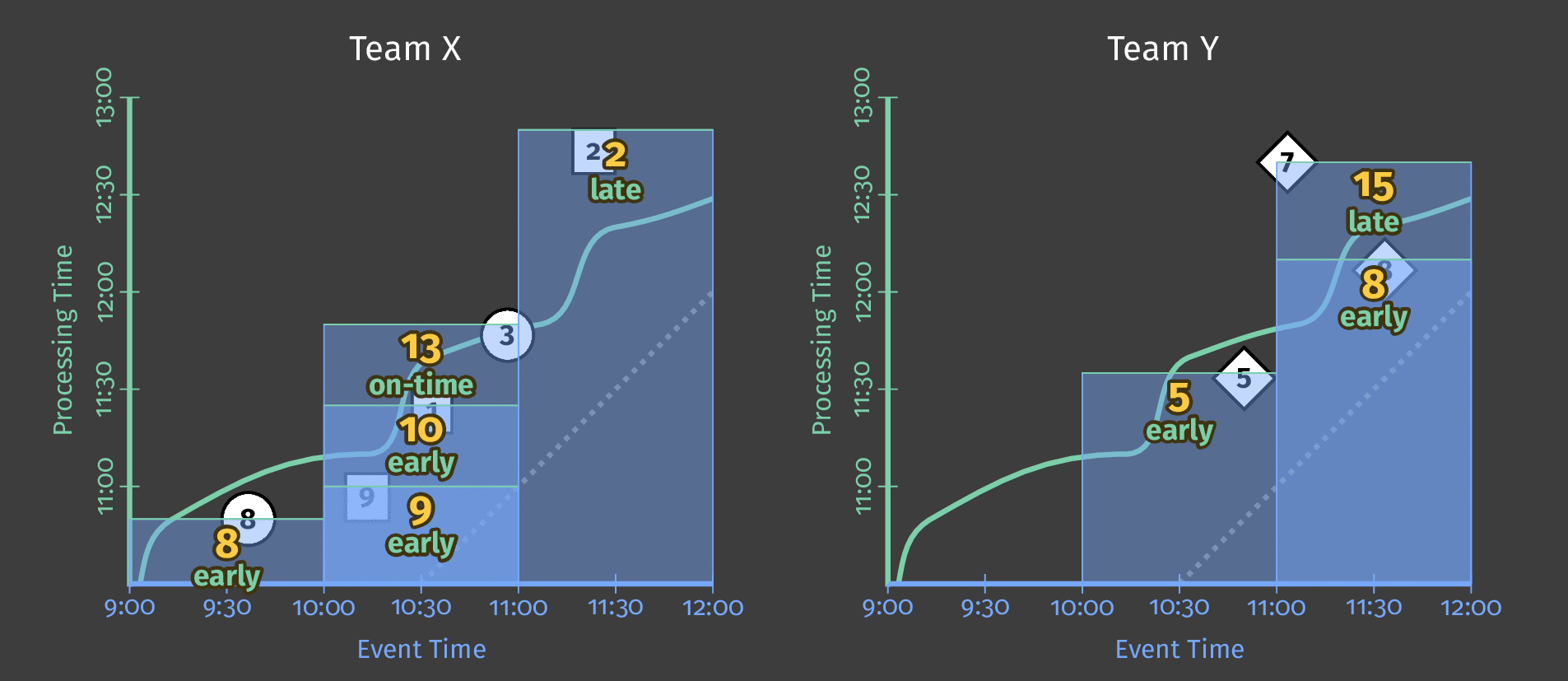
図5:チーム別のスコアデータ、イベント時間別にウィンドウ化されています。処理時間に基づくトリガーにより、ウィンドウは推測的な早期結果を出力し、遅延結果を含めます。
図の点線は、理想的なウォーターマークです。Beamは、特定のウィンドウ内のすべてのデータが合理的に到着したと見なせる時点の概念です。不規則な実線は、データソースによって決定された実際のウォーターマークを表しています。
実線ウォーターマークラインより上に到着するデータは遅延データです。これは、遅延した(オフラインで生成された可能性がある)スコアイベントであり、属するウィンドウが閉じられた後に到着したものです。パイプラインの遅延発火トリガーにより、この遅延データは合計に依然として含まれます。
次のコード例は、LeaderBoardが適切なトリガーを使用して固定時間ウィンドウ処理を適用し、パイプラインに必要な計算を実行する方法を示しています。
// Extract team/score pairs from the event stream, using hour-long windows by default.
@VisibleForTesting
static class CalculateTeamScores
extends PTransform<PCollection<GameActionInfo>, PCollection<KV<String, Integer>>> {
private final Duration teamWindowDuration;
private final Duration allowedLateness;
CalculateTeamScores(Duration teamWindowDuration, Duration allowedLateness) {
this.teamWindowDuration = teamWindowDuration;
this.allowedLateness = allowedLateness;
}
@Override
public PCollection<KV<String, Integer>> expand(PCollection<GameActionInfo> infos) {
return infos
.apply(
"LeaderboardTeamFixedWindows",
Window.<GameActionInfo>into(FixedWindows.of(teamWindowDuration))
// We will get early (speculative) results as well as cumulative
// processing of late data.
.triggering(
AfterWatermark.pastEndOfWindow()
.withEarlyFirings(
AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(FIVE_MINUTES))
.withLateFirings(
AfterProcessingTime.pastFirstElementInPane()
.plusDelayOf(TEN_MINUTES)))
.withAllowedLateness(allowedLateness)
.accumulatingFiredPanes())
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"));
}
}class CalculateTeamScores(beam.PTransform):
"""Calculates scores for each team within the configured window duration.
Extract team/score pairs from the event stream, using hour-long windows by
default.
"""
def __init__(self, team_window_duration, allowed_lateness):
# TODO(BEAM-6158): Revert the workaround once we can pickle super() on py3.
# super().__init__()
beam.PTransform.__init__(self)
self.team_window_duration = team_window_duration * 60
self.allowed_lateness_seconds = allowed_lateness * 60
def expand(self, pcoll):
# NOTE: the behavior does not exactly match the Java example
# TODO: allowed_lateness not implemented yet in FixedWindows
# TODO: AfterProcessingTime not implemented yet, replace AfterCount
return (
pcoll
# We will get early (speculative) results as well as cumulative
# processing of late data.
| 'LeaderboardTeamFixedWindows' >> beam.WindowInto(
beam.window.FixedWindows(self.team_window_duration),
trigger=trigger.AfterWatermark(
trigger.AfterCount(10), trigger.AfterCount(20)),
accumulation_mode=trigger.AccumulationMode.ACCUMULATING)
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team'))これらの処理戦略を組み合わせることで、UserScoreおよびHourlyTeamScoreパイプラインにあるレイテンシと完全性の問題に対処しながら、同じ基本的な変換を使用してデータを処理できます。実際、両方の計算では、UserScoreおよびHourlyTeamScoreパイプラインで使用したのと同じExtractAndSumScore変換を使用しています。
GameStats:不正検知と使用状況分析
LeaderBoardは、基本的なウィンドウ処理とトリガーを使用して低レイテンシで柔軟なデータ分析を実行する方法を示していますが、より高度なウィンドウ処理技術を使用して、より包括的な分析を実行できます。(スパムのような)システムの悪用を検出したり、ユーザーの行動に関する洞察を得たりするために設計された計算が含まれる場合があります。GameStatsパイプラインは、LeaderBoardの低レイテンシ機能に基づいて構築され、Beamを使用してこの種の高度な分析を実行する方法を示しています。
LeaderBoardと同様に、GameStatsは無制限のソースからデータを読み取ります。ユーザーがプレイするにつれてゲームに関する洞察を提供する継続的なジョブとして考えるのが最適です。
注記:完全な例となるパイプラインプログラムについては、GitHubのGameStatsを参照してください。
注記:完全な例となるパイプラインプログラムについては、GitHubのGameStatsを参照してください。
GameStatsは何をするのか?
LeaderBoardと同様に、GameStatsは時間ごとのチームごとの合計スコアを計算します。ただし、パイプラインは2種類のより複雑な分析も行います。
GameStatsは、スコアデータに対して簡単な統計分析を実行して、ユーザーのうちスパム送信者やボットの可能性があるユーザーを特定する悪用検出システムです。次に、疑わしいスパム/ボットユーザーのリストを使用して、チームリーダーボードの1時間ごとのチームスコア計算からボットを除外します。GameStatsは、セッションウィンドウ処理を使用して、類似したイベント時間を共有するゲームデータをグループ化することで使用パターンの分析を行います。これにより、ユーザーのプレイ時間の傾向や、時間の経過に伴うゲーム長の変化に関する情報を得ることができます。
以下では、これらの機能について詳しく見ていきます。
不正検知
ゲームのスコアは、ユーザーが電話で「クリック」する速度に依存するとします。GameStatsの悪用検出は、各ユーザーのスコアデータ分析を行い、ユーザーの「クリック率」が異常に高く、したがってスコアが異常に高いかどうかを検出します。これは、人間よりもはるかに速く動作するボットによってゲームがプレイされていることを示している可能性があります。
スコアが「異常に」高いかどうかを判断するために、GameStatsはその固定時間ウィンドウ内のすべてのスコアの平均を計算し、各個々のスコアを平均スコアに任意の重み係数(この場合は2.5)を掛けた値と比較します。したがって、平均の2.5倍を超えるスコアは、スパムの結果であると見なされます。GameStatsパイプラインは、「スパム」ユーザーのリストを追跡し、チームリーダーボードのチームスコア計算からそれらのユーザーを除外します。
平均はパイプラインデータに依存するため、平均を計算し、その計算されたデータを、重み付けされた値を超えるスコアをフィルタリングする後続のParDo変換で使用します。これを行うには、計算された平均をフィルタリングParDoのサイド入力として渡すことができます。
次のコード例は、悪用検出を処理する複合変換を示しています。この変換は、Sum.integersPerKey変換を使用してユーザーごとのすべてのスコアを合計し、Mean.globally変換を使用してすべてのユーザーの平均スコアを決定します。これが(PCollectionViewシングルトンとして)計算されると、.withSideInputsを使用してフィルタリングParDoに渡すことができます。
public static class CalculateSpammyUsers
extends PTransform<PCollection<KV<String, Integer>>, PCollection<KV<String, Integer>>> {
private static final Logger LOG = LoggerFactory.getLogger(CalculateSpammyUsers.class);
private static final double SCORE_WEIGHT = 2.5;
@Override
public PCollection<KV<String, Integer>> expand(PCollection<KV<String, Integer>> userScores) {
// Get the sum of scores for each user.
PCollection<KV<String, Integer>> sumScores =
userScores.apply("UserSum", Sum.integersPerKey());
// Extract the score from each element, and use it to find the global mean.
final PCollectionView<Double> globalMeanScore =
sumScores.apply(Values.create()).apply(Mean.<Integer>globally().asSingletonView());
// Filter the user sums using the global mean.
PCollection<KV<String, Integer>> filtered =
sumScores.apply(
"ProcessAndFilter",
ParDo
// use the derived mean total score as a side input
.of(
new DoFn<KV<String, Integer>, KV<String, Integer>>() {
private final Counter numSpammerUsers =
Metrics.counter("main", "SpammerUsers");
@ProcessElement
public void processElement(ProcessContext c) {
Integer score = c.element().getValue();
Double gmc = c.sideInput(globalMeanScore);
if (score > (gmc * SCORE_WEIGHT)) {
LOG.info(
"user "
+ c.element().getKey()
+ " spammer score "
+ score
+ " with mean "
+ gmc);
numSpammerUsers.inc();
c.output(c.element());
}
}
})
.withSideInputs(globalMeanScore));
return filtered;
}
}class CalculateSpammyUsers(beam.PTransform):
"""Filter out all but those users with a high clickrate, which we will
consider as 'spammy' users.
We do this by finding the mean total score per user, then using that
information as a side input to filter out all but those user scores that are
larger than (mean * SCORE_WEIGHT).
"""
SCORE_WEIGHT = 2.5
def expand(self, user_scores):
# Get the sum of scores for each user.
sum_scores = (user_scores | 'SumUsersScores' >> beam.CombinePerKey(sum))
# Extract the score from each element, and use it to find the global mean.
global_mean_score = (
sum_scores
| beam.Values()
| beam.CombineGlobally(beam.combiners.MeanCombineFn())\
.as_singleton_view())
# Filter the user sums using the global mean.
filtered = (
sum_scores
# Use the derived mean total score (global_mean_score) as a side input.
| 'ProcessAndFilter' >> beam.Filter(
lambda key_score, global_mean:\
key_score[1] > global_mean * self.SCORE_WEIGHT,
global_mean_score))
return filtered悪用検出変換は、スパムボットと疑われるユーザーのビューを生成します。パイプラインの後の方で、そのビューを使用して、スコアを固定ウィンドウにウィンドウ化し、チームスコアを抽出する際に、サイド入力メカニズムを使用してそのようなユーザーをフィルタリングします。
// Calculate the total score per team over fixed windows,
// and emit cumulative updates for late data. Uses the side input derived above-- the set of
// suspected robots-- to filter out scores from those users from the sum.
// Write the results to BigQuery.
rawEvents
.apply(
"WindowIntoFixedWindows",
Window.into(
FixedWindows.of(Duration.standardMinutes(options.getFixedWindowDuration()))))
// Filter out the detected spammer users, using the side input derived above.
.apply(
"FilterOutSpammers",
ParDo.of(
new DoFn<GameActionInfo, GameActionInfo>() {
@ProcessElement
public void processElement(ProcessContext c) {
// If the user is not in the spammers Map, output the data element.
if (c.sideInput(spammersView).get(c.element().getUser().trim()) == null) {
c.output(c.element());
}
}
})
.withSideInputs(spammersView))
// Extract and sum teamname/score pairs from the event data.
.apply("ExtractTeamScore", new ExtractAndSumScore("team"))# Calculate the total score per team over fixed windows, and emit cumulative
# updates for late data. Uses the side input derived above --the set of
# suspected robots-- to filter out scores from those users from the sum.
# Write the results to BigQuery.
( # pylint: disable=expression-not-assigned
raw_events
| 'WindowIntoFixedWindows' >> beam.WindowInto(
beam.window.FixedWindows(fixed_window_duration))
# Filter out the detected spammer users, using the side input derived
# above
| 'FilterOutSpammers' >> beam.Filter(
lambda elem, spammers: elem['user'] not in spammers, spammers_view)
# Extract and sum teamname/score pairs from the event data.
| 'ExtractAndSumScore' >> ExtractAndSumScore('team')使用パターンの分析
各ゲームスコアのイベント時間を調べ、類似したイベント時間を持つスコアをセッションにグループ化することで、ユーザーがいつ、どのくらいの時間ゲームをプレイしているかについての洞察を得ることができます。GameStatsは、Beamの組み込みセッションウィンドウ処理関数を使用して、発生時間に基づいてユーザーのスコアをセッションにグループ化します。
セッションウィンドウ処理を設定する場合、イベント間の最小ギャップ時間を指定します。到着時間が最小ギャップ時間よりも近いすべてのイベントは、同じウィンドウにグループ化されます。到着時間の差がギャップよりも大きいイベントは、別のウィンドウにグループ化されます。最小ギャップ時間をどのように設定するかによって、同じセッションウィンドウ内のスコアは、同じ(比較的)中断のないプレイの一部であると安全に想定できます。別のウィンドウ内のスコアは、ユーザーがゲームのプレイを少なくとも最小ギャップ時間停止してから後で再開したことを示します。
次の図は、セッションウィンドウにグループ化されたデータの例を示しています。固定ウィンドウとは異なり、セッションウィンドウはユーザーごとに異なります。これは、個々のユーザーのプレイパターンに依存します。
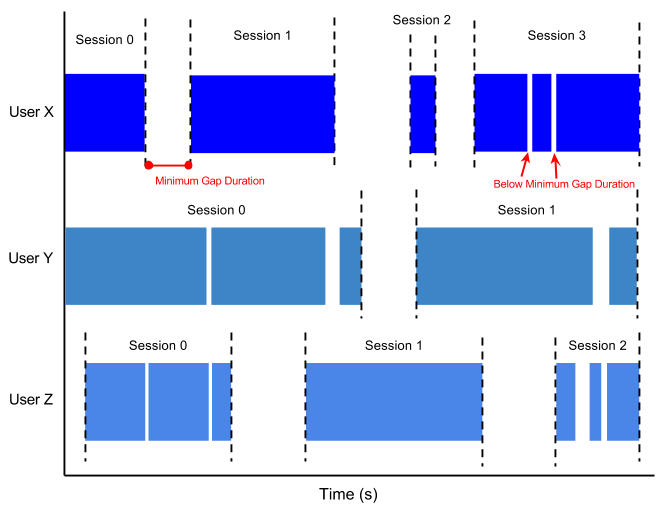
図6: 最小時間間隔のあるユーザーセッション。各ユーザーは、プレイした回数とプレイ間の休憩時間の長さによって、異なるセッションを持ちます。
セッションウィンドウ化されたデータを使用して、全ユーザーの途切れないプレイ時間の平均の長さ、および各セッションで達成した合計スコアを算出できます。コードでは、まずセッションウィンドウを適用し、ユーザーとセッションごとのスコアを合計してから、変換を使用して各セッションの長さを計算します。
// Detect user sessions-- that is, a burst of activity separated by a gap from further
// activity. Find and record the mean session lengths.
// This information could help the game designers track the changing user engagement
// as their set of games changes.
userEvents
.apply(
"WindowIntoSessions",
Window.<KV<String, Integer>>into(
Sessions.withGapDuration(Duration.standardMinutes(options.getSessionGap())))
.withTimestampCombiner(TimestampCombiner.END_OF_WINDOW))
// For this use, we care only about the existence of the session, not any particular
// information aggregated over it, so the following is an efficient way to do that.
.apply(Combine.perKey(x -> 0))
// Get the duration per session.
.apply("UserSessionActivity", ParDo.of(new UserSessionInfoFn()))# Detect user sessions-- that is, a burst of activity separated by a gap
# from further activity. Find and record the mean session lengths.
# This information could help the game designers track the changing user
# engagement as their set of game changes.
( # pylint: disable=expression-not-assigned
user_events
| 'WindowIntoSessions' >> beam.WindowInto(
beam.window.Sessions(session_gap),
timestamp_combiner=beam.window.TimestampCombiner.OUTPUT_AT_EOW)
# For this use, we care only about the existence of the session, not any
# particular information aggregated over it, so we can just group by key
# and assign a "dummy value" of None.
| beam.CombinePerKey(lambda _: None)
# Get the duration of the session
| 'UserSessionActivity' >> beam.ParDo(UserSessionActivity())これにより、それぞれに期間が添付されたユーザーセッションのセットが得られます。次に、データを固定時間ウィンドウに再ウィンドウ化し、各時間内に終了するすべてのセッションの平均を計算することで、平均セッション長を計算できます。
// Re-window to process groups of session sums according to when the sessions complete.
.apply(
"WindowToExtractSessionMean",
Window.into(
FixedWindows.of(Duration.standardMinutes(options.getUserActivityWindowDuration()))))
// Find the mean session duration in each window.
.apply(Mean.<Integer>globally().withoutDefaults())
// Write this info to a BigQuery table.
.apply(
"WriteAvgSessionLength",
new WriteWindowedToBigQuery<>(
options.as(GcpOptions.class).getProject(),
options.getDataset(),
options.getGameStatsTablePrefix() + "_sessions",
configureSessionWindowWrite()));# Re-window to process groups of session sums according to when the
# sessions complete
| 'WindowToExtractSessionMean' >> beam.WindowInto(
beam.window.FixedWindows(user_activity_window_duration))
# Find the mean session duration in each window
| beam.CombineGlobally(
beam.combiners.MeanCombineFn()).without_defaults()
| 'FormatAvgSessionLength' >>
beam.Map(lambda elem: {'mean_duration': float(elem)})
| 'WriteAvgSessionLength' >> WriteToBigQuery(
args.table_name + '_sessions',
args.dataset, {
'mean_duration': 'FLOAT',
},
options.view_as(GoogleCloudOptions).project))得られた情報を使用して、例えば、ユーザーが最も長くプレイしている時間帯、またはプレイセッションが短くなる可能性が高い時間帯を特定できます。
次のステップ
- 自己ペースで学習できる学習リソースをご覧ください。
- おすすめのビデオとポッドキャストをご覧ください。
- Beamのusers@メーリングリストにご参加ください。
問題が発生した場合は、お気軽にお問い合わせください!
最終更新日: 2024/10/31
お探しの情報はすべて見つかりましたか?
すべて役に立ち、分かりやすかったですか?変更してほしい点があれば教えてください!