



概要
Apache Beamを選ぶ理由
Apache Beamは、バッチとストリーミングのデータ処理パイプラインのためのオープンソースの統一プログラミングモデルであり、大規模なデータ処理のダイナミクスを簡素化します。世界中の数千もの組織が、その独自のデータ処理機能、実証済みのスケーラビリティ、そして強力で拡張可能な機能のためにApache Beamを選択しています。
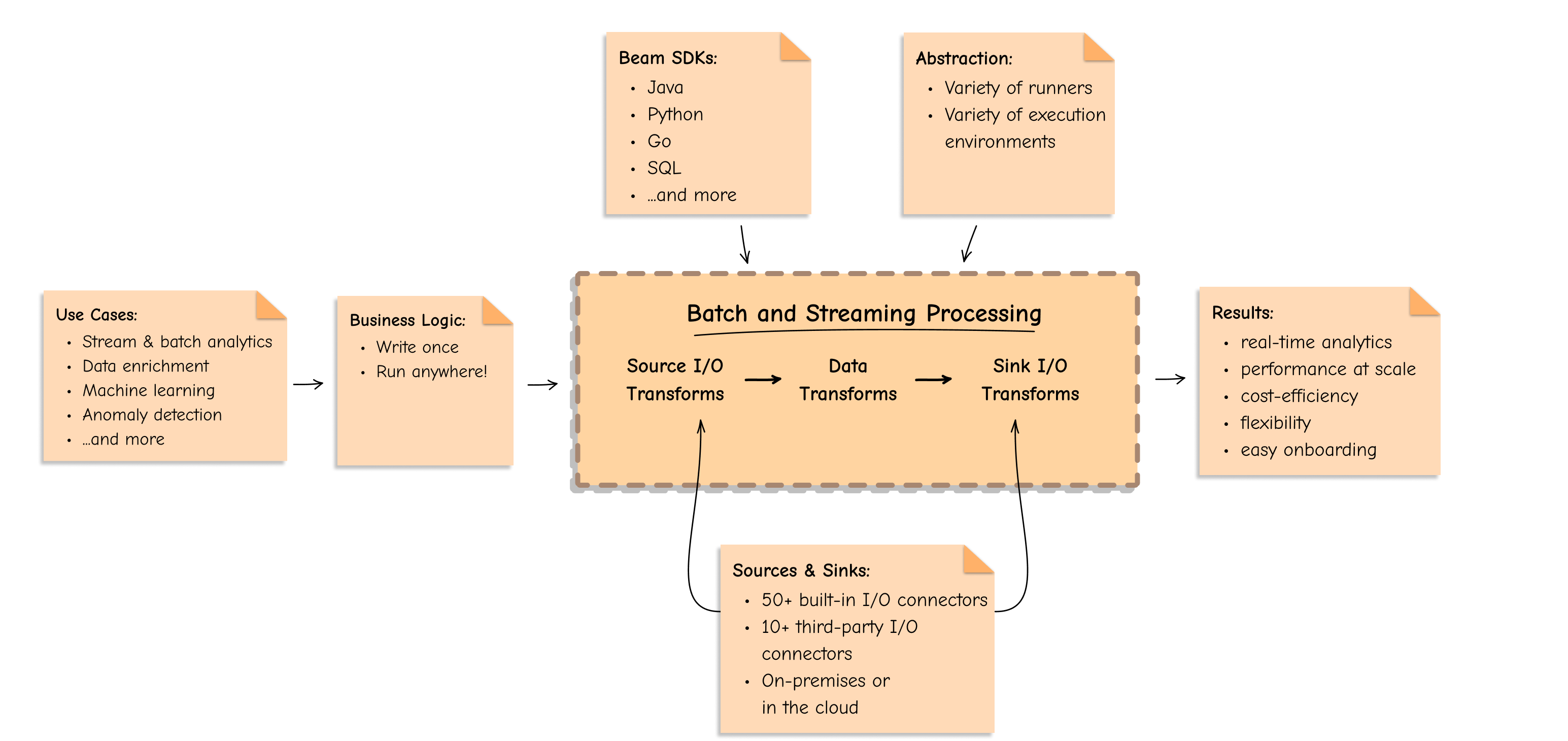
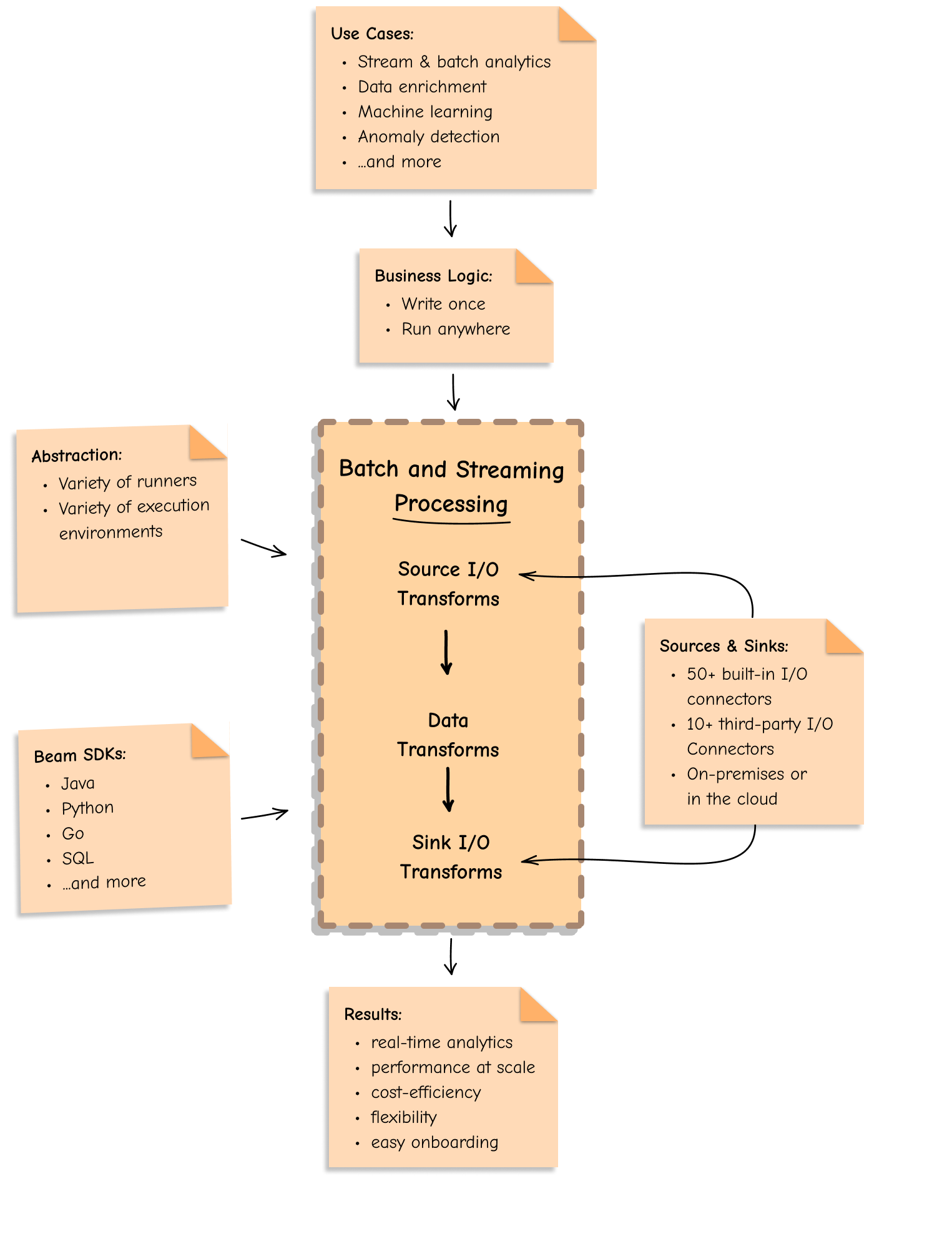
Apache Beamは、以下を提供するため、データ処理の未来です。
強力な抽象化
Apache Beamモデルは、個々のワーカーの調整、ソースからの読み取りとシンクへの書き込みなど、分散データ処理の低レベルの詳細からユーザーを保護する強力な抽象化を提供します。
パイプライン抽象化は、データ処理タスクのすべてのデータとステップをカプセル化します。これらの抽象化の観点からデータ処理タスクを検討できます。
高レベルの抽象化により、データとランタイム特性が明確に分離され、大規模な分散データ処理のメカニズムが簡素化されます。ユーザーは顧客とビジネスへの価値創造に集中でき、Dataflowモデルがその他を処理します。
バッチとストリーミングの統一プログラミングモデル
Apache Beamは、ビジネスロジックを一度だけ記述し、バッチとストリーミングの両方のデータパイプラインで実行する柔軟性を提供します。OSSランナーによるオンプレミス、またはGoogle Cloud DataflowやAWS Kinesis Data Analyticsなどのマネージドサービスによるクラウド上での実行が可能です。
Apache Beamは、独自のBeamモデルを中心に複数のデータ処理エンジンとSDKを統合します。これにより、データを使用するさまざまなアプリケーション全体で、大規模な共通データインフラストラクチャを簡単に作成する方法が提供されます。
クロス言語機能
さまざまな言語SDKからプログラミング言語を選択できます。Java、Python、Go、SQL、TypeScript、Scala(Scio経由)、または複数言語機能を活用して、すべてのチームメンバーが自分の好きなプログラミング言語で変換を記述し、それらを1つの堅牢な複数言語パイプラインで一緒に使用できるようにします。Apache Beamは、スキルセットの依存性を排除し、特定のテクノロジースキルセットとスタックに縛られるのを回避するのに役立ちます。
移植性
Apache Beamは、さまざまな実行エンジンを選択し、さまざまなランナー間を簡単に切り替え、ベンダーに依存しない状態を維持する自由を提供します。「一度記述してどこでも実行」するように構築されており、言語とランタイム環境(オープンソース(例:Apache FlinkとSpark)とプロプライエタリ(例:Google Cloud DataflowとAWS KDA))を問わず、移植可能なデータパイプラインを記述できます。
拡張性
Apache Beamはオープンソースで拡張可能です。TensorFlow ExtendedやApache Hopなどの複数のプロジェクトは、Apache Beam上に構築されており、「一度記述してどこでも実行」する機能を活用しています。
新しく出現する製品は、ユースケースの数を拡大し、Apache Beamユーザーに追加の付加価値を生み出します。
柔軟性
Apache Beamは、低レベルの詳細からユーザーを抽象化し、プログラミング言語の選択の自由を提供するため、採用と実装が容易です。
Apache Beamデータパイプラインは汎用的な変換で表現されるため、理解しやすく保守しやすいことから、Apache Beamの採用と新しいチームメンバーのオンボーディングが加速されます。
Apache Beamユーザーは、印象的な価値実現までの時間短縮を報告しています。特に、パイプラインの開発と展開に必要な時間が数日から数時間に短縮されたことに注目しています。
導入の容易さ
Apache Beamは、低レベルの詳細からユーザーを抽象化し、プログラミング言語の選択の自由を提供するため、採用と実装が容易です。
Apache Beamデータパイプラインは汎用的な変換で表現されるため、理解しやすく保守しやすいことから、Apache Beamの採用と新しいチームメンバーのオンボーディングが加速されます。Apache Beamユーザーは、印象的な価値実現までの時間短縮を報告しています。
特に、パイプラインの開発と展開に必要な時間が数日から数時間に短縮されたことに注目しています。
Apache Beamがカスタムユースケースを可能にし、さまざまな業界のリーダー企業のビッグデータエコシステムの複雑なビジネスロジックをオーケストレーションする方法の詳細については、事例スタディセクションをご覧ください。
Apache Beamプロジェクトについて
Apache Beamは、世界最大かつ最も歓迎的なオープンソースコミュニティであるApacheのトップレベルプロジェクトです。世界中のデータ処理のリーダーがApache Beamの開発に貢献し、次世代の分散データ処理と高度なテクノロジーソリューションを実現することに貢献しています。
Apache Beamは2016年初頭に、Googleとその他のパートナー(Cloud Dataflowの貢献者)がGoogle Cloud Dataflow SDKとランナーをApache Beamインキュベーターに移行するという決定をした際に設立されました。
2016年にリリースされたApache Beamは、バッチとストリーミングのパイプラインでビジネスロジックを表現し、統一されたエンジン非依存の実行を可能にする、すぐに利用でき、明確に定義された統一プログラミングモデルになっています。
Apache Beamのビジョンは、開発者がBeamモデル(=Dataflowモデル)に基づいてデータパイプラインを簡単に表現し、エンジンとプログラミング言語の選択の自由を持つことができるようにすることです。
Apache Beam統一プログラミングモデルは非常に急速に進化しており、ユースケース、ランナー、言語SDK、およびサポートされている組み込みおよびカスタムプラグ可能なI/O変換の数を継続的に拡大しています。
最終更新日:2024年10月31日
探していたものが見つかりましたか?
すべて役立ち、わかりやすかったですか?変更したいことはありますか?お知らせください!