



Apache Beamの概要
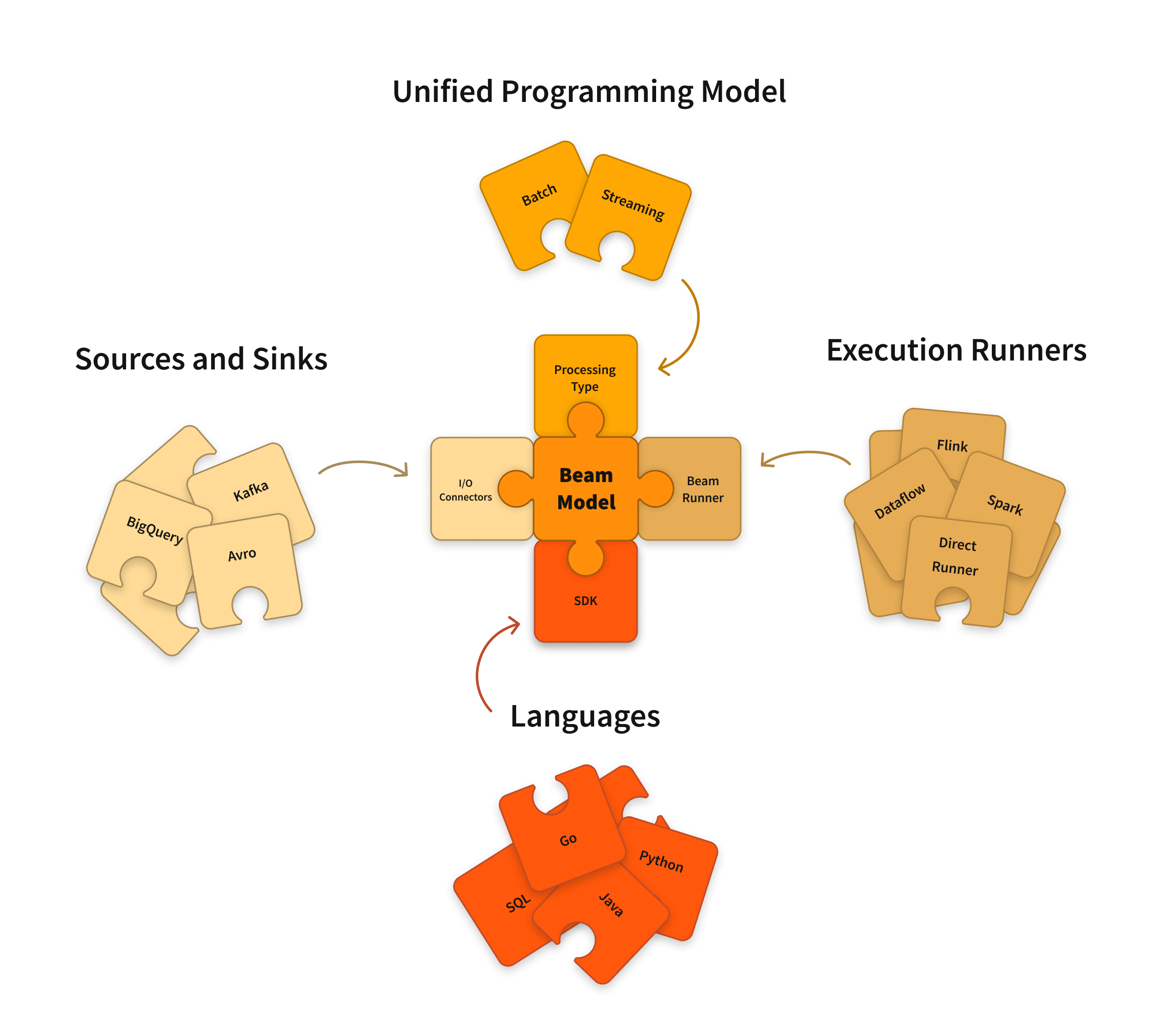
Apache Beamは、バッチとストリーミングの両方のデータ並列処理パイプラインを定義するためのオープンソースの統一モデルです。オープンソースのBeam SDKのいずれかを使用して、パイプラインを定義するプログラムを構築します。次に、パイプラインはBeamのサポートされている**分散処理バックエンド**のいずれかによって実行されます。これには、Apache Flink、Apache Spark、およびGoogle Cloud Dataflowが含まれます。
Beamは、問題を独立して並列に処理できる多くの小さなデータバンドルに分解できるため、容易に並列化できるデータ処理タスクに特に役立ちます。また、BeamをExtract、Transform、Load(ETL)タスクや純粋なデータ統合にも使用できます。これらのタスクは、異なるストレージメディアとデータソース間でデータの移動、データのより望ましい形式への変換、または新しいシステムへのデータのロードに役立ちます。
Apache Beam SDK
Beam SDKは、入力データがバッチデータソースからの有限データセットであるか、ストリーミングデータソースからの無限データセットであるかにかかわらず、任意のサイズのデータセットを表して変換できる統一されたプログラミングモデルを提供します。Beam SDKは、バウンドデータとアンバウンドデータの両方を表すために同じクラスを使用し、そのデータに対して同じ変換を実行します。選択したBeam SDKを使用して、データ処理パイプラインを定義するプログラムを構築します。
Beamは現在、次の言語固有のSDKをサポートしています。



Scala  インターフェースは、Scioとしても利用できます。
インターフェースは、Scioとしても利用できます。
Apache Beamパイプラインランナー
Beamパイプラインランナーは、Beamプログラムで定義したデータ処理パイプラインを選択した分散処理バックエンドと互換性のあるAPIに変換します。Beamプログラムを実行する際には、パイプラインを実行するバックエンドに適切なランナーを指定する必要があります。
Beamは現在、次のランナーをサポートしています。
- Directランナー
- Apache Flinkランナー

- Apache Nemoランナー
- Apache Samzaランナー

- Apache Sparkランナー

- Google Cloud Dataflowランナー

- Hazelcast Jetランナー

- Twister2ランナー

注記:テストとデバッグの目的で、常にローカルでパイプラインを実行できます。
はじめる
データ処理タスクにBeamを使用してみましょう。
既にApache Sparkを理解している場合は、Apache Sparkからの開始ページをご覧ください。
Beamツアーでオンラインインタラクティブラーニング体験をしてみましょう。
Java SDK、Python SDK、またはGo SDKのクイックスタートに従ってください。
SDKのさまざまな機能を紹介する例については、WordCount例チュートリアルを参照してください。
学習リソースで自己ペースのツアーを行いましょう。
Beamモデル、SDK、ランナーの詳細な概念と参照資料については、ドキュメントセクションをご覧ください。
DataflowでBeamを実行する方法を学ぶには、クックブックの例をご覧ください。
コントリビュート
Beamは、Apache v2ライセンスで利用可能なApache Software Foundationプロジェクトです。Beamはオープンソースコミュニティであり、ご貢献は大歓迎です!貢献したい場合は、コントリビュートセクションをご覧ください。
最終更新日:2024/10/31
お探しのものが見つかりましたか?
すべて役に立ち、明確でしたか?変更したいことはありますか?お知らせください!