



Beam モデルの基本
Apache Beamは、バッチ処理とストリーミングデータ並列処理パイプラインの両方を定義するための統合モデルです。Beamを使い始めるには、重要なコア概念を理解する必要があります。
- パイプライン - パイプラインは、目的のデータ処理操作を定義する、ユーザーが構築した変換のグラフです。
- PCollection -
PCollectionはデータセットまたはデータストリームです。パイプラインが処理するデータはPCollectionの一部です。 - PTransform -
PTransform(または *変換*)は、パイプラインにおけるデータ処理操作、つまりステップを表します。変換は、ゼロ個以上のPCollectionオブジェクトに適用され、ゼロ個以上のPCollectionオブジェクトを生成します。 - 集約 - 集約とは、複数の(1つ以上)入力要素から値を計算することです。
- ユーザー定義関数(UDF) - 一部のBeam操作では、変換を設定する方法としてユーザー定義コードを実行できます。
- スキーマ - スキーマとは、
PCollectionの言語に依存しない型定義です。PCollectionのスキーマは、そのPCollectionの要素を名前付きフィールドの順序付きリストとして定義します。 - SDK - パイプラインの作成者が変換を構築し、パイプラインを構築し、ランナーに送信できるようにする言語固有のライブラリです。
- ランナー - ランナーは、選択したデータ処理エンジンの機能を使用してBeamパイプラインを実行します。
- ウィンドウ -
PCollectionは、個々の要素のタイムスタンプに基づいてウィンドウに細分できます。ウィンドウを使用すると、コレクションを有限コレクションのウィンドウに分割することにより、時間とともに増加するコレクションに対するグループ化操作が可能になります。 - ウォーターマーク - ウォーターマークとは、特定のウィンドウ内のすべてのデータが到着すると予想される時期の推測です。これは、データが必ずしも時間順にパイプラインに到着するとは限らず、常に予測可能な間隔で到着するとは限らないため、必要です。
- トリガー - トリガーは、各ウィンドウの結果を集約するタイミングを決定します。
- 状態とタイマー - キーごとの状態とタイマーコールバックは、時間とともに増加する入力コレクションの集約を完全に制御できる、より低レベルのプリミティブです。
- 分割可能なDoFn - 分割可能なDoFnを使用すると、要素をモノリシックではない方法で処理できます。要素の処理をチェックポイントし、ランナーは残りの作業を分割して追加の並列処理を生成できます。
以下のセクションでは、これらの概念について詳しく説明し、追加のドキュメントへのリンクを提供します。
パイプライン
Beamパイプラインは、データ処理タスクにおけるすべてのデータと計算のグラフ(具体的には、有向非巡回グラフ)です。これには、入力データの読み取り、そのデータの変換、出力データの書き込みが含まれます。パイプラインは、ユーザーが選択したSDKで構築されます。その後、パイプラインはSDKから直接、またはRunner APIのRPCインターフェースを介してランナーに送られます。たとえば、この図は分岐パイプラインを示しています。

この図では、ボックスは_PTransform_と呼ばれる並列計算を表し、円で囲まれた矢印は変換間を流れるデータ(_PCollection_の形式)を表します。データは、境界のある、格納されたデータセットである場合もあれば、境界のないデータストリームである場合もあります。Beamでは、ほとんどの変換は境界のあるデータと境界のないデータに等しく適用されます。
考えられるほぼすべての計算を、グラフとしてBeamパイプラインとして表現できます。Beamドライバプログラムは、通常、 Pipeline オブジェクトを作成することから始まり、そのオブジェクトをパイプラインのデータセットと変換を作成するための基礎として使用します。
パイプラインの詳細については、以下のページを参照してください。
PCollection
PCollection は、順序付けられていない要素のバッグです。各 PCollection は、潜在的に分散された同種のデータセットまたはデータストリームであり、それが作成された特定の Pipeline オブジェクトによって所有されます。複数のパイプラインが PCollection を共有することはできません。BeamパイプラインはPCollectionを処理し、ランナーはこれらの要素を格納する役割を担います。
PCollection には、一般的に「ビッグデータ」(単一のマシンのメモリに収まらないほど大量のデータ)が含まれています。データの小さなサンプルまたは中間結果が単一のマシンのメモリに収まる場合もありますが、Beamの計算パターンと変換は、分散データ並列計算が必要な状況に焦点を当てています。したがって、 PCollection の要素を個別に処理することはできず、代わりに並列で均一に処理されます。
PCollectionの以下の特性を知っておくことは重要です。
有界と無界:
PCollectionは有界または無界のいずれかになります。
- 有界
PCollectionは、既知の固定サイズのデータセットです(あるいは、時間とともに増加しないデータセット)。有界データはバッチパイプラインで処理できます。 - 無界
PCollectionは時間とともに増加するデータセットであり、要素は到着するとすぐに処理されます。無界データはストリーミングパイプラインで処理する必要があります。
これらの2つのカテゴリは、バッチ処理とストリーム処理の直感から派生していますが、Beamでは2つが統合されており、有界と無界のPCollectionは同じパイプライン内に共存できます。ランナーが有界PCollectionのみをサポートできる場合、無界PCollectionを含むパイプラインは拒否する必要があります。ランナーがストリームのみを対象としている場合、Beamのサポートコードには、すべてを無界データを対象とするAPIに変換するアダプターがあります。
タイムスタンプ:
PCollectionのすべての要素には、タイムスタンプが関連付けられています。
ストレージシステムへのプリミティブコネクタを実行すると、そのコネクタは初期タイムスタンプを提供する役割を担います。ランナーはタイムスタンプを伝播および集約する必要があります。要素がイベントを表さない特定のバッチ処理ジョブのように、タイムスタンプが重要でない場合、タイムスタンプは表現可能な最小のタイムスタンプになり、口語的に「負の無限大」と呼ばれることがよくあります。
ウォーターマーク:
すべてのPCollectionには、PCollectionの完了度を推定するウォーターマークが必要です。
ウォーターマークは、「これより前のタイムスタンプを持つ要素は見られないだろう」という推測です。データソースはウォーターマークを生成する役割を担います。ランナーは、PCollectionが処理、マージ、およびパーティション化されるときに、ウォーターマークの伝播を実装する必要があります。
PCollectionの内容は、ウォーターマークが「無限大」に進んだときに完了します。このようにして、無界のPCollectionが有限であることを発見できます。
ウィンドウ化された要素:
PCollectionのすべての要素は、ウィンドウ内に存在します。複数のウィンドウに存在する要素はありません。2つの要素はウィンドウを除いて等しい場合がありますが、同じではありません。
要素が外部に書き込まれると、効果的にグローバルウィンドウに戻されます。データ書き込みを行い、この観点を持たない変換は、データ損失のリスクがあります。
ウィンドウには最大タイムスタンプがあります。ウォーターマークが最大タイムスタンプにユーザー指定の許容遅延を加えた値を超えると、ウィンドウは期限切れになります。期限切れのウィンドウに関連するすべてのデータは、いつでも破棄される可能性があります。
コーダー:
すべてのPCollectionには、要素のバイナリ形式の仕様であるコーダーがあります。
Beamでは、ユーザーのパイプラインはランナーの言語とは異なる言語で記述できます。ランナーが実際にユーザーデータを逆シリアル化できるという期待はありません。Beamモデルは、主にエンコードされたデータ、「ただのバイト」で動作します。各PCollectionには、要素の宣言されたエンコーディング(コーダーと呼ばれる)があります。コーダーには、エンコーディングを識別するURNがあり、追加のサブコーダーが含まれている場合があります。たとえば、リストのコーダーには、リストの要素のコーダーが含まれている場合があります。言語固有のシリアル化手法が頻繁に使用されますが、ランナーが理解できるように、いくつかの共通のキー形式(キーと値のペアやタイムスタンプなど)があります。
ウィンドウ化戦略:
すべてのPCollectionには、グループ化操作とトリガー操作に不可欠な情報の仕様であるウィンドウ化戦略があります。 Window変換はウィンドウ化戦略を設定し、GroupByKey変換はウィンドウ化戦略によって制御される動作を持ちます。
PCollectionの詳細については、次のページを参照してください
PTransform
PTransform(または変換)は、パイプライン内のデータ処理操作、つまりステップを表します。変換は通常、1つ以上の入力PCollectionオブジェクトに適用されます。入力を 読み取る変換は例外です。これらの変換には、入力PCollectionがない場合があります。
変換処理ロジックは関数オブジェクト(口語的に「ユーザーコード」と呼ばれる)の形式で提供され、ユーザーコードは入力PCollection(または複数のPCollection)の各要素に適用されます。選択したパイプラインランナーとバックエンドに応じて、クラスター全体の多くの異なるワーカーがユーザーコードのインスタンスを並列実行する場合があります。各ワーカーで実行されるユーザーコードは、0個以上の出力PCollectionオブジェクトに追加される出力要素を生成します。
Beam SDKには、パイプラインのPCollectionに適用できるさまざまな変換が含まれています。これらには、ParDoやCombineなどの汎用コア変換が含まれます。 SDKには、コレクション内の要素のカウントや結合など、有用な処理パターンで1つ以上のコア変換を組み合わせる、事前に記述された複合変換も含まれています。パイプラインのユースケースに合わせて、独自のより複雑な複合変換を定義することもできます。
次のリストには、いくつかの一般的な変換タイプがあります
TextIO.ReadやCreateなどのソース変換。ソース変換は概念的には入力がありません。ParDo、GroupByKey、CoGroupByKey、Combine、Countなどの処理および変換操作。TextIO.Writeなどの出力変換。- ユーザー定義のアプリケーション固有の複合変換。
変換の詳細については、次のページを参照してください
- Beamプログラミングガイド:概要
- Beamプログラミングガイド:変換
- Beam変換カタログ(Java、Python)
集約
集約とは、複数の(1つ以上の)入力要素から値を計算することです。 Beamでは、集約の主要な計算パターンは、共通のキーとウィンドウを持つすべての要素をグループ化し、次に、結合的および可換演算を使用して各要素のグループを結合することです。これは、MapReduceモデルの「Reduce」操作に似ていますが、有界データセットだけでなく、無界入力ストリームでも機能するように拡張されています。
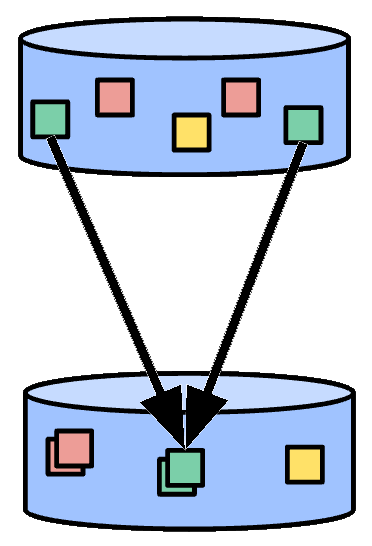
図1:要素の集約。同じ色の要素は、共通のキーとウィンドウを持つ要素を表します。
いくつかの単純な集約変換には、Count(集約内のすべての要素の数を計算する)、Max(集約内の最大要素を計算する)、およびSum(集約内のすべての要素の合計を計算する)が含まれます。
要素がグループ化されてバッグとして出力される場合、集約はGroupByKeyと呼ばれます(結合/可換演算はバッグユニオンです)。この場合、出力は入力より小さくなりません。多くの場合、合計などの操作(CombineFnと呼ばれる)を適用します。この場合、出力は入力より大幅に小さくなります。この場合、集約はCombinePerKeyと呼ばれます。
実際のアプリケーションでは、数百万のキーやウィンドウが存在する可能性があります。そのため、これは依然として「きわめて並列的な」計算パターンです。キーの数が少ない場合は、補助キーを追加し、問題の各自然キーを多数のサブキーに分割することで、並列性を追加できます。これらのサブキーが集約された後、結果は問題の元の自然キーの結果にさらに結合できます。集約関数の結合性により、これにより、より多くの並列性で同じ回答が得られます。
入力が無制限の場合、キーとウィンドウで要素をグループ化する計算パターンはほぼ同じですが、集約結果を出力するタイミングと方法を制御するには、3つの概念が必要です
使用可能な集約変換の詳細については、次のページを参照してください
- Beamプログラミングガイド:コアBeam変換
- Beam変換カタログ(Java、Python)
ユーザー定義関数(UDF)
一部のBeam操作では、変換を設定する方法としてユーザー定義コードを実行できます。たとえば、ParDoを使用する場合、ユーザー定義コードはすべての要素に適用する操作を指定します。 Combineの場合、値を結合する方法を指定します。クロスランゲージ変換を使用することにより、Beamパイプラインには、異なる言語で記述されたUDF、または同じパイプライン内の複数の言語で記述されたUDFを含めることができます。
Beamにはいくつかの種類のUDFがあります
- DoFn - 要素ごとの処理関数(
ParDoで使用) - WindowFn - 要素をウィンドウに配置し、ウィンドウをマージする(
WindowおよびGroupByKeyで使用) - ViewFn - マテリアライズされた
PCollectionを特定のインターフェースに適合させる(サイド入力で使用) - WindowMappingFn - ある要素のウィンドウを別のウィンドウにマッピングし、結果ウィンドウが過去のどの程度までになるかの境界を指定する(サイド入力で使用)
- CombineFn - 結合的および可換集約(
Combineおよび状態で使用) - Coder - ユーザーデータをエンコードする。一部のコーダーは標準形式であり、実際にはUDFではない
各言語SDKには、Beamでユーザー定義関数を表現する独自の慣用的な方法がありますが、一般的な要件があります。 Beam変換のユーザーコードを作成する場合、実行の分散性を考慮する必要があります。たとえば、多くの異なるマシンで関数の多数のコピーが並列に実行されている可能性があり、これらのコピーは、他のコピーと通信または状態を共有することなく、独立して機能します。ユーザーコード関数の各コピーは、選択したパイプラインランナーと処理バックエンドに応じて、再試行されるか、複数回実行される場合があります。 Beamは、ステートフル処理APIを介したステートフル処理もサポートしています。
ユーザー定義関数の詳細については、次のページを参照してください
- Beam変換のユーザーコードを作成するための要件
- Beamプログラミングガイド:ParDo
- Beamプログラミングガイド:WindowFn
- Beamプログラミングガイド:CombineFn
- Beamプログラミングガイド:Coder
- Beamプログラミングガイド:サイド入力
スキーマ
スキーマは、PCollectionの言語に依存しない型定義です。 PCollectionのスキーマは、そのPCollectionの要素を名前付きフィールドの順序付きリストとして定義します。各フィールドには、名前、タイプ、および場合によってはユーザーオプションのセットがあります。
多くの場合、PCollection 内の要素型は、イントロスペクト(内部を検査)できる構造を持っています。JSON、Protocol Buffer、Avro、データベースの行オブジェクトなどがその例です。これらのフォーマットはすべて Beamスキーマに変換できます。SDKパイプライン内でも、Simple Java POJO(または他の言語の同等の構造)が中間型としてよく使用されますが、これらもクラスを検査することで推測できる明確な構造を持っています。パイプラインのレコードの構造を理解することで、データ処理のためのより簡潔なAPIを提供できます。
Beamは、スキーマ上でネイティブに動作する変換のコレクションを提供します。たとえば、Beam SQLは、スキーマ上で動作する一般的な変換です。これらの変換により、名前付きスキーマフィールドによる選択と集約が可能になります。スキーマのもう1つの利点は、要素フィールドを名前で参照できることです。Beamは、ネストされたフィールドや繰り返しフィールドを含む、フィールドを参照するための選択構文を提供します。
スキーマの詳細については、以下のページをご覧ください。
ランナー
Beamランナーは、特定のプラットフォーム上でBeamパイプラインを実行します。ほとんどのランナーは、Apache Flink、Apache Spark、Google Cloud Dataflowなど、大規模並列ビッグデータ処理システムへのトランスレータまたはアダプタです。たとえば、FlinkランナーはBeamパイプラインをFlinkジョブに変換します。Direct Runnerはパイプラインをローカルで実行するため、パイプラインがApache Beamモデルにできるだけ厳密に準拠していることをテスト、デバッグ、検証できます。
Beamランナーの最新リストと、それらがサポートするApache Beamモデルの機能については、ランナーの機能マトリックスをご覧ください。
ランナーの詳細については、以下のページをご覧ください。
ウィンドウ
ウィンドウ化は、個々の要素のタイムスタンプに従って、PCollection を*ウィンドウ*に細分化します。ウィンドウは、コレクションを有限コレクションのウィンドウに分割することにより、非有界コレクションに対するグループ化操作を可能にします。
*ウィンドウ化関数*は、ランナーに要素を1つ以上の初期ウィンドウに割り当てる方法と、グループ化された要素のウィンドウをマージする方法を指示します。PCollection 内の各要素は1つのウィンドウにのみ存在できるため、ウィンドウ化関数が要素に対して複数のウィンドウを指定した場合、要素は概念的に各ウィンドウに複製され、各要素はウィンドウを除いて同一です。
GroupByKey や Combine など、複数の要素を集約する変換は、ウィンドウごとに暗黙的に機能します。コレクション全体が非有界サイズの場合でも、各 PCollection を複数の有限ウィンドウの連続として処理します。
Beamはいくつかのウィンドウ化関数を提供します。
- **固定時間ウィンドウ**(「タンブリングウィンドウ」とも呼ばれます)は、データストリーム内で一貫した期間の重複しない時間間隔を表します。
- **スライド時間ウィンドウ**(「ホッピングウィンドウ」とも呼ばれます)もデータストリーム内の時間間隔を表します。ただし、スライド時間ウィンドウは重複する可能性があります。
- **セッションごとのウィンドウ**は、別の要素から一定のギャップ期間内にある要素を含むウィンドウを定義します。
- **単一グローバルウィンドウ**:デフォルトでは、
PCollection内のすべてのデータは単一グローバルウィンドウに割り当てられ、遅延データは破棄されます。 - **カレンダーベースのウィンドウ**(Python用Beam SDKではサポートされていません)
より複雑な要件がある場合は、独自のウィンドウ化関数を定義することもできます。
たとえば、5分間のウィンドウを持つ固定時間ウィンドウ化を使用する PCollection があるとします。各ウィンドウについて、Beamは、指定されたウィンドウ範囲内(たとえば、最初のウィンドウでは0:00から4:59の間)のイベント時間タイムスタンプを持つすべてのデータを収集する必要があります。その範囲外のタイムスタンプを持つデータ(5:00以降のデータ)は、別のウィンドウに属します。
2つの概念はウィンドウ化と密接に関連しており、以下のセクションで説明します。ウォーターマークとトリガー。
ウィンドウの詳細については、以下のページをご覧ください。
ウォーターマーク
どのデータ処理システムでも、データイベントが発生した時刻(データ要素自体のタイムスタンプによって決定される「イベント時間」)と、パイプラインの任意のステージで実際のデータ要素が処理される時刻(要素を処理するシステムのクロックによって決定される「処理時間」)の間には、一定の遅延があります。さらに、データは必ずしも時間順にパイプラインに到着するとは限らず、常に予測可能な間隔で到着するとも限りません。たとえば、順序を保持しない中間システムが存在する場合や、データをタイムスタンプする2つのサーバーがあり、一方のネットワーク接続の方が良好な場合があります。
この潜在的な予測不可能性に対処するために、Beamは*ウォーターマーク*を追跡します。ウォーターマークは、特定のウィンドウ内のすべてのデータがパイプラインに到着すると予想される時期の推測です。「これより前のタイムスタンプを持つ要素は表示されない」と考えることもできます。
データソースはウォーターマークを生成する役割を担い、すべてのPCollectionは、PCollectionがどれだけ完了しているかを推定するウォーターマークを持っている必要があります。ウォーターマークが「無限大」に進んだとき、PCollectionの内容は完了です。このようにして、非有界のPCollectionが有限であることを発見するかもしれません。ウォーターマークがウィンドウの終わりを過ぎると、そのウィンドウにタイムスタンプ付きで到着するそれ以降の要素はすべて*遅延データ*と見なされます。
トリガーは、PCollectionのウィンドウ化戦略を変更および調整できる関連概念です。トリガーを使用して、ウィンドウが遅延要素をどのように出力するかを含め、個々のウィンドウが集約して結果を報告するタイミングを決定できます。
ウォーターマークの詳細については、以下のページをご覧ください。
トリガー
データをウィンドウに収集してグループ化する場合、Beamは*トリガー*を使用して、各ウィンドウの集約結果(*ペイン*と呼ばれます)を出力するタイミングを決定します。Beamのデフォルトのウィンドウ化構成とデフォルトのトリガーを使用すると、Beamはすべてのデータが到着したと推定したときに集約結果を出力し、そのウィンドウの後続のデータはすべて破棄します。
大まかに言えば、トリガーはウィンドウの終わりに出力するのと比較して2つの追加機能を提供します。
- トリガーを使用すると、Beamは、特定のウィンドウ内のすべてのデータが到着する前に、早期の結果を出力できます。たとえば、一定の時間が経過した後、または一定の数の要素が到着した後に、出力します。
- トリガーは、イベント時間ウォーターマークがウィンドウの終わりを通過した後にトリガーすることにより、遅延データの処理を許可します。
これらの機能により、データの流れを制御し、データの完全性、レイテンシ、コストのバランスをとることができます。
Beamは、設定できる多くの組み込みトリガーを提供します。
- **イベント時間トリガー**:これらのトリガーは、各データ要素のタイムスタンプで示されるイベント時間で動作します。Beamのデフォルトのトリガーはイベント時間ベースです。
- **処理時間トリガー**:これらのトリガーは、処理時間で動作します。これは、データ要素がパイプラインの任意のステージで処理される時間です。
- **データドリブントリガー**:これらのトリガーは、各ウィンドウに到着するデータを調べて動作し、そのデータが特定のプロパティを満たす場合に起動します。現在、データドリブントリガーは、特定の数のデータ要素の後でのみ起動をサポートしています。
- **複合トリガー**:これらのトリガーは、複数のトリガーをさまざまな方法で組み合わせます。たとえば、早期データ用に1つのトリガー、遅延データ用に別のトリガーが必要になる場合があります。
トリガーの詳細については、以下のページをご覧ください。
状態とタイマー
Beamのウィンドウ化とトリガーは、タイムスタンプに基づいて非有界入力データをグループ化および集約するための抽象化を提供します。ただし、さらに高度な制御を必要とする集約ユースケースがあります。状態とタイマーは、これらのユースケースに役立つ2つの重要な概念です。他の集約と同様に、状態とタイマーはウィンドウごとに処理されます。
状態:
Beamは、キーごとの状態を手動で管理するための状態APIを提供し、集約をきめ細かく制御できるようにします。状態APIを使用すると、要素ごとの操作(たとえば、ParDoまたはMap)を可変状態を使用して拡張できます。他の集約と同様に、状態はウィンドウごとに処理されます。
状態APIは、キーごとの状態をモデル化します。状態APIを使用するには、キー付きのPCollectionから始めます。このPCollectionを処理するParDoは、永続的な状態変数を宣言できます。ParDo内で各要素を処理する場合、状態変数を使用して、現在のキーの状態を書き込んだり更新したり、そのキーに対して以前に書き込まれた状態を読み取ったりできます。状態は常に現在の処理キーのみに完全にスコープされます。
Beamはいくつかのタイプの状態を提供しますが、ランナーによってサポートされる状態のサブセットが異なる場合があります。
- **ValueState**:ValueStateはスカラー状態値です。入力の各キーについて、ValueStateは
DoFn内で読み取りおよび変更できる型付き値を格納します。 - 状態の一般的なユースケースは、複数の要素をグループに蓄積することです。
- **BagState**:BagStateを使用すると、要素を順序付けられていないバッグに蓄積できます。これにより、以前に蓄積された要素を読み取ることなく、コレクションに要素を追加できます。
- **MapState**:MapStateを使用すると、要素をマップに蓄積できます。
- **SetState**:SetStateを使用すると、要素をセットに蓄積できます。
- **OrderedListState**:OrderedListStateを使用すると、要素をタイムスタンプでソートされたリストに蓄積できます。
- **CombiningState**:CombiningStateを使用すると、Beamコンバイナーを使用して更新される状態オブジェクトを作成できます。BagStateと同様に、現在の値を読み取ることなく集約に要素を追加でき、アキュムレータはコンバイナーを使用して圧縮できます。
状態APIとタイマーAPIを一緒に使用して、ワークフローをきめ細かく制御できる処理タスクを作成できます。
タイマー:
Beamは、状態APIを使用して格納されたデータの遅延処理を可能にする、キーごとのタイマーコールバックAPIを提供します。タイマーAPIを使用すると、イベント時間または処理時間のタイムスタンプでコールバックするタイマーを設定できます。より高度なユースケースでは、タイマーコールバックで別のタイマーを設定できます。他の集約と同様に、タイマーはウィンドウごとに処理されます。タイマーAPIと状態APIを一緒に使用して、ワークフローをきめ細かく制御できる処理タスクを作成できます。
次のタイマーが利用可能です。
- **イベント時間タイマー**:イベント時間タイマーは、
DoFnの入力ウォーターマークがタイマーの設定時刻を通過したときに起動します。つまり、ランナーは、タイマーのタイムスタンプの前にタイムスタンプを持つ処理対象の要素がこれ以上ないと考えています。これにより、イベント時間の集約が可能になります。 - **処理時間タイマー**:処理時間タイマーは、実際の壁時計時間が経過したときに起動します。これは、処理する前により大きなデータバッチを作成するためによく使用されます。また、特定の時間に発生するイベントをスケジュールするためにも使用できます。
- **動的タイマータグ**:Beamは、動的にタイマータグを設定することもサポートしています。これにより、
DoFnに複数の異なるタイマーを設定し、タイマータグを動的に選択できます(たとえば、入力要素のデータに基づいて)。
状態とタイマーの詳細については、以下のページをご覧ください。
分割可能なDoFn
分割可能なDoFn(SDF)は、要素を非モノリシックな方法で処理できるDoFnの一般化です。分割可能なDoFnを使用すると、Beamで複雑でモジュール式のI/Oコネクタを簡単に作成できます。
通常の ParDo は、要素全体を一度に処理し、通常の DoFn を適用して、呼び出しが終了するのを待ちます。代わりに、分割可能な DoFn を各要素に適用すると、ランナーは要素の処理をより小さなタスクに分割するオプションを持つことができます。要素の処理をcheckpointし、残りの作業を分割して並列性を高めることができます。
たとえば、非常に大きなテキストファイルからすべての行を読み取りたいとします。分割可能な DoFn を記述する場合、ファイルのセグメントを読み取る、ファイルのセグメントをサブセグメントに分割する、現在のセグメントの進捗を報告する、といった個別のロジックを持つことができます。ランナーは、分割可能な DoFn をインテリジェントに呼び出して、各入力を分割し、部分を個別に並列して読み取ることができます。
一般的な計算パターンには、次の手順があります。
- ランナーは、処理を開始する前に、受信要素を分割します。
- ランナーは、各サブ要素で処理ロジックの実行を開始します。
- ランナーは、一部のサブ要素が他のサブ要素よりも時間がかかっていることに気付くと、それらのサブ要素をさらに分割して、手順2を繰り返します。
- サブ要素の処理が完了するか、ユーザーがサブ要素をcheckpointすることを選択し、ランナーは手順2を繰り返します。
また、ランナーが非有界処理を分割できるように、分割可能な DoFn を記述することもできます。たとえば、一連のディレクトリを監視し、ファイル名が到着したら出力する分割可能な DoFn を記述する場合、分割して異なるディレクトリの作業を細分化できます。これにより、ランナーは負荷の高いディレクトリを分割し、追加のリソースを割り当てることができます。
分割可能な DoFn の詳細については、以下のページをご覧ください。
次のステップ
Beam プログラミングガイド、パイプライン実行情報、変換リファレンスカタログなどの他のドキュメントもご覧ください。
最終更新日:2024/10/31
お探しのものはすべて見つかりましたか?
すべて役に立ち、明確でしたか?変更したいことはありますか?お知らせください!