




「Apache Beamは、分散処理の低レベルの詳細ではなく、ビジネスロジックに集中できる、明確に定義されたデータ処理モデルです。」

検索エンジンのワークロードのためのスケーラビリティとコスト最適化
背景
Seznam.cz は、チェコの検索エンジンであり、ローカルのオーガニック検索トラフィックの25%以上を占めています。Seznamは1,500人以上の従業員を擁し、30以上のWebサービスと関連ブランドのポートフォリオを運営し、1日あたり約1,500万件のクエリを処理しています。
Seznamは、ユーザーにとっての検索結果の精度、品質、有用性を向上させるために、ビッグデータインフラストラクチャ、Webクローラー、アルゴリズム、MLモデルを継続的に最適化しています。SeznamはApache Beamの初期の貢献者および導入者であり、ペタバイト規模の複数のワークロードを、SeznamのオンプレミスデータセンターのApache SparkおよびApache Flinkクラスターで実行されるApache Beamパイプラインに移行しました。
Apache Beamへの道のり
Seznamは2010年にHadoop YarnクラスターでMapReduceを使用し始め、検索エンジンのWebクローラーコンポーネントの同時バッチジョブ処理を促進しました。数年以内に、データインフラストラクチャはHBaseで400億行、400テラバイトを超え、1,100台以上のベアメタルサーバー、13 PBのストレージ、50 TBのメモリを備えた2つのオンプレミスデータセンターに進化し、ビジネスロジックはより複雑になりました。MapReduceはこのような成長をサポートするのに十分な柔軟性、コスト効率、パフォーマンスを提供しなくなったため、SeznamはジョブをネイティブSparkに書き直しました。Sparkのシャッフル操作により、Seznamは大規模なデータキーをパーティションに分割し、メモリに1つずつロードして、反復的に処理することができました。ただし、指数関数的なデータの偏りと、単一のキーのすべての値をメモリ内バッファーに収めることができないため、ディスク容量の使用率とメモリのオーバーヘッドが増加しました。一部のタスクの完了に予期せぬ時間がかかり、一般的な例外のためにSparkパイプラインをデバッグするのが困難でした。そのため、Seznamはより効率的にスケーリングできるデータ処理フレームワークを必要としていました。
この種の規模を管理するには、抽象化が必要です。
2014年、SeznamはEuphoria APIの開発に着手しました。これは、バッチおよびストリーミングパイプラインでビジネスロジックを表現し、ランナーに依存しない実装を可能にする独自のプログラミングモデルです。
Apache Beamは2016年にリリースされ、すぐに利用できる明確に定義された統合プログラミングモデルになりました。このエンジンに依存しないモデルは非常に急速に進化しており、複数のシャッフル演算子をサポートし、Seznamの既存のオンプレミスデータインフラストラクチャに完全に適合します。しばらくの間、SeznamはEuphoriaの開発を続けましたが、すぐにソリューションを維持し、社内で独自のランナーを作成するために必要な高コストと労力は、独自のフレームワークを持つことのメリットを上回りました。

Seznamは、主要なワークロードをApache Beamに移行し始めました。彼らは、Euphoria APIをApache Beam Java SDKの高レベルDSLとしてマージすることを決定しました。Apache Beamへのこの重要な貢献は、Seznamがコミュニティに積極的に参加するきっかけとなり、後にBeam Summit Europe 2019や開発者会議で独自の経験と発見を発表しました。
Apache Beamの導入
Apache Beamにより、Seznamはメモリとディスク容量を増やすことなく、バッチジョブとストリームジョブをはるかに高速に実行できるようになり、スケーラビリティ、パフォーマンス、効率を最大化できました。
Apache Beamは、歪んだデータを均等に分散するためのさまざまな方法を提供します。Windowingは非有界データの処理、Partitionは有界データセットの変換に使用され、入力を再シャッフルできる有限の要素のコレクションに変換します。Apache Beamは、Apache SparkまたはApache Flinkが完全なキーを逆シリアル化することなく、SparkランナーまたはFlinkランナーで実行できるバイトベースのシャッフルを提供します。Apache Beam SDKは、要素をシリアル化および逆シリアル化して分散ワーカーに渡すための効果的なコーダーを提供します。Apache Beamのシリアル化とバイトベースのシャッフルを使用することで、Seznamの多くのユースケースでパフォーマンスが大幅に向上し、Apache Spark実行環境でのシャッフルに必要なメモリが削減されました。Seznamのインフラストラクチャコストは、ディスクI/Oとメモリスプリットに関連して大幅に削減されました。
最も価値のあるユースケースの1つは、SeznamのLinkRevertジョブです。これは、Webグラフを分析して検索の関連性を向上させるものです。このデータパイプラインは、比喩的に「インターネットを逆さまにする」ことで、1日あたり150 TBを超えるデータを処理し、リダイレクトチェーンを拡張して特定のURLのすべて後続を識別し、特定のWebページを指すバックリンクを発見します。Apache Beamパイプラインは、複数の歪んだ大規模結合を実行し、リダイレクトとバックリンクの要素に基づいて検索結果のURLをスコアリングします。
Apache Beamは、エンジンに依存しない統合実行を可能にするため、Seznamはユースケースに応じてSparkランナーまたはFlinkランナーを選択できました。たとえば、Hadoop YarnクラスターでSparkランナーによって実行されるApache Beamバッチパイプラインは、新しいWebドキュメントを解析し、追加の機能でデータを強化し、関連性に基づいてWebページをスコアリングして、タイムリーなデータベースの更新と正確な検索結果を保証します。Apache Beamストリーム処理は、ユーザーの検索結果に表示されるサムネイルリクエストのために、KubernetesクラスターのApache Flink実行環境で実行されます。ストリームイベント処理の別の例は、検索ログをマッピング、結合、および処理してSLOメトリックとその他の機能を計算するApache Beam Flinkランナーパイプラインです。
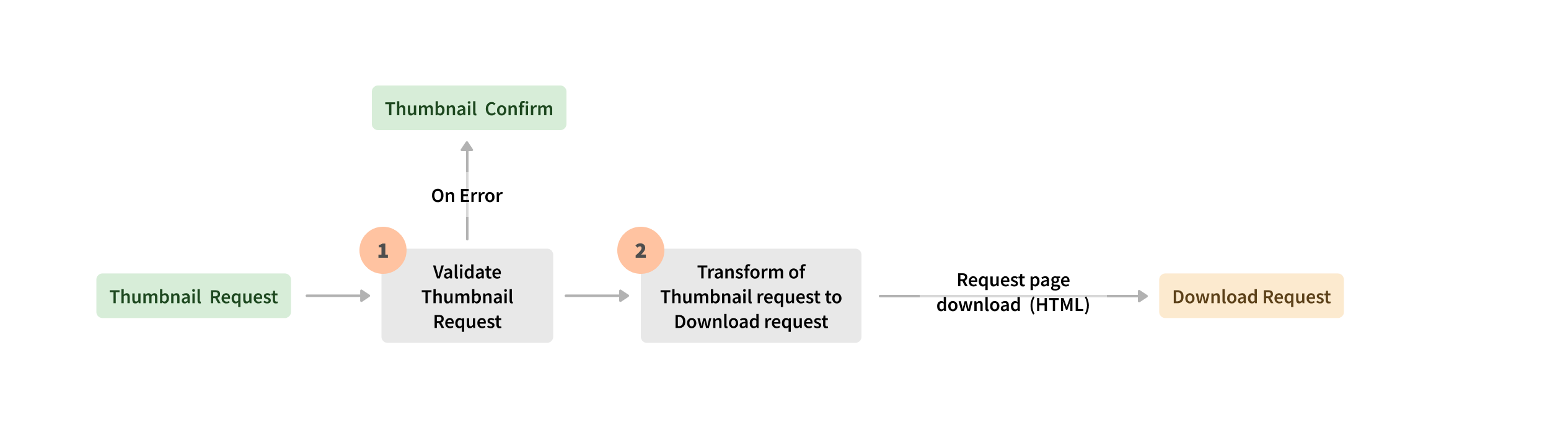
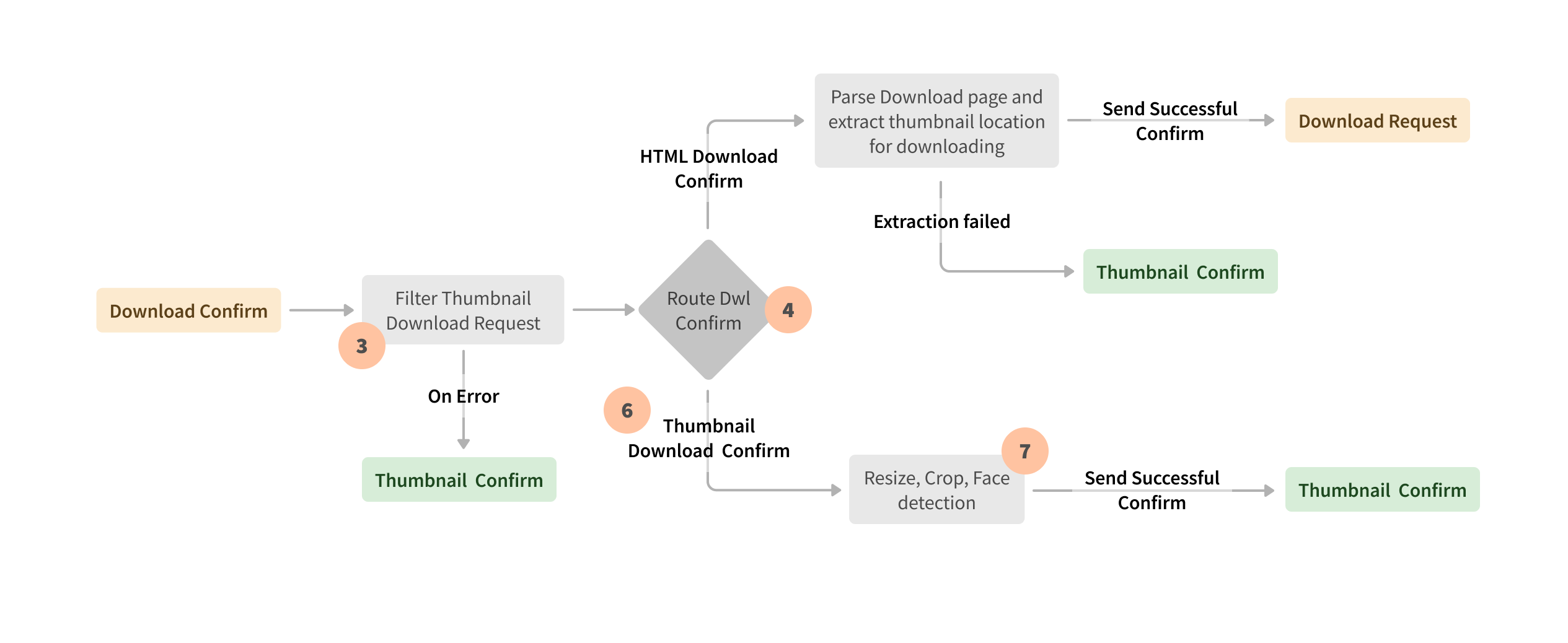
長年にわたり、Seznamのアプローチは進化してきました。彼らは、ペタバイト規模のワークロードのバランスを取り、オンプレミスデータセンターのメモリとコンピューティングリソースを最適化するためのApache Beamの計り知れないメリットに気づきました。Apache Beamは、複数のシャッフル操作、歪んだデータの処理、複雑なビジネスロジックの実装を必要とするバッチおよびストリームパイプラインのためのSeznamの頼りになるプラットフォームです。Apache Beamは、ソースとシンクを変換として公開する統合モデルにより、ビジネスロジックの保守性とトレーサビリティを単体テストで向上させました。
最大の利点の1つは、Apache Beamのシンクとソースです。ソースまたはシンクを変換として公開することにより、実装は隠蔽され、後でユーザーの既存の実装を壊すことなく追加の機能を追加できます。
監視とデバッグ
Apache Beamパイプラインの監視とデバッグは、複雑なビジネスロジックと複数のデータ変換を伴うケースにとって重要でした。Seznamのエンジニアは、実行エンジンに応じて最適なツールを特定しました。Seznamは、CriteoのBabarを活用して、SparkランナーでApache Beamパイプラインをプロファイリングし、パフォーマンスのダウンタイムの根本原因を特定しました。Babarは、クラスターリソースの使用率、割り当てられたメモリ、使用されたCPUなどを分析することにより、監視、デバッグ、およびパフォーマンスの最適化を容易にします。KubernetesクラスターでFlinkランナーによって実行されるApache Beamパイプラインの場合、SeznamはElasticsearchを使用してメトリックを保存、検索、および分析します。
結果
Apache Beamは、Seznamのストリームおよびバッチ処理のための統合モデルを提供し、スケールでのパフォーマンスを提供しました。Apache Beamは、複数のランナー、言語SDK、組み込みおよびカスタムのプラグイン可能なI/O変換をサポートしているため、独自のランナーとソリューションの開発とサポートに投資する必要がなくなりました。評価後、SeznamはワークロードをApache Beamに移行し、Euphoria API(Seznamによって開発された高速プロトタイピングフレームワーク)を統合し、Apache Beamオープンソースコミュニティに貢献しました。
Apache Beamの抽象化と実行モデルにより、Seznamはデータ処理を堅牢にスケーリングすることができました。また、ビジネスロジックを一度だけ記述し、ランナー間の選択の自由を維持できる柔軟性も提供しました。このモデルは、複雑なユースケースでのパイプラインの保守性にとって特に価値がありました。Apache Beamは、不均一に分散されたデータを管理しやすいパーティションに再シャッフルすることにより、メモリとコンピューティングリソースの制約を克服するのに役立ちました。
この情報は役に立ちましたか?