




「私は一つ確信しています。Beamは非常に強力であり、その抽象化が最も重要な機能です。適切な抽象化により、必要な場所でワークロードを実行する柔軟性が得られます。Beamのおかげで、ベンダーに縛られることなく、切り替えを行う際に他のものを変更する必要もありません。」

パロアルトネットワークスにおける大規模リアルタイムイベントストリーム処理
背景
パロアルトネットワークス株式会社は、包括的なエンタープライズ製品ポートフォリオを持つグローバルなサイバーセキュリティリーダーです。パロアルトネットワークスは、クラウド、ネットワーク、デバイス全体で85,000社以上のお客様に、保護と可視性、信頼できるインテリジェンス、自動化、柔軟性を提供しています。
パロアルトネットワークスの統合セキュリティオペレーションプラットフォームであるCortex™は、AIと機械学習を適用して、セキュリティの自動化、高度な脅威インテリジェンス、およびパロアルトネットワークスのお客様向けの迅速かつ効果的なセキュリティ対応を可能にします。Cortex™ Data Lakeインフラストラクチャは、企業セキュリティデータを収集、統合、正規化し、数兆個のマルチソースアーティファクトと組み合わせています。
Cortex™データインフラストラクチャは、現在、1秒あたり約1,000万件のセキュリティログイベントを、1日あたり約3PBで処理しており、これは業界におけるリアルタイムストリーミング処理スケールの最上位に位置します。パロアルトネットワークスのシニアプリンシパルソフトウェアエンジニアであるタラート・ウヤレル氏は、Apache Beamがこのスケールをサポートするための高性能で信頼性の高い、回復力のあるデータ処理フレームワークをどのように提供しているかについて、洞察を共有しました。
大規模ストリーミングインフラストラクチャ
データインフラストラクチャをゼロから構築する際、パロアルトネットワークスのCortex Data Lakeチームは困難な課題に直面しました。Cortexプラットフォームが、お客様のファイアウォール、ネットワーク、およびあらゆる種類のデバイスから送信されるペタバイトサイズのデータを、低遅延で完璧な品質で、お客様および内部アプリにストリーミングおよび処理できることを保証する必要がありました。
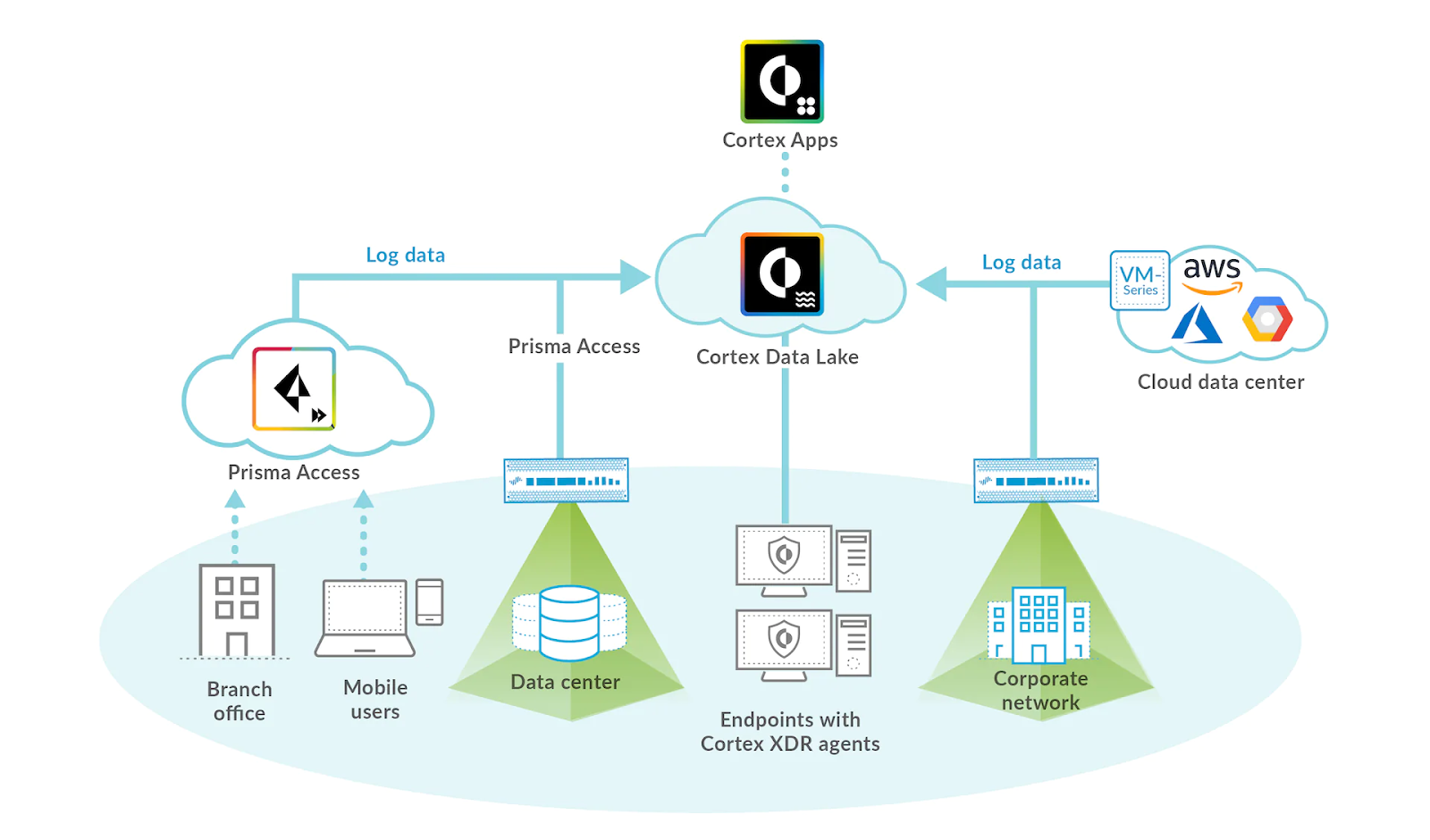
SLAを満たすために、Cortex Data Lakeチームはリアルタイム処理のための大規模データインフラストラクチャを設計し、価値実現までの時間を短縮する必要がありました。彼らの最初のアーキテクチャ上の決定の1つは、その移植性と抽象化により、統合分散処理の業界標準であるApache Beamを活用することでした。
Beamは非常に柔軟であり、分散データ処理の実装の詳細からの抽象化は、コンセプトを非常に迅速に実証するのに最適です。
Apache Beamは、さまざまなデータ処理エンジン間の選択の自由を提供するさまざまなランナーを提供します。パロアルトネットワークスのデータインフラストラクチャはすべてGoogle Cloud Platformでホストされており、Apache Beam Dataflow runnerを使用することで、Google Cloud Dataflowのマネージドサービスと自動チューニング機能を簡単に利用できました。Apache Kafkaはバックエンドのメッセージブローカーとして選択され、すべてのイベントは複数のKafkaクラスター上で共通スキーマを持つバイナリデータとして保存されました。
Cortex Data Lakeチームは、複数のアップストリームアプリケーションが独自のストリーミングジョブを作成し、Kafkaから直接イベントを消費および処理する、顧客ごとに個別のデータ処理インフラストラクチャを持つオプションを検討しました。したがって、マルチテナントシステムを構築しています。ただし、チームは、Kafkaの移行とパーティションの作成、および複数のインフラストラクチャを持つ場合に発生する可能性のあるテナントユースケースへの可視性の欠如に関連する問題が発生する可能性があると予測しました。
したがって、Cortex Data Lakeチームは共通のストリーミングインフラストラクチャアプローチを採用しました。共通データインフラストラクチャの中核として、Apache Beamは、すべての内部および顧客テナントアプリケーションに対してビジネスロジックを1回だけ実装するための統合プログラミングモデルとして機能しました。
Cortex Data Lakeチームが実装した最初のデータワークフローは、単純なものでした。Kafkaから読み取り、バッチジョブを作成し、結果をシンクに書き込むことです。SQLサポートを備えたApache Beamバージョンのリリースは、新たな可能性を切り開きました。Beam Calcite SQLは、SQLステートメント内のネストされた行を含む、複雑なApache Calciteデータ型を完全にサポートしているため、開発者は複合変換用のApache BeamパイプラインでSQLクエリを使用できます。Cortex Data Lakeチームは、標準SQLステートメントでBeamパイプラインを記述するために、Beam SQLを利用することにしました。
共通インフラストラクチャの主な課題は、さまざまなビジネスロジックのカスタマイズとユーザー定義関数をサポートし、それらをさまざまなシンク形式に変換することでした。テナントアプリケーションは、動的に変化するKafkaクラスターからデータを消費する必要があり、ジョブのソースが更新された場合は、ストリーミングパイプラインのDAGを再生成する必要がありました。
Cortex Data Lakeチームは、REST APIサービスにジョブデプロイメントリクエストを送信する際に、テナントアプリケーションがストリーミングジョブを「サブスクライブ」できるようにする独自の「サブスクリプション」モデルを開発しました。サブスクリプションサービスは、メタデータサービスにインフラストラクチャ固有の情報を格納することにより、DAGの変更からテナントアプリケーションを抽象化します。このようにして、ストリーミングジョブは動的なKafkaインフラストラクチャと同期した状態を維持します。
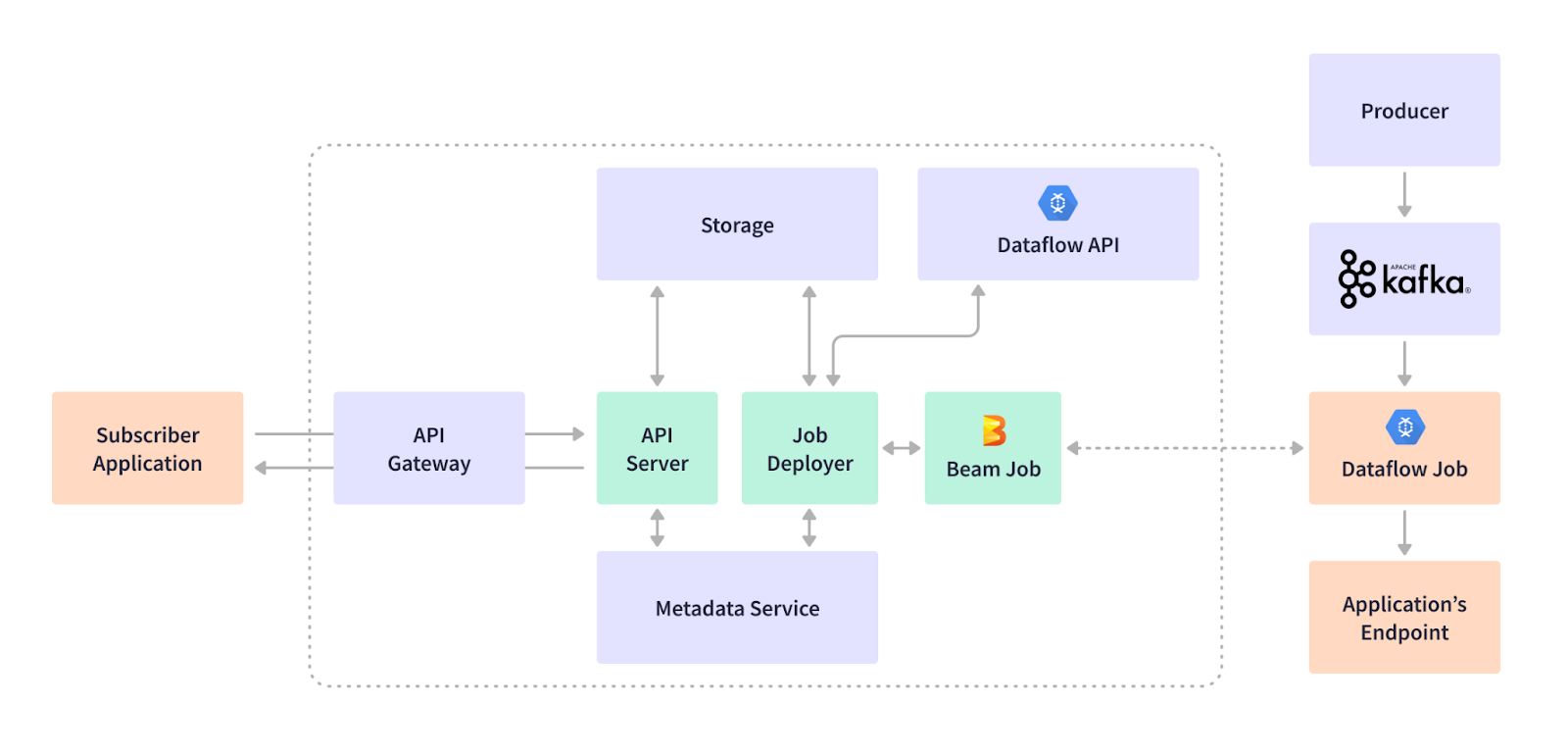
Apache Beamは柔軟性があり、ストリーミングジョブを動的に、その場で作成できます。Apache Beam構造により、事前にスキーマが完全に定義されていない場合でもデータを処理するパイプラインを可能にする、汎用的なパイプラインコーディングが可能になります。Cortexのサブスクリプションサービスは、テナントアプリケーションのRESTペイロードに基づいてApache BeamパイプラインDAGを生成し、ジョブをランナーに送信します。ジョブの実行中、Apache Beam SDKのKafka I/Oは、Kafkaレコードの非有界コレクションをPCollectionとして返します。Apache Avroは、バイナリKafka表現を汎用レコードに変換し、さらにApache Beam Row形式に変換します。Row構造は、プリミティブ、バイト配列、およびコンテナをサポートし、スキーマ定義と同じ順序で値を整理できます。
Apache Beamのクロスラングエージ変換により、Cortex Data LakeチームはJavaでSQLを実行できます。Apache Beamパイプライン内で実行されるSQL Transformの出力は、Beam Row形式から汎用レコードに、次にAvro、JSON、CSVなどのサブスクライバーアプリケーションに必要な出力形式に順次変換されます。
基本のユースケースが実装されると、Cortex Data Lakeチームは、Apache Beamパイプライン内で直接イベントのサブセットをフィルタリングするなど、より複雑な変換に取り組み、カスタマイズと最適化を検討し続けました。
お客様とアプリ全体で10以上のユースケースが実行されています。機械学習のユースケースなど、さらに多くのユースケースが追加されています...これらのユースケースでは、Beamは非常に優れたプログラミングモデルを提供します。
Apache Beamは、さまざまなツールやテクノロジーとシームレスに統合するプラグ可能なデータ処理モデルを提供しており、これにより、Cortex Data Lakeチームは、パフォーマンス要件と特定のユースケースに合わせてデータ処理をカスタマイズできました。
ユースケースに合わせたシリアライゼーションのカスタマイズ
パロアルトネットワークスのストリーミングデータインフラストラクチャは、毎日数千億件のリアルタイムセキュリティイベントを処理しており、処理時間の1秒未満の差でさえ重要です。
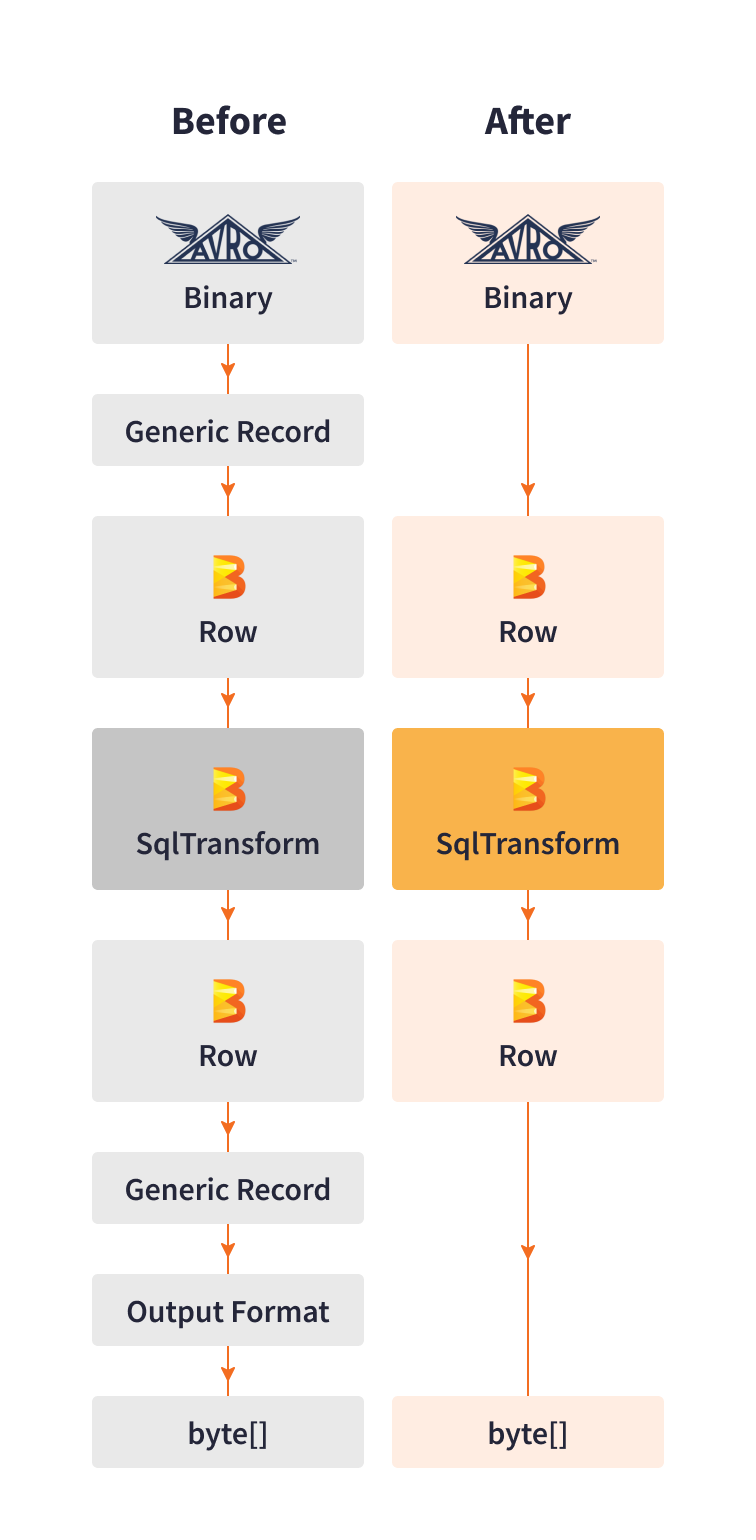
パフォーマンスを向上させるために、Cortex Data Lakeチームは、直接シリアライゼーションとデシリアライゼーションのための独自のライブラリを開発しました。このライブラリは、KafkaからAvroバイナリレコードを読み取り、それらをBeam Row形式に変換し、次にBeam Row形式のパイプライン出力を必要なシンク形式に変換します。
このカスタムライブラリは、データを汎用レコードにシリアル化する代わりに、パロアルトネットワークスの特定のユースケースに最適化されたステップを使用しました。直接シリアライゼーションにより、処理ステップからのシャッフルと追加のメモリコピーの作成が不要になりました。
このカスタマイズにより、シリアライゼーションのパフォーマンスが10倍向上し、遅延とインフラストラクチャコストを削減しながら、vCPUあたり最大3Kイベント/秒を処理できるようになりました。
インフライトストリーミングジョブの更新
同時に実行される数千のジョブの規模で、Cortex Data Lakeチームは、進行中のジョブのパイプラインコードを改善したり、バグを修正したりする必要がある場合に直面しました。Google Cloud Dataflowは、更新されたApache Beamパイプラインコードを実行する新しいジョブで、「インフライト」ストリーミングジョブを置き換える方法を提供します。ただし、パロアルトネットワークスは、サポートされているシナリオを拡張する必要がありました。
動的に変化するKafkaインフラストラクチャでジョブを更新するために、Cortex Data Lakeチームは、デプロイメントサービスに追加のワークフローを作成しました。これにより、変更がDataflowの更新で許可されていない場合はジョブをドレインし、まったく同じ名前で新しいジョブを開始します。この内部ジョブ置換ワークフローにより、Cortex Data Lakeはすべてのユースケースでジョブとペイロードを自動的に更新できます。
Beam SQLにおけるスキーマ変更の処理
パロアルトネットワークスが取り組んだ別のユースケースは、進行中のジョブのデータスキーマの変更の処理です。Apache Beamでは、PCollectionにパイプライン構築ステップで検証される名前付きフィールドを持つスキーマを持たせることができます。ジョブが送信されると、最新のスキーマに基づいて、Beamパイプラインフラグメントの形式で実行プランが生成されます。Beam SQLは、実行中のジョブの緩和されたスキーマ互換性のための組み込みサポートをまだ備えていません。最適化されたパフォーマンスのために、Beam SQLのスキーマRowCoderには固定データ形式があり、スキーマの進化を処理しないため、ジョブを再起動して実行プランを再生成する必要があります。10K+のストリーミングジョブの規模では、Cortex Data Lakeチームは可能な限りジョブの再送信を避けたいと考えました。
スキーマ変更に関連するSQLクエリを持つジョブを特定するための内部ワークフローを作成しました。このスキーマ更新ワークフローでは、各ジョブのReaderスキーマ(Avroスキーマ)と各KafkaメッセージのWriterスキーマ(Kafkaヘッダーのメタデータ)を内部スキーマレジストリに格納し、それらを実行中のジョブのSQLクエリと比較し、影響を受けるジョブのみを再起動します。この最適化により、リソースをより効率的に活用できるようになりました。
Kafka変更のためのパフォーマンスの微調整
複数のクラスターとトピック、およびKafkaの10万を超えるパーティションを持つPalo Alto Networksは、クラスター移行やパーティション数の変更など、頻繁なKafkaインフラストラクチャの変更によって、アクティブに実行中のジョブが影響を受けないようにする必要がありました。
Cortex Data Lakeチームは、「自己修復」サービスを含む、いくつかの内部Kafkaライフサイクルサポートツールを開発しました。内部サービスは、特定のテナントからのトピックごとのトラフィック量に応じて、パーティション数を増やしたり、パーティション数の少ない新しいトピックを作成したりします。「自己修復」サービスは、データストア内のKafkaの状態を比較し、関連するすべてのストリーミングApache BeamジョブをCloud Dataflow上で自動的に検索および更新します。
2021年初頭のApache Beam 2.28.0のリリースにより、事前構築済みのKafka I/O動的読み取り機能が、Kafkaパーティションの変更を検出するためのすぐに使えるソリューションを提供し、コスト削減とパフォーマンス向上を可能にしました。Kafka I/Oは、WatchKafkaTopicPartitionDoFnを使用して新しいTopicPartitionsを発行し、特定のパーティションが追加されたときにKafkaトピックから動的に読み取り、削除された場合は読み取りを停止することを可能にします。この機能により、社内Kafka監視ツールを作成する必要がなくなりました。
パフォーマンスの最適化に加えて、Cortex Data LakeチームはCloud Dataflowのコストを最適化する方法も模索してきました。ストリーミングジョブがごくわずかな受信イベントしか消費しない場合の、リソース使用率の最適化について検討しました。コスト効率のために、Google Cloud Dataflowは、負荷とリソース使用率の変化に応じてワーカー数を適応的に変更するストリーミング自動スケーリング機能を提供しています。入力データストリームが長期間静止する可能性があるCortex Data Lakeチームのユースケースの一部については、Kafkaトピックのトラフィックを分析し、入力が枯渇したパイプラインを休止させ、入力が再開されたら再アクティブ化する、内部「コールドスターター」サービスを実装しました。
Talat Uyarerは、Beam Summit 2021で、大規模ストリーミングインフラストラクチャの構築とカスタマイズに関するCortex Data Lakeの経験を発表しました。
私はBeamでの作業が本当に楽しいです。その内部構造を理解すれば、オープンソースを微調整し、カスタマイズすることで、特定のユースケースに最適なパフォーマンスを提供できるようになります。
結果
Apache Beamの抽象化レベルにより、Cortex Data Lakeチームは、社内アプリと数万の顧客に共通のインフラストラクチャを作成することができました。Apache Beamを使用すると、ビジネスロジックを一度だけ実装し、10以上のユースケースに対して並行して実行される1万以上のストリーミングパイプラインを動的に生成できます。
Cortex Data Lakeチームは、Apache Beamのポータビリティとプラグアビリティを活用して、カスタムライブラリとサービスでデータ処理インフラストラクチャを微調整および強化しました。Palo Alto Networksは最終的に、1秒あたりvCPUごとに3,000以上のストリーミングイベントを処理する、高性能かつ低レイテンシを実現しました。オープンソースのApache BeamとCloud Dataflowマネージドサービスの利点を組み合わせることで、ユースケース固有のカスタマイズを実装し、コストを60%以上削減することができました。
Apache Beamオープンソースコミュニティは、Palo Alto Networksなどの数多くのメンバーからの貢献を歓迎し、奨励しています。彼らは、Apache Beamの強力な機能を活用し、新しい最適化をもたらし、専門知識を共有し、コミュニティに積極的に参加することで、将来のイノベーションを促進します。
この情報は役立ちましたか?