




「Apache Beamは、最新のデータを利用してリアルタイムで処理することにより、LinkedInがタイムリーな推奨事項とパーソナライズされたエクスペリエンスを作成することを可能にし、最終的に世界中の9億5000万人以上の会員からなるLinkedInの広大なネットワークに利益をもたらしています。」

LinkedInにおけるリアルタイムストリーム処理の革命:1日4兆件のイベント処理
背景
LinkedInでは、Apache Beamは複数のプロダクションデータセンターにまたがる3,000以上のパイプラインを通じて、毎日4兆件を超えるイベントを処理するストリーム処理インフラストラクチャにおいて重要な役割を果たしています。この堅牢なフレームワークは、機械学習や通知から不正行為対策のAIモデリングに至るまで、重要なサービスやプラットフォームのためのニアリアルタイムデータ処理を可能にします。9億5000万人以上の会員を抱える当社にとって、プラットフォームの円滑な稼働を確保することは、世界中の会員を機会につなげる上で非常に重要です。
この事例研究では、LinkedInのエンジニアリングマネージャーであるBingfeng Xia氏とシニアスタッフエンジニアであるXinyu Liu氏が、Apache Beamプログラミングモデルの統一され、移植性が高く、ユーザーフレンドリーなデータ処理フレームワークが、数多くの高度なユースケースを実現し、LinkedInにおけるストリーム処理に革命をもたらした方法について説明します。このテクノロジーは、Apache SamzaとApache Sparkランナーによるストリーム処理とバッチ処理の統合によりコストを2倍削減し、リアルタイムMLフィーチャ生成を可能にし、新しいパイプラインの生産時間を実月から数日に短縮し、毎秒300万件を超えるクエリでの時系列イベントの処理などを可能にしました。会員にとって、これはより正確な求人推薦、フィード推薦の改善、偽アカウントのより迅速な特定などを意味します。
LinkedInのオープンソースエコシステムとBeamへの道のり
LinkedInは、オープンソースコミュニティへの積極的な貢献の歴史があり、様々なオープンソースソフトウェアプロジェクトの作成、管理、利用を通じてそのコミットメントを示しています。LinkedInのエンジニアリングチームは、複数のカテゴリにわたって75を超えるプロジェクトをオープンソース化しており、そのいくつかは広く採用され、Apache Software Foundationの一部となっています。
膨大な量のデータの取り込みとリアルタイム処理を可能にするために、LinkedInは、主に社内で開発されたツール(その後オープンソース化された)を使用してカスタムストリーム処理エコシステムを構築しました。2010年、LinkedInのリアルタイムインフラストラクチャの重要なビッグデータ取り込みバックボーンとして、Apache Kafkaを導入しました。バッチ指向の処理から移行し、数分または数秒以内にKafkaイベントに対応するために、社内分散イベントストリーミングフレームワークであるApache Samzaを構築しました。このフレームワークとバッチ処理のためのApache Sparkは、データ処理ジョブのためのLinkedInのラムダアーキテクチャの基礎を形成しました。時間の経過とともに、LinkedInのエンジニアリングチームは、複数のストアやメッセージングシステム間でのデータストリーミングを容易にするBrooklin、バッチとストリーム処理ジョブの出力を取り込むストレージシステムとして機能するVeniceなど、より多くの独自のツールを使用してストリーム処理エコシステムを拡張しました。
Apache Samzaを中核とするストリーム処理エコシステムは、大規模なステートフルデータ処理を可能にしましたが、LinkedInの絶えず進化する要求には、ストリーミングパイプラインのスケーラビリティと効率の向上、およびレイテンシの低減が必要でした。ラムダアーキテクチャのアプローチは、バッチとストリーミングデータのために2つの異なるコードベースと2つの異なるエンジンを維持する必要があるため、運用上の複雑さと非効率性を招きました。これらの課題に対処するために、データエンジニアは、より高度なストリーム処理の抽象化と、高度な集計と変換に対するすぐに使えるサポートを探していました。さらに、バッチモードでストリーミングパイプラインを試行する機能も必要でした。また、新興の機械学習のユースケースでPythonが必要になるため、Javaが中心となっているチーム全体で、複数言語のサポートが必要となることも増えました。
2016年のApache Beamのリリースは、LinkedInにとって画期的な出来事でした。Apache Beamは、バッチとストリーム処理の両方のためのオープンソースで高度な統一プログラミングモデルを提供し、様々なアプリケーション全体で、大規模な共通データインフラストラクチャを作成することを可能にします。Python、Go、Java SDKのサポートと、豊富で多様なAPIレイヤーにより、Apache Beamは、高度な複数言語パイプラインを構築し、任意のエンジンで実行するための理想的なソリューションとなりました。
Apache Beamを検討し始めたとき、LinkedInの要求に非常に魅力的なデータ処理フレームワークであることに気づきました。高度なAPIを提供するだけでなく、ストリーム処理とバッチ処理の統合と複数言語のサポートも可能にするからです。私たちが求めていたすべてがすぐに使えるものでした。

Apache Beamの統一されたデータ処理API、高度な機能、複数言語サポートの利点を認識したLinkedInは、最初のユースケースのオンボーディングを開始し、2018年にBeam用Apache Samzaランナーを開発しました。2019年までに、Apache Beamパイプラインはいくつかの重要なユースケースを支えるようになり、プログラミングモデルとフレームワークはLinkedInのチーム全体で広く採用されました。Xinyu Liu氏は、Beam Summit Europe 2019でApache Beamパイプラインへの移行のメリットを紹介しました。
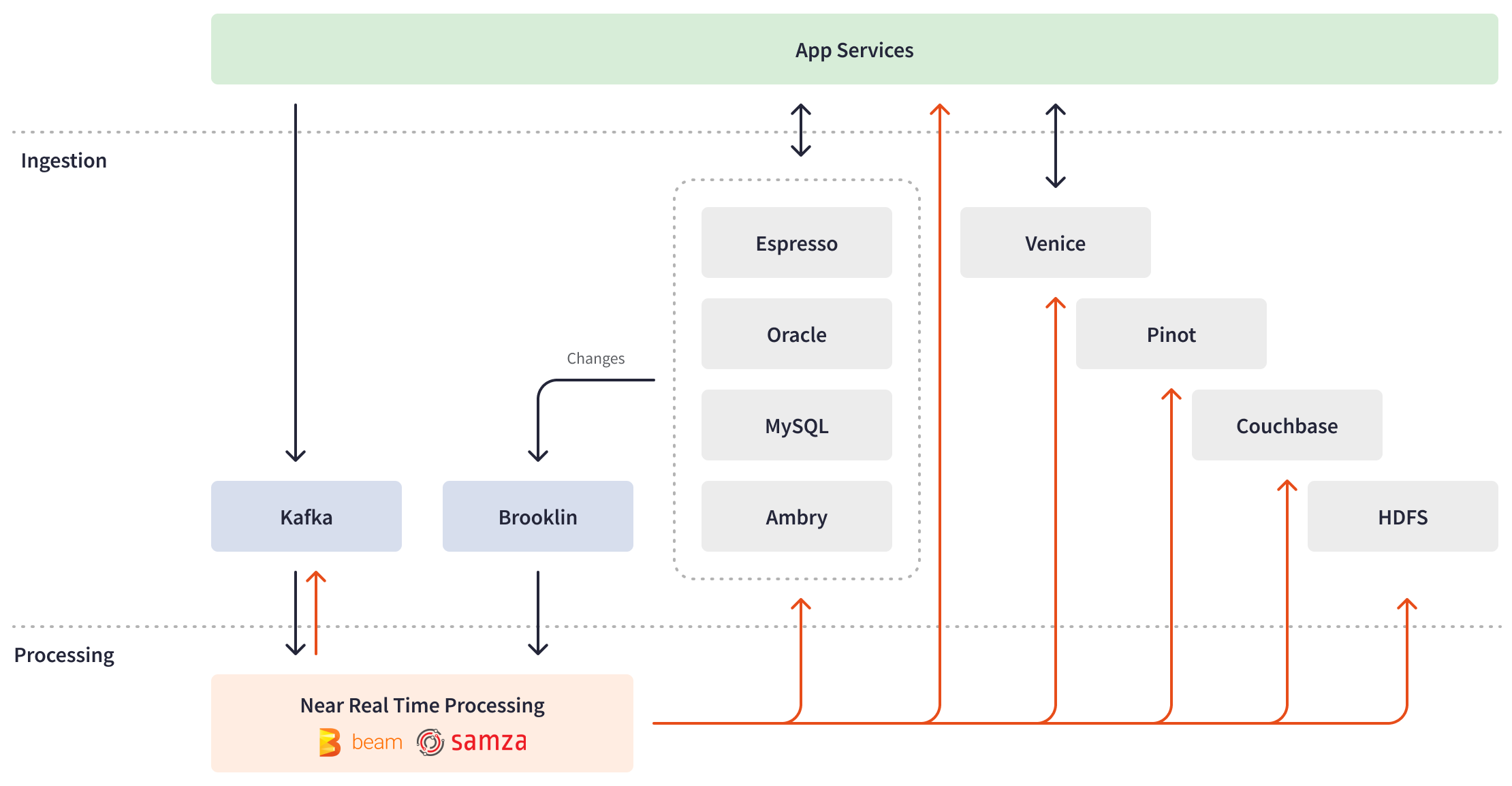
LinkedInにおけるApache Beamのユースケース
統一されたストリーミングとバッチパイプライン
LinkedInがApache Beamパイプラインに移行した最初のユースケースの一部には、リアルタイム計算と定期的なバックフィリングの両方が含まれていました。一例として、LinkedInの標準化プロセスがあります。標準化は、職名、スキル、学歴などのLinkedInユーザーの入力を事前に定義された内部IDにマッピングする複雑なAIモデルを使用する一連のパイプラインで構成されています。たとえば、「チーフデータサイエンティスト」という現在の職位をリストしているLinkedInメンバーは、関連する求人推薦のために職名が標準化されます。
LinkedInの標準化プロセスには、即時のユーザー更新を反映するためのリアルタイム処理と、新しいAIモデルが導入されたときにデータを更新するための定期的なバックフィリングの両方が必要です。Apache Beamを採用する前は、バックフィリングをストリーミングジョブとして実行するには、メモリで5,000 GB時間以上、合計CPU時間で4,000時間近くが必要でした。この大きな負荷により、バックフィリング時間が長くなり、スケーリングの問題が発生し、バックフィリングパイプラインが共存するストリーミングパイプラインの「ノイズネイバー」となり、レイテンシとスループットの要件を満たせませんでした。LinkedInのエンジニアはバックフィリングロジックをバッチSparkパイプラインに移行することを検討しましたが、2つの異なるコードベースを維持する必要のあるオーバーヘッドのために、そのアイデアを断念しました。
私たちは疑問を持ちました。1つのコードベースだけを維持し、それをバッチジョブまたはストリーミングジョブのどちらかとして実行することは可能でしょうか?統一されたApache Beamモデルがその解決策でした。
Apache Beam APIにより、LinkedInのエンジニアは、リアルタイムの標準化とバックフィリングの両方を効率的に処理する統一されたApache Beamパイプライン内にビジネスロジックを一度実装することができました。Apache BeamはPipelineOptionsを提供し、パイプラインランナーやランナー固有の設定など、様々な側面の設定とカスタマイズを可能にします。Apache Beam変換の拡張性により、LinkedInはカスタムコンポジット変換を作成してI/Oの違いを抽象化し、データソースの種類(バウンドまたはアンバウンド)に基づいてターゲット処理をオンザフライで切り替えることができました。さらに、Apache Beamによる基盤となるインフラストラクチャの抽象化と「一度記述してどこでも実行する」機能により、LinkedInはデータ処理エンジン間をシームレスに切り替えることができました。ターゲット処理の種類、ストリーミング、またはバッチに応じて、統一されたApache Beam標準化パイプラインは、ストリーミングジョブとしてSamzaクラスタ、またはバッチバックフィリングジョブとしてSparkクラスタを通じて展開できます。
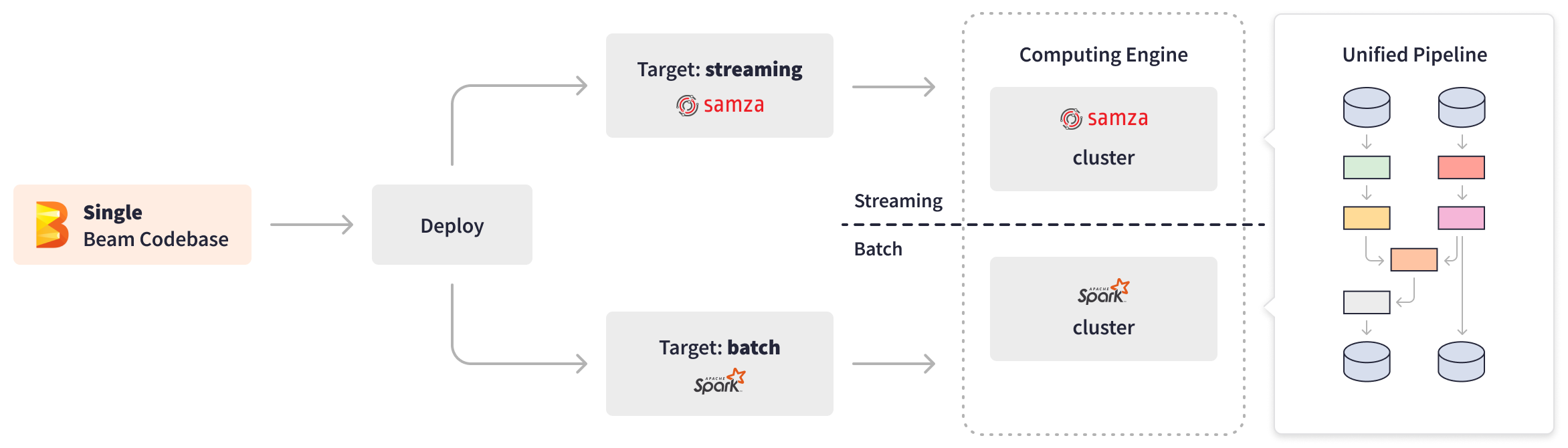
現在、何百ものストリーミングApache Beamジョブがリアルタイムの標準化を実行し、24時間365日イベントをリスニングし、リモートテーブルから追加データでストリームをリッチ化し、必要な処理を実行し、結果を出力データベースに書き込んでいます。バッチApache Beamバックフィリングジョブは毎週実行され、毎秒40,000件以上の速度で9億5000万人のメンバープロファイルを効果的に処理します。Apache Beamは、データポイントを高度なAIと機械学習モデルに推測し、職種や職歴などの複雑なデータを結合することで、検索インデックス作成または推奨モデルの実行のためにユーザーデータを標準化します。
バックフィリングロジックを統一されたApache Beamパイプラインに移行し、バッチモードで実行した結果、メモリとCPUの使用効率が50%向上し(約5000 GB時間と約4000 CPU時間から約2000 GB時間と約1700 CPU時間)、処理時間が94%短縮されました(7.5時間から25分)。このユースケースの詳細については、LinkedInのエンジニアリングブログをご覧ください。
不正行為対策とニアリアルタイムAIモデリング
LinkedInは、会員にとって信頼できる環境を構築することに尽力しており、この献身は、プラットフォーム上の様々な種類の不正行為から保護することにまで及びます。これを達成するために、LinkedInの不正行為対策AIチームは、偽アカウントの作成、メンバープロファイルのスクレイピング、自動化されたスパム、アカウント乗っ取りなど、様々な種類の不正行為を検出し、防止できるAIと深層学習モデルの作成、展開、維持において重要な役割を果たしています。
Apache BeamはLinkedInの内部不正行為対策プラットフォームであるChronosを強化し、ニアリアルタイムでの不正行為の検出と防止を可能にします。Chronosは、フィルタパイプラインとモデルパイプラインという2つのストリーミングApache Beamパイプラインに依存しています。フィルタパイプラインはKafkaからユーザーアクティビティイベントを読み取り、関連フィールドを抽出し、イベントを集約およびフィルタリングし、その後、ダウンストリームのAI処理のためにフィルタリングされたKafkaメッセージを生成します。その後、モデルパイプラインはこれらのフィルタリングされたメッセージを消費し、特定の時間枠内のメンバーアクティビティを集約し、AIスコアリングモデルをトリガーし、結果として得られた不正行為スコアをオフライン処理のために様々な内部アプリケーション、サービス、ストアに書き込みます。
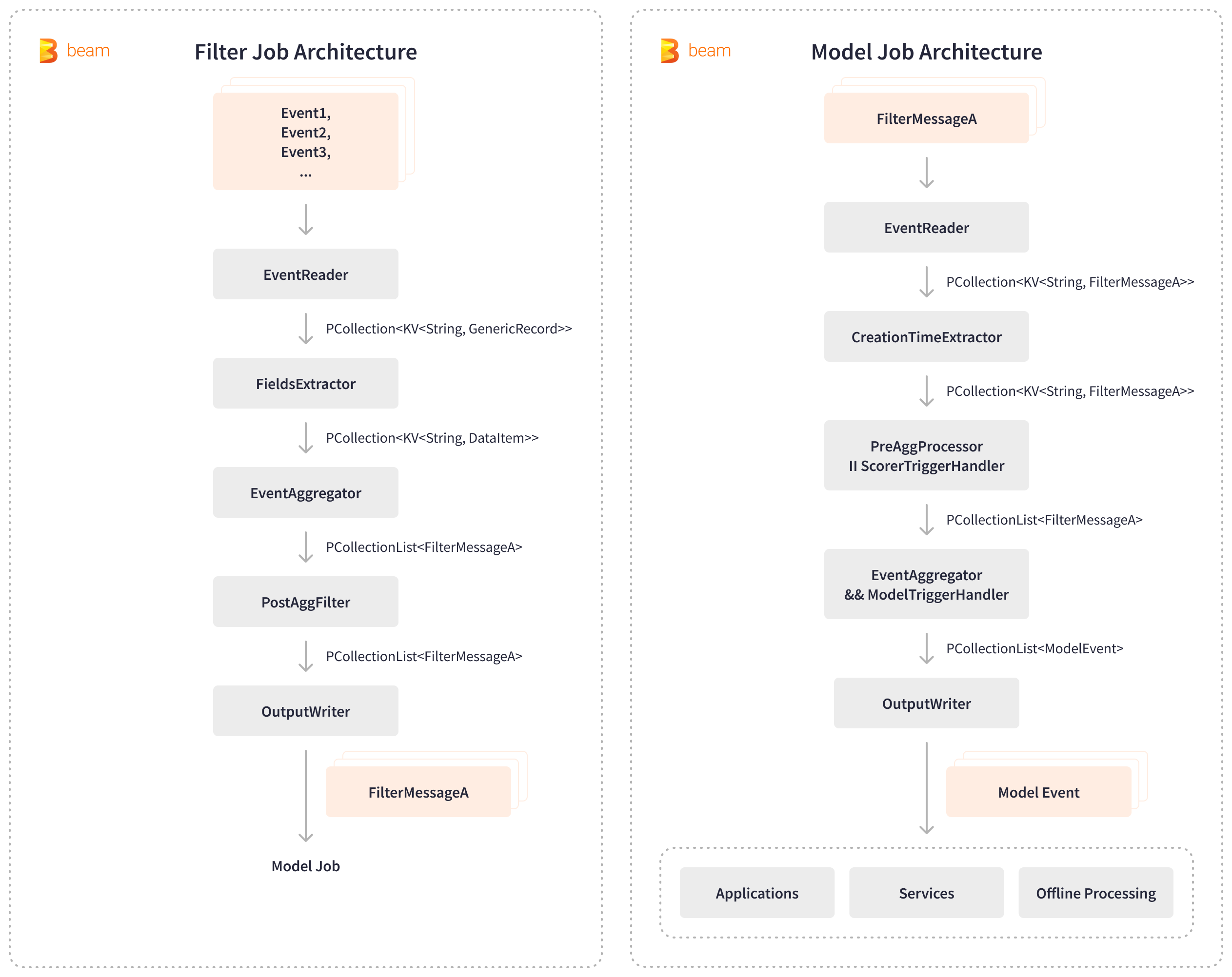
Apache Beamのプラグ可能なアーキテクチャの柔軟性と、様々なI/Oオプションの可用性により、不正利用対策パイプラインはKafkaとキーバリューストアとシームレスに統合されました。LinkedInは、不正行為のラベル付けにかかる時間を1日からわずか5分に劇的に短縮し、毎秒300万件を超えるクエリで時系列イベントを処理しています。Apache Beamはニアリアルタイム処理を実現し、LinkedInの不正利用対策を大幅に強化しました。ニアライン防御は、スクレイピング開始後数分以内にスクレイパーを検出することができ、ログイン済みのスクレイピングプロファイルの検出率を6%以上向上させています。
Apache Beamにより、画期的なパフォーマンス向上を実現しました。不正利用処理時間は1日から5分に短縮されました。ログイン済みのスクレイピングプロファイルの検出率は6%以上向上しました。
通知プラットフォーム
ソーシャルメディアネットワークであるLinkedInは、会員エンゲージメントを促進するために、インスタント通知に大きく依存しています。これを達成するために、Apache BeamとApache Samzaは連携して、LinkedInの大規模な通知プラットフォームを支えています。このプラットフォームは、通知コンテンツの生成、ターゲットオーディエンスの特定、コンテンツのタイムリーかつ関連性の高い配信を保証します。
ストリーミングApache Beamパイプラインは、複雑なビジネスロジックを持ち、ニアリアルタイムで膨大な量のデータを処理します。パイプラインは、9億5000万人以上のLinkedIn会員からのイベントを消費、集約、パーティション化、処理し、そのデータをダウンストリームの機械学習モデルに供給します。MLモデルは、受信者会員の過去の行動に基づいて、毎秒数百万件規模の候補通知に対して分散ターゲティングとスケーラブルなスコアリングを行い、各通知について受信者向けにオンザフライでパーソナライズされた決定を行います。その結果、LinkedIn会員は、コネクションリクエスト、求人推薦、毎日のニュースダイジェスト、ソーシャルネットワーク内のその他の活動など、タイムリーで関連性があり、行動に基づいた通知を適切なチャネルを通じて受信します。
高度なApache Beam APIは、すぐに使える複雑な集約とフィルタリング機能を提供し、そのプログラミングモデルにより、再利用可能なコンポーネントの作成が可能です。これらの機能により、LinkedInは開発を迅速化し、SamzaからBeamパイプラインへの移行に伴い、通知プラットフォームのスケーリングを合理化することができます。
LinkedInのユーザーエンゲージメントは、関連性の高い通知をタイムリーに送信できるかどうかに大きく左右されます。Apache Beamは、このビジネスに不可欠なユースケースを支える、スケーラブルでニアリアルタイムのインフラストラクチャを実現しました。
リアルタイムMLフィーチャ生成
LinkedInの中核機能(求人推薦や検索フィードなど)は、企業、求人情報、会員など、様々なエンティティに関する数千の特徴量を消費するMLモデルに大きく依存しています。しかし、Apache Beamを採用する前は、元のオフラインML特徴量生成パイプラインでは、会員の行動とその行動が推薦システムに影響を与えるまでの間に24~48時間もの遅延がありました。この遅延により、システムは頻度の低い会員に関するデータが不足し、頻度の高い会員の短期的な意図や好みを捉えることができず、機会損失につながっていました。スケーラブルなリアルタイムML特徴量生成プラットフォームに対する需要の高まりを受け、LinkedInはApache Beamを活用してこの課題に取り組みました。
マネージドBeamを基盤として、LinkedInはML特徴量生成のためのホスト型プラットフォームを開発しました。このMLプラットフォームは、AIエンジニアにリアルタイムの特徴量と効率的なパイプラインオーサリングエクスペリエンスを提供する一方で、デプロイと運用上の複雑さを抽象化します。AIエンジニアは特徴量定義を作成し、マネージドBeamを使用してデプロイします。LinkedIn会員がプラットフォーム上でアクションを実行すると、ストリーミングApache Beamパイプラインは、Kafkaにリアルタイムで送信されたイベントをフィルタリング、処理、集約することで、より新しい機械学習特徴量を生成し、それらを特徴量ストアに書き込みます。さらに、LinkedInは、特徴量ストアからデータを取得し、処理して推薦システムに供給する他のApache Beamパイプラインも導入しました。
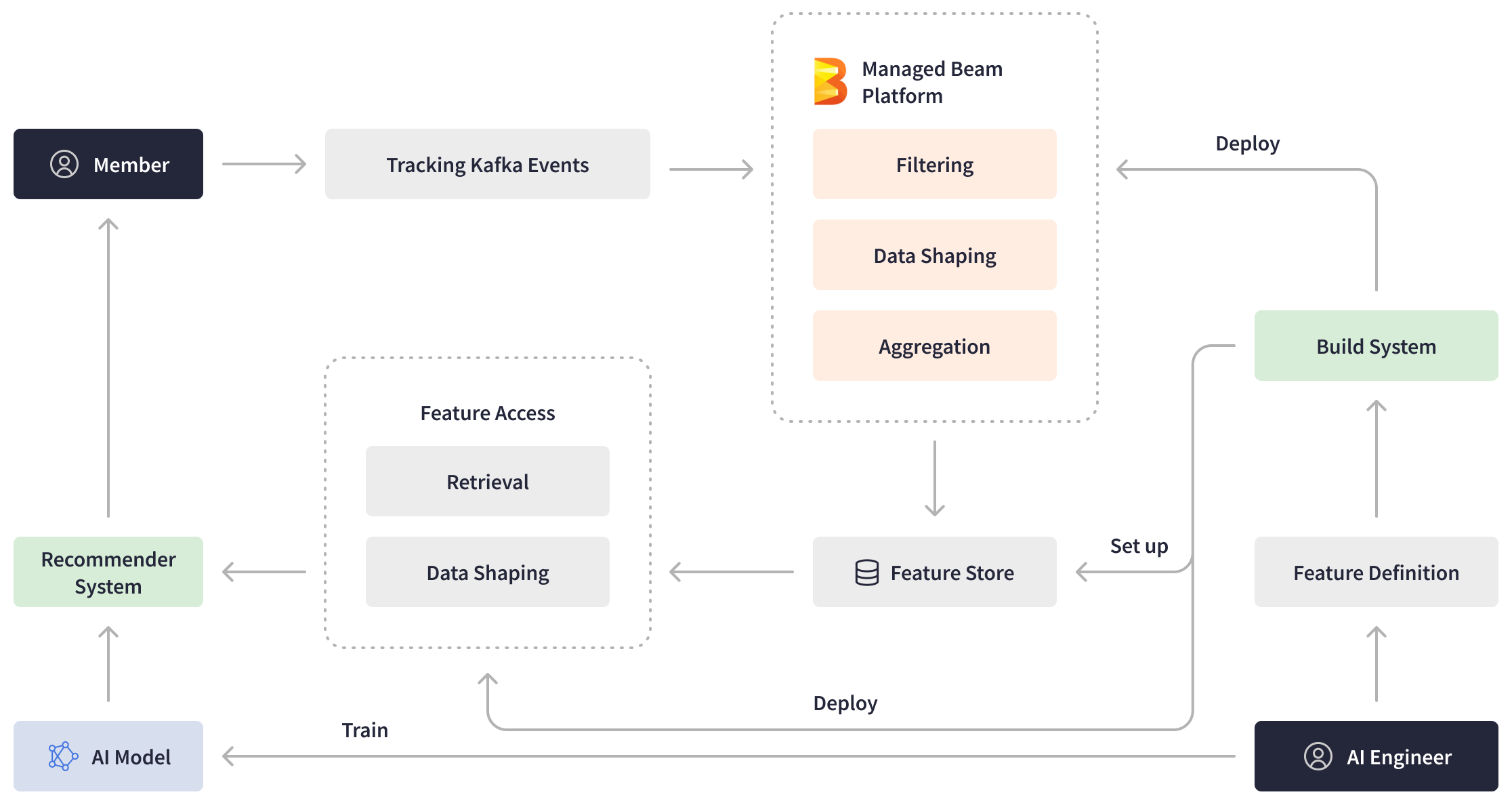
強力なApache Beamストリーム処理プラットフォームは、会員の行動とデータの可用性間の遅延を解消する上で重要な役割を果たし、わずか数秒という驚異的なエンドツーエンドのパイプラインレイテンシを実現しました。この大幅な改善により、LinkedInのMLモデルは最新の情報を活用し、会員にさらにパーソナライズされ、タイムリーな推奨を提供できるようになり、ビジネス指標の大幅な向上につながりました。
マネージドストリーム処理プラットフォーム
LinkedInのデータインフラストラクチャが3000を超えるApache Beamパイプラインを網羅し、多様なビジネスユースケースに対応するようになったため、LinkedInのAIおよびデータエンジニアリングチームは、これらのストリーミングアプリケーションを24時間体制で管理することに圧倒されました。AIエンジニアは、新しいパイプラインを作成する際に、複数のストリーミングツールとインフラストラクチャをフレームワークに統合することの複雑さ、デプロイ、監視、運用に関する基盤インフラストラクチャに関する知識の不足など、いくつかの技術的な課題に直面しました。これらの課題により、パイプライン開発サイクルは1~2ヶ月かかるという時間のかかるものになっていました。Apache Beamにより、LinkedInは、内部プロセスを合理化し自動化するために設計されたマネージドストリーム処理プラットフォームであるマネージドBeamを作成することができました。このプラットフォームにより、チームはオンコールサポートの負担を軽減しながら、高度なストリーミングアプリケーションの開発と運用をより簡単かつ迅速に行うことができます。
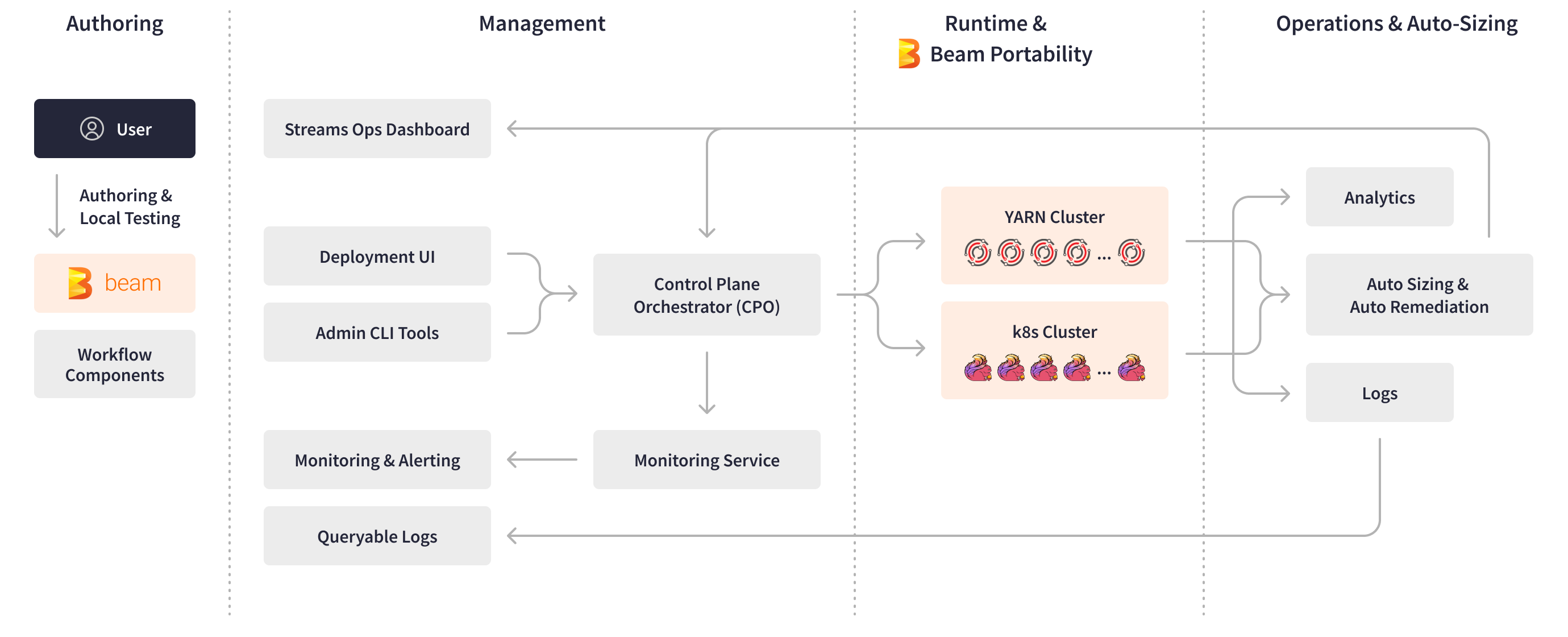
Apache Beam SDKにより、LinkedInのエンジニアはカスタムワークフローコンポーネントを再利用可能なサブDAG(Directed Acyclic Graph)として作成し、標準のPTransformとして公開することができました。これらのPTransformは、新しいパイプラインのためのすぐに使えるビルディングブロックとして機能し、LinkedInのAIエンジニアのオーサリングとテストのプロセスを大幅に高速化します。Apache Beamは基盤となるエンジンとランタイム環境の低レベルの詳細を抽象化することにより、エンジニアはビジネスロジックのみに集中できるようになり、開発時間をさらに短縮できます。
パイプラインがデプロイの準備ができると、マネージドBeamの中央制御プレーンが機能し、デプロイメントUI、運用ダッシュボード、管理ツール、自動化されたパイプラインライフサイクル管理などの重要な機能を提供します。
Apache Beamの抽象化により、ビルド、デプロイ、ランタイム時のフレームワークの進化からユーザーコードを分離することができました。マネージドBeamは、ランナープロセスとユーザー定義関数(UDF)の分離を確保するために、パイプラインビジネスロジックとフレームワークロジックを2つの別々のJARファイル(フレームワークレスアーティファクトとフレームワークアーティファクト)としてパッケージ化します。YARNクラスタでのパイプライン実行中、これらのパイプラインアーティファクトは、Samzaコンテナ内で2つの異なるプロセスとして実行され、gRPCを介して通信します。この設定により、LinkedInは、自動化されたフレームワークのアップグレード、スケーラブルなUDF実行、トラブルシューティングが容易なログの分離、多言語APIを活用し、柔軟性と効率性を向上させることができました。
Apache Beamは、マネージドBeamの自動サイズ調整コントローラーツールも支えています。このツールは、ハードウェアリソースの調整を自動化し、ストリーミングパイプラインの自動修復を提供します。ストリーミングApache Beamパイプラインは、メトリクスや主要なデプロイメントログなどの診断情報をKafkaトピックの形式で自己報告します。さらに、LinkedInの内部監視ツールは、ハートビートの失敗、メモリ不足イベント、処理遅延などのランタイムエラーを報告します。Apache Beam診断プロセッサパイプラインは、これらの診断イベントを集約、再パーティション化、ウィンドウ化してから、自動サイズ調整コントローラーに渡し、LinkedInのマネージドBeamの運用および分析ダッシュボード用のOLAPストアであるApache Pinotに書き込みます。前処理され、時間ウィンドウ化された診断データに基づいて、自動サイズ調整コントローラーはサイズ変更アクションまたは再起動アクションを生成し、それらをマネージドBeam制御プレーンに転送します。マネージドBeam制御プレーンは、その後、LinkedInのストリーミングアプリケーションとクラスタをスケーリングします。
Apache Beamは運用管理を合理化し、完全に自動化された自動スケーリングを実現することで、新しいアプリケーションのオンボーディング時間を大幅に短縮しました。以前は、オンボーディングには多くの手動による「試行錯誤」と内部システムとメトリクスに関する深い知識が必要でした。
Apache Beamの拡張性、プラグイン可能性、移植性、抽象化は、LinkedInのマネージドBeamプラットフォームの基盤を形成しています。マネージドBeamプラットフォームは、ストリーミングパイプラインの作成、テスト、安定化にかかる時間を数ヶ月から数日に短縮し、迅速な実験を促進し、AIエンジニアの運用コストをほぼ完全に排除しました。
まとめ
Apache Beamは、LinkedInのデータインフラストラクチャの変革とスケーリングにおいて重要な役割を果たしました。Beamの強力なストリーミング機能により、3000を超えるパイプラインを介して毎日4兆件を超えるイベントを処理する、重要なビジネスユースケースのリアルタイム処理が可能になりました。
Apache Beamの汎用性により、LinkedInのエンジニアリングチームは、様々なビジネスユースケースに合わせてデータ処理を最適化することができました。
- Apache Beamの統一されたポータブルなフレームワークにより、LinkedInはストリーミング処理とバッチ処理を統一されたパイプラインに統合することができました。これらの統一されたパイプラインは、サービスコストを2倍、処理パフォーマンスを2倍、メモリとCPUの使用効率を2倍向上させました。
- LinkedInの不正利用対策プラットフォームは、Apache Beamを活用してKafkaからのユーザーアクティビティイベントをニアリアルタイムで処理し、不正行為のラベル付けにかかる時間を数日から数分に大幅に短縮しました。ニアライン防御は、スクレイピング開始後数分以内にスクレイパーを検出することができ、ログイン済みのスクレイピングプロファイルの検出率を6%以上向上させています。
- Apache Beamを採用することで、LinkedInは、24~48時間の遅延のあるオフラインML特徴量生成パイプラインから、エンドツーエンドのパイプラインレイテンシがミリ秒または秒レベルのリアルタイムプラットフォームに移行することができました。
- Apache Beamの抽象化と強力なプログラミングモデルにより、LinkedInは完全に管理されたストリーム処理プラットフォームを作成することができ、新しいパイプラインの作成、テスト、デプロイが容易になり、本番環境への導入時間が数ヶ月から数日に短縮されました。
Apache Beamはシームレスなプラグアンドプレイ機能を備えており、Apache Kafka、Apache Pinot、その他のLinkedInの中核テクノロジーとスムーズに統合され、大規模なパフォーマンスを確保しています。LinkedInが新しいエンジンやツールを試行し続ける中、Apache Beamの移植性により、基盤となるインフラストラクチャの変化に対するエコシステムの将来性が確保されます。
ビジネスに不可欠なユースケースを支えるスケーラブルでニアリアルタイムのインフラストラクチャを実現することにより、Apache BeamはLinkedInが最新のデータを活用し、リアルタイムで処理してタイムリーな推奨とパーソナライズされたエクスペリエンスを作成することを可能にし、最終的には世界中の9億5000万人以上のLinkedIn会員に恩恵をもたらします。
この情報は役に立ちましたか?