




「私たちのデータ量は膨大で、Apache Beamはそれを管理しやすくするのに役立っています。1日数百万件の取引ごとに、将来の時間増分を詳細に分析した市場価値変動のシミュレーションを生成し、複数の考えられる市場シナリオをスキャンすることで、この膨大なデータを意味のある統計に集約します。Apache Beamは、それらすべてのデータを活用し、データの分散を以前よりもはるかに容易にします。」

「Apache Beam Python SDKは、HSBCのモデル開発チームがPythonで記述されたパイプラインにおけるビジネスロジックワークフローのノード間の高度な数学的依存関係を簡単にエミュレートできる方法を提供することにより、オーケストレーションレベルに数学を取り入れました。以前は、本番環境に小さな変更であっても展開するのに少なくとも6か月を費やしていました。Apache Beamによって推進される新しいチーム構造により、今では1週間以内に変更を展開できます。」

HSBCにおけるApache Beamを用いた高性能定量的リスク分析
背景
HSBCホールディングスplc(HSBCの親会社)はロンドンに本社を置いています。HSBCは、62の国と地域にあるオフィスから世界中の顧客にサービスを提供しています。2023年3月31日現在、資産総額は2兆9,900億ドルで、HSBCは世界最大の銀行および金融サービス組織の1つです。グローバルバンキング&マーケッツ事業は、多国籍企業、政府、金融機関に幅広い金融サービスと製品を提供しています。
HSBCのXVAおよびCCR資本分析担当VPであるChup Cheng氏と主席アシスタントバイスプレジデントであるAndrzej Golonka氏は、Apache Beamが計算プラットフォームおよびリスクエンジンとしてどのように機能し、HSBCが顧客の投資ポートフォリオ全体でカウンターパーティー信用リスクとXVAを管理するのに役立つかを共有しました。これは、毎日多数のカウンターパーティー間で行われる数兆ドル規模の取引量から生じるものです。Apache Beamにより、HSBCは既存のC++ HPCワークロードをバッチApache Beamパイプラインに統合し、データ分散を合理化し、処理性能を向上させることができました。Apache Beamはまた、以前は不可能だった新しいパイプラインを可能にし、開発効率を向上させました。
大規模なリスク管理
HSBCにおけるApache Beamを活用したデータ処理の規模と価値を理解するために、金融機関におけるカウンターパーティー信用リスク計算が特に極端な計算能力を必要とする理由を詳しく見ていきましょう。
投資ポートフォリオの価値は金融市場とともに変動し、さまざまな外部要因の影響を受けます。リスクを中和し、規制で要求される資本準備金を決定するために、投資銀行はリスクエクスポージャーを推定し、個々の取引やポートフォリオの価値に相当する調整を行う必要があります。XVA(X-Value Adjustment)モデルは、金融業界におけるカウンターパーティー信用リスクの分析において重要な役割を果たしており、信用評価調整(CVA)、資金調達評価調整(FVA)、資本評価調整(KVA)などのさまざまな評価調整を網羅しています。XVAの計算には、考えられる将来のシナリオに基づいてリスクを考慮するための複雑なモデル、多層マトリックス、モンテカルロシミュレーションが関与します。評価関数は、最大70年という特定の期間における可能性のある取引価値を表す複数の確率微分方程式(SDE)マトリックスを処理し、将来のシナリオに応じて金融資産の現在の市場価値の分布を表すMTM(時価)マトリックスを出力します。圧縮されたMTMマトリックスは、将来のリスクエクスポージャーのベクトルと必要なXVA調整を決定します。
XVA計算には、広範なマトリックスデータと長い時間範囲が関与するため、膨大な計算能力が必要です。1つの取引のMTMマトリックスを計算するために、評価関数は、数メガバイトの重みを持ち、それぞれ数十万の要素を含む複数のSDEマトリックスを数十万回反復する必要があります。
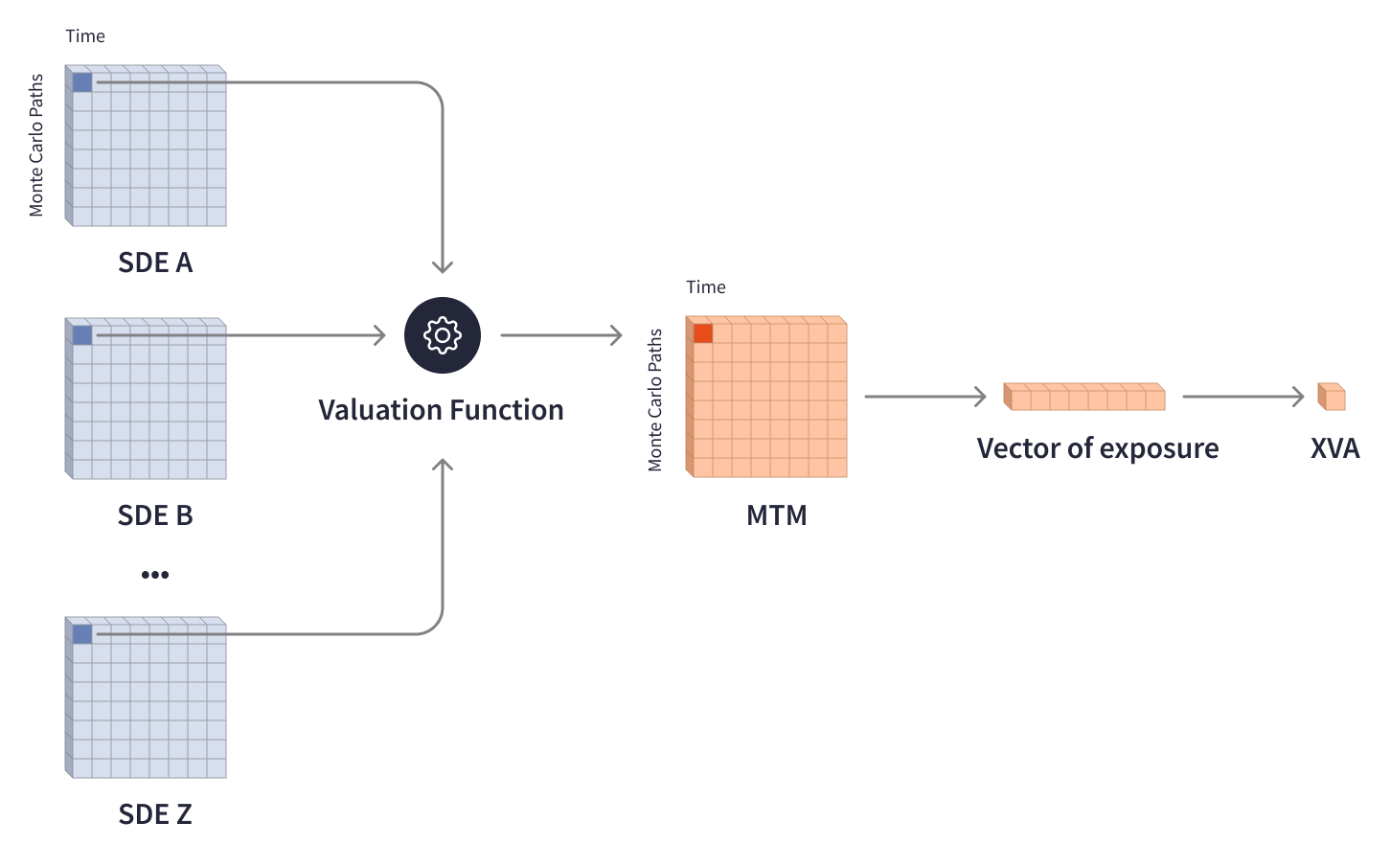
複数のカウンターパーティーのポートフォリオでXVAを計算するには、方程式の大規模システムでさらに複雑な計算が必要です。評価関数は、数百GBのSDEマトリックスを処理し、数百万の取引レベルのMTMマトリックスを生成し、それらをカウンターパーティーレベルのマトリックスに集約し、次に各カウンターパーティーの将来のエクスポージャーとXVAを計算します。
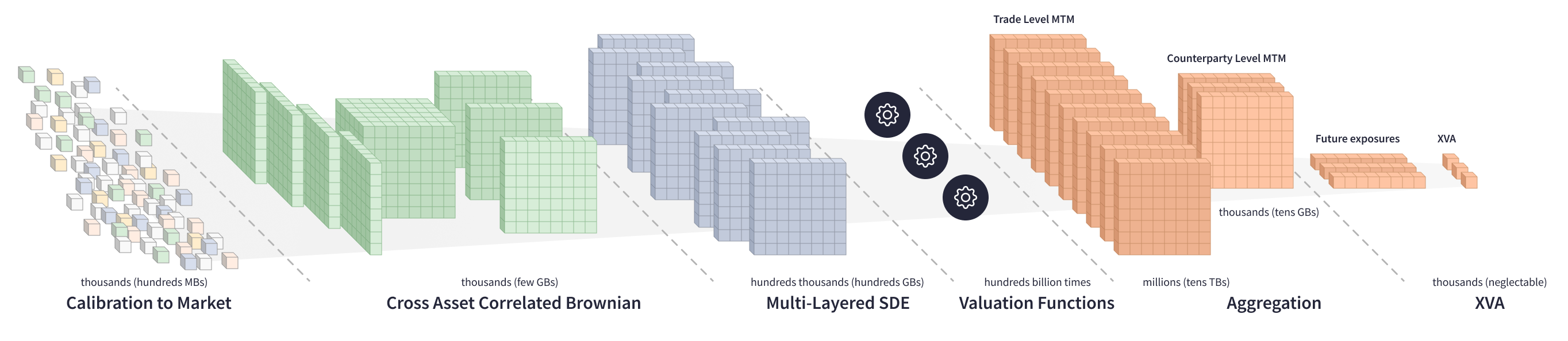
多数の市場要因に対するXVAの感度を扱う場合、技術的な課題はさらに大きくなります。投資銀行は、カウンターパーティーポートフォリオ全体ですべての市場リスクを中和するために、数百の市場要因に対するXVAの感度を計算する必要があります。XVAの感度を計算する主な方法は2つあります。
- 入力への逆伝播による解析的な方法
- XVAの勾配の動きを観察する数値的な方法
XVAの分散を得るために、評価関数は、膨大な方程式系を数百億回反復する必要があり、これは非常に計算集約的なプロセスです。
XVAモデルは、金融業界におけるカウンターパーティー信用リスクを理解するために不可欠であり、その正確な計算は、デリバティブの全価格を評価するために不可欠です。膨大な量のデータと複雑な計算が関与するため、これらの計算を効率的かつタイムリーに実行することは、トレーダーが十分な情報に基づいた意思決定を行うために不可欠です。
Beamへの移行
NOLAは、XVA計算のためのHSBCの内部データインフラストラクチャです。以前のバージョンであるNOLA1は、オンプレミスソリューションであり、メディアとして10TBのファイルサーバーを使用し、単一のバッチで数ペタバイトのデータを処理し、方程式の各システム内の相互依存性の巨大なネットワークを通過し、その後プロセスを繰り返していました。HSBCのモデル開発チームは新しい統計モデルを作成し、定量的ライブラリを構築していましたが、ITチームはライブラリに必要なデータをフェッチしており、両方のチームが協力して方程式システム間のオーケストレーションをレイアウトしていました。
2007年から2008年の金融危機は、業界全体でXVAの堅牢で効率的な計算の必要性を浮き彫りにし、金融セクターに追加の規制を導入し、指数関数的に増加する量の計算が必要になりました。そのため、HSBCは数百の市場要因に対するXVAの感度を計算するための数値解を求めました。単一のバッチでデータを処理することがブロッカーとなり、スループットのボトルネックとなっていました。NOLA1インフラストラクチャとその集中的なI/O利用は、(当時)スケーリングに適していませんでした。
HSBCのエンジニアは、データ処理のスケーリング、スループットの最大化、重要なビジネスのタイムラインの達成を可能にする新しいアプローチを探し始めました。
その後、HSBCのエンジニアリングチームは、そのスケーラビリティ、柔軟性、大量のデータを並列で処理する能力のために、Apache BeamをNOLAのリスクエンジンとして選択しました。彼らは、Apache BeamがXVA計算の変換的な有向非巡回グラフプロセスの自然なプロセス実行者であることを発見しました。Apache Beam Python SDKは、Pythonで新しいデータパイプラインを構築するための簡単なAPIを提供し、その抽象化はC++で普及している分析を再利用する方法を提供しました。さまざまなApache Beamランナーは移植性を提供し、HSBCのエンジニアは、Apache FlinkとCloud Dataflowで実行されるApache Beamパイプラインを使用して、データインフラストラクチャの新しいバージョンであるNOLA2を構築しました。
データ分散の容易化
Apache Beamは、XVA計算のデータ分散を大幅に簡素化し、ワーカー間の分散処理を使用して相互に関連するモンテカルロシミュレーションを処理することを可能にしました。
Apache Beam SDKを使用すると、ユーザーは表現力豊かなDAGを構築し、並列パイプライン化されたステージをサイド入力または結合を使用して再結合できるストリームまたはバッチの複数ステージパイプラインを簡単に作成できます。データの移動はランナーによって処理され、データは不変の並列要素コレクションであるPCollectionオブジェクトとして表現されます。
Apache Beamは、C++コンポーネントを分散するためのいくつかの方法を提供します。
- C++コンポーネントをカスタムワーカーコンテナイメージ(たとえば、カスタムApache BeamまたはCloud Dataflowコンテナ)にサイドロードし、DoFnを使用してすぐにC++コンポーネントと対話します。
- Apache BeamでJARファイルにC++をバンドルします。ここで、C++要素(バイナリ、構成など)は、DoFnのセットアップ/ティアダウンプロセス中にローカルディスクに抽出されます。
- PCollectionにC++コンポーネントをサイド入力として含め、ローカルディスクに展開します。
Apache BeamとC++のシームレスな統合により、HSBCのエンジニアは、普及している分析(NAGおよびMKLライブラリに依存)を再利用し、ユースケースと展開環境に応じてロジック分散方法を選択することができました。HSBCは、PCollectionがJavaまたはPythonパイプラインからC++ライブラリへの呼び出しと入力データを含む場合、データ交換にプロトコルバッファが特に役立つことを発見しました。プロトコルバッファデータは、ディスク、ネットワーク、またはpybind11などのツールを使用して直接共有できます。
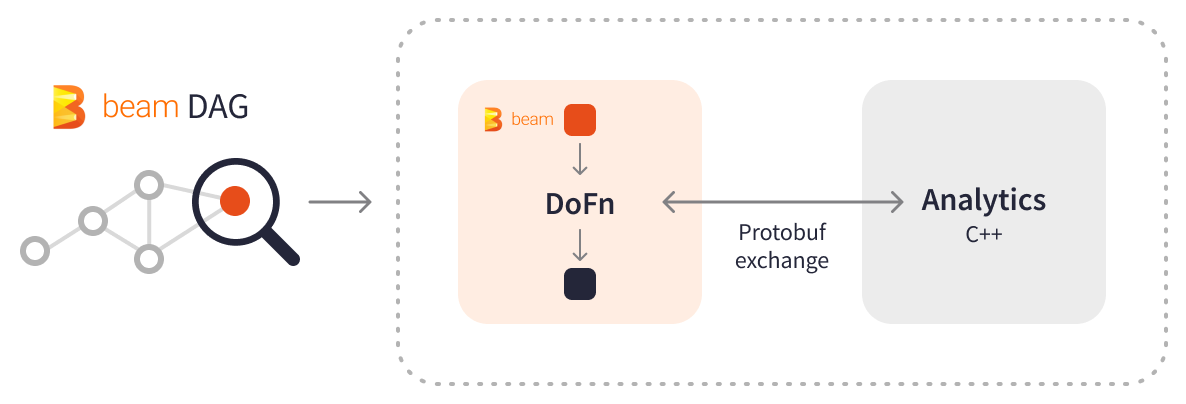
HSBCは、XVA計算をバッチApache Beamパイプラインに移行しました。毎日、XVAパイプラインはわずか1時間で数千億の評価を計算し、約2GBの外部入力データを使用し、方程式システム内で10〜20TBのデータを処理し、約4GBの出力レポートを生成します。Apache Beamは、XVA計算をタスクを含む複数のPCollectionに分散し、必要な変換を独立して並列に実行し、マップリダクションの結果を生成します—すべて1パスで。
Apache Beamは、強力なトランスフォームとオーケストレーション機能を提供し、HSBCのエンジニアがXVA感応度計算に対する分析アプローチを最適化し、それまで不可能だった数値的なアプローチを可能にしました。方程式系全体を評価関数で反復処理する代わりに、HSBCのエンジニアは方程式系を計算グラフとして扱い、再利用可能な要素を持つクラスタに分割し、最小限の計算グラフを反復処理します。彼らはApache Beamのオーケストレーションを使用して、C++の「実行可能ファイル」を呼び出すことで、ポートフォリオごとに数万ものクラスタを効率的に処理します。KV PCollectionを使用して複数の市場要因をバンドルし、PCollectionの各入力要素をキーに関連付け、単一のApache Beamバッチパイプライン内で数百の市場要因に対するXVA感応度を計算します。
分析的および数値的XVA感応度計算を実行するApache Beamパイプラインは、2つの別々のバッチで毎日実行されます。真夜中に実行される最初のバッチパイプラインは、トレーダーの信用枠消費と資本利用率を決定し、翌日の取引量に直接影響を与えます。午前8時までに完了する2番目のバッチは、トレーダーのリスク管理とヘッジ戦略に影響を与える可能性のあるXVA感応度を計算します。パイプラインは毎日約2GBの外部市場データを使用し、方程式系で最大400TBの内部データを処理し、データを約4GBの出力レポートに集約します。毎月末には、方程式系内で5PBを超える月次データを処理して、包括的なXVA感応度レポートを作成します。Apache Beamはデータ分散とホットスポットの問題に対処し、複雑な計算に関与するデータの管理を支援します。
Apache Beamは、HSBCに従来のリスクエンジンと同等の機能、さらにはそれ以上の機能を提供し、インフラストラクチャのスケーリングと分散処理によるスループットの最大化を可能にします。
Apache Beamにより、データ分散が以前よりもはるかに容易になりました。モンテカルロ法は、処理するデータ量を大幅に増加させます。Apache Beamは、そのデータ量すべてを活用するのに役立ちました。
プラットフォームとしてのBeam
Apache Beamは、単なるデータ処理フレームワークではありません。実験を可能にし、新規開発の市場投入までの時間を短縮し、展開を簡素化する計算プラットフォームでもあります。
PCollectionとしてのApache Beamのデータセット抽象化により、コンポーネントの所有権を整理し、組織間の依存関係とボトルネックを削減することで、HSBCのモデル開発効率が向上しました。モデル開発チームは、データパイプラインを所有し、新しい方程式系を実装し、ブラックボックスモードで方程式系内のデータ転送を定義し、ITチームに送信します。ITチームは、方程式系全体に必要な外部データをフェッチ、制御、およびオーケストレーションします。
一般的に、本番環境に小さな変更でも展開するには、少なくとも6ヶ月かかっていました。Apache Beam主導の新しいチーム構造により、変更を1週間以内に展開できるようになりました。
Apache Beamの統合プログラミングモデルによって提供される抽象化を活用することで、HSBCのモデル開発チームは、シームレスに新しいデータパイプラインを作成し、適切なランナーを選択し、基盤となるインフラストラクチャなしでビッグデータで実験を行うことができます。Apache Beamモデルルールは、実験用コードの高品質を保証し、本番レベルのパイプラインを容易に実験から本番に移行できるようにします。
Apache Beamを使用すると、「もし〜だったら」という疑問を簡単に実験できます。パラメーターを変更した場合の影響を知りたい場合は、単純なApache Beamコードを作成し、パイプラインを実行して、数分以内に回答を得ることができます。
モンテカルロシミュレーションとカウンターパーティー信用リスク分析におけるApache Beamの主要な利点の1つは、同じ複雑なシミュレーションロジックを、オンプレミスまたはクラウドのさまざまな環境で、さまざまなランナーを使用して実行できることです。この柔軟性は、機密性の高い財務データと情報をローカルの範囲外に転送できない、さまざまな国やコンプライアンスゾーンでのローカルリスク分析が必要な状況において特に重要です。Apache Beamを使用すると、HSBCはランナーを容易に切り替えることができ、あらゆる変更に対応してデータ処理の将来性を確保できます。HSBCは、ワークフローの大部分をCloud Dataflowで実行しており、その強力なマネージドサービスと自動スケーリング機能を活用して、1日に2回バッチパイプラインを実行する際の最大18,000 vCPUのスパイクを管理しています。一部の国では、Apache Beam Flinkランナーを使用して、データストレージと処理に関するローカル規制に準拠しています。
成果
Apache Beamは膨大な量の金融市場データと指標を活用し、70年間にわたる可能性のある将来のシナリオをスキャンするための数十億件の取引評価を生成し、それらを意味のある統計に集約することで、HSBCが将来のシナリオをモデル化し、予測と意思決定におけるリスクを定量的に考慮することを可能にします。
Apache Beamを使用することで、HSBCのエンジニアはデータ処理のパフォーマンスを2倍に向上させ、元のソリューションと比較してXVAバッチパイプラインを100倍にスケールアップしました。Apache Beamの抽象化により、これまで不可能だったXVA感応度計算の数値的手法を本番環境で実装する方法が開かれました。バッチApache Beamパイプラインは、毎日約400TBの内部データと月に一度最大5PBのデータを処理し、数百の市場要因に対するXVA感応度を計算します。
Apache Beamの移植性により、HSBCはローカルのデータ処理要件に応じて異なる地域で異なるランナーを使用し、規制変更に対応してデータ処理の将来性を確保できました。
Apache Beamは、高度に最適化されたC++の計算コンポーネントとのシームレスな統合とすぐに使用できる相互作用を提供し、HSBCは長年にわたって蓄積されたC++分析をPythonに書き直す必要性を省くことができました。
Apache Beam Python SDKは、HSBCのモデル開発チームが新しいPythonパイプラインを簡単に構築できるようにすることで、オーケストレーションレベルに数学を取り入れました。Apache Beam主導の新しいワーク構造により、市場投入までの時間が24倍高速化され、HSBCのチームは数週間で変更と新しいモデルを本番環境に展開できるようになりました。
金融機関は、大規模な微分方程式系とモンテカルロシミュレーションを処理する直接非巡回グラフを計算するためのApache Beamの汎用性とスケーラビリティを活用することで、ローカライズされた分析とデータセキュリティ規制への厳格な準拠が必要な状況でも、カウンターパーティー信用リスクを効率的に評価および管理できます。
詳細情報
この情報は役に立ちましたか?