




「Apache Beamは私たちにとって理想的なソリューションでした。スケーリング、履歴データのバックフィル、新しいMLモデルやユースケースの実験…すべてBeamで非常に簡単に実行できます。」

「Apache Beamは、データサイエンティスト向けのセルフサービスMLを実現しました。彼らはコードの一部をプラグインすることができ、これらの変換はエンジニアリングの介入なしに自動的にモデルにアタッチされます。数秒以内に、データサイエンスチームは実験から本番に移行できます。」

セルフサービスの機械学習ワークフローとApache BeamによるMLOpsのスケーリング
背景
Credit Karma は、2007年に設立されたアメリカの多国籍個人金融会社であり、現在はIntuitの一部です。無料のクレジットおよび財務管理プラットフォームを備えたCredit Karmaは、パーソナライズされた財務の洞察と推奨事項を提供することにより、約1億3000万人のメンバーの財務の進捗を可能にします。
Credit Karmaのデータサイエンスおよびエンジニアリングチームは、機械学習を使用して、各メンバーの財務プロファイルと目標に合わせて最適化された、最も関連性の高いコンテンツとオファーをメンバーに提供します。Credit KarmaのシニアデータエンジニアであるAvneesh PratapとRaj Katakamは、Apache Beamが堅牢で回復力がありスケーラブルなデータおよびMLインフラストラクチャを構築するのにどのように役立ったかを共有しました。また、統合されたApache Beamデータ処理により、新しいMLパイプラインの実験と本番環境へのデプロイのギャップがどのように縮小されるかについても詳しく説明しました。
MLOpsの民主化とスケーリング
2018年以前は、Credit KarmaはPHPベースのETLパイプラインを使用して、複数の金融サービスパートナーからデータを取り込み、さまざまな変換を実行し、出力を独自のデータウェアハウスに記録していました。パートナーとメンバーの数が増え続けるにつれて、Credit Karmaのデータチームは、MLOpsのスケーリングに課題を感じていました。変更を加えたり、新しいパイプラインや属性を試したりするには、かなりのエンジニアリングオーバーヘッドが必要でした。たとえば、新しいパートナーをオンボーディングするだけでも数週間かかりました。データエンジニアリングチームは、データの取り込みとMLモデルのスコアリング時のパフォーマンスの欠点を克服し、同じパイプライン内で新しい機能をバックフィルする方法を探していました。 2018年、Credit Karmaは、成長する規模に対応し、メンバーをよりよく理解し、高度にパーソナライズされたオファーへのエンゲージメントを高めるために、新しいデータおよびMLプラットフォームであるVegaの設計を開始しました。
統合分散処理の業界標準であるApache Beamは、Vegaの中核に配置されています。
Apache Beamの調査を開始したとき、このプログラミングモデルは非常に有望であることがわかりました。最初に、1つのパートナーだけを[Apache Beamパイプラインに]移行しました。結果に非常に感銘を受け、すぐに他のパートナーパイプラインに移行しました。
Apache Beam Dataflowランナーを使用することで、Credit KarmaはGoogle Cloud Dataflowマネージドサービスの恩恵を受け、スケーラビリティと効率の向上を実現しました。Apache Beamの組み込みI/Oコネクタは、さまざまなシンクとソースをネイティブにサポートしているため、Credit KarmaはPub/Sub、BigQuery、Cloud StorageなどのさまざまなGoogle CloudツールやサービスとBeamをシームレスに統合できました。
Credit Karmaは、Apache BeamカーネルとJupyter Notebookを活用して、Vegaに探索的環境を作成し、データサイエンティストがエンジニアリングの介入なしに新しい実験データパイプラインを作成できるようにしました。
Credit Karmaのデータサイエンティストは、主にSQLとPythonを使用して新しいパイプラインを作成します。Apache Beamは、JavaまたはScalaでスカラー関数または集約関数を記述し、SQLクエリでそれらを呼び出すことができる、多言語機能を備えた強力なユーザー定義関数を提供します。データサイエンスチームのScala変換を民主化するために、Credit Karmaのエンジニアは、UDF、Tensorflow Transforms、および多数のコンポーネントを含むその他の複雑な変換を抽象化し、再利用可能で共有可能な「ビルディングブロック」を作成して、Credit KarmaのデータおよびMLプラットフォームを作成しました。Apache Beamとカスタム抽象化により、データサイエンティストは実験的なパイプラインと変換を作成するときにこれらのコンポーネントを操作できます。これらは、ステージング環境と本番環境で簡単に再現できます。Credit Karmaのデータサイエンスチームは、コードの変更を共通のGitHubリポジトリにコミットし、パイプラインはステージング環境にマージされ、本番アプリケーションに結合されます。
Apache Beamの抽象化レイヤーは、財務情報や機密情報を扱う場合、仮説や実験を本番パイプラインに運用化する上で重要な役割を果たします。Apache Beamを使用すると、データをデータウェアハウスに書き込む前に、データパイプライン内でデータをマスキングおよびフィルタリングできます。Credit Karmaは、Apache Thriftアノテーションを使用して列メタデータをラベル付けし、Apache Beamパイプラインは、データウェアハウスに到達する前に、Thriftアノテーションに基づいてデータから特定の要素をフィルタリングします。Credit Karmaのデータサイエンスチームは、利用可能な抽象化を使用するか、その上にデータ変換を記述して、新しいメトリックを計算し、実際のデータを見ずにMLモデルを検証できます。
Apache Beamは、財務面と非開示情報を「ブラックボックス化」するのに役立ったため、チームはすべてのデータにアクセスすることなく、コストと財務を扱うことができます。
現在、約20のApache Beamパイプラインが本番環境で実行されており、100を超える実験パイプラインが進行中です。今後の実験パイプラインの多くは、Apache Beamのステートフル処理を活用して、データウェアハウスで計算する代わりに、ストリーミングパイプライン内でユーザー集計を計算します。Credit Karmaのデータサイエンスチームは、Beam SQLを活用して、ストリーム処理パイプライン内でSQL構文を直接使用し、集計を簡単に作成することも計画しています。Apache Beamによる実行エンジンの抽象化とさまざまなランナーにより、Credit Karmaはモックデータで異なるエンジンを使用してデータパイプラインのパフォーマンスをテストし、ベンチマークを作成し、異なるデータエコシステムの結果を比較して、特定のユースケースに応じてパフォーマンスを最適化できます。
ストリームとバッチデータの統合取り込み
Apache Beamにより、Credit Karmaは最も重要なユースケースの1つであるデータ取り込みパイプラインを刷新することができました。多数のCredit Karmaパートナーは、ゲートウェイを介して金融商品とオファーに関するデータをPub/Subに送信し、ダウンストリーム処理を行います。 Scioで記述されたストリーミングApache Beamパイプラインは、リアルタイムでPub/Subトピックを使用し、深くネストされたJSONデータを処理して、データベース行形式にフラット化します。パイプラインはまた、データの構造化とパーティション化を行い、結果をBigQueryデータウェアハウスに書き込んでMLモデルのトレーニングを行います。
Apache Beamの統合プログラミングモデルは、バッチおよびストリーミングのユースケースのビジネスロジックを実行するため、Credit Karmaは1つの統一パイプラインを開発できました。データ取り込みパイプラインは、リアルタイムデータとバッチデータの両方の取り込みを処理して、パートナーからの履歴データをデータウェアハウスにバックフィルします。Credit Karmaのパートナーの中には、GCSやS3などのオブジェクトストアを使用して履歴データを送信するものもあれば、Pub/Subを使用するものもあります。Apache Beamは、ユースケースに応じて、同じパイプライン内で有界と非有界のPCollectionを作成することにより、バッチ処理とストリーム処理を統合します。バッチオブジェクトストアから読み取ると、有界PCollectionが作成されます。ストリーミングおよび継続的に更新されるPub/Subから読み取ると、非有界PCollectionが作成されます。過去のデータの新しい機能のみをバックフィルする場合、Credit Karmaのデータエンジニアリングチームは、同じストリーミングApache Beamパイプラインを構成して、パートナーからバッチ形式で送信された履歴データのチャンクを処理します。データセット全体を1回読み取り、特定のデータのデータと履歴データ要素を結合します。有限の長さのジョブの日付。
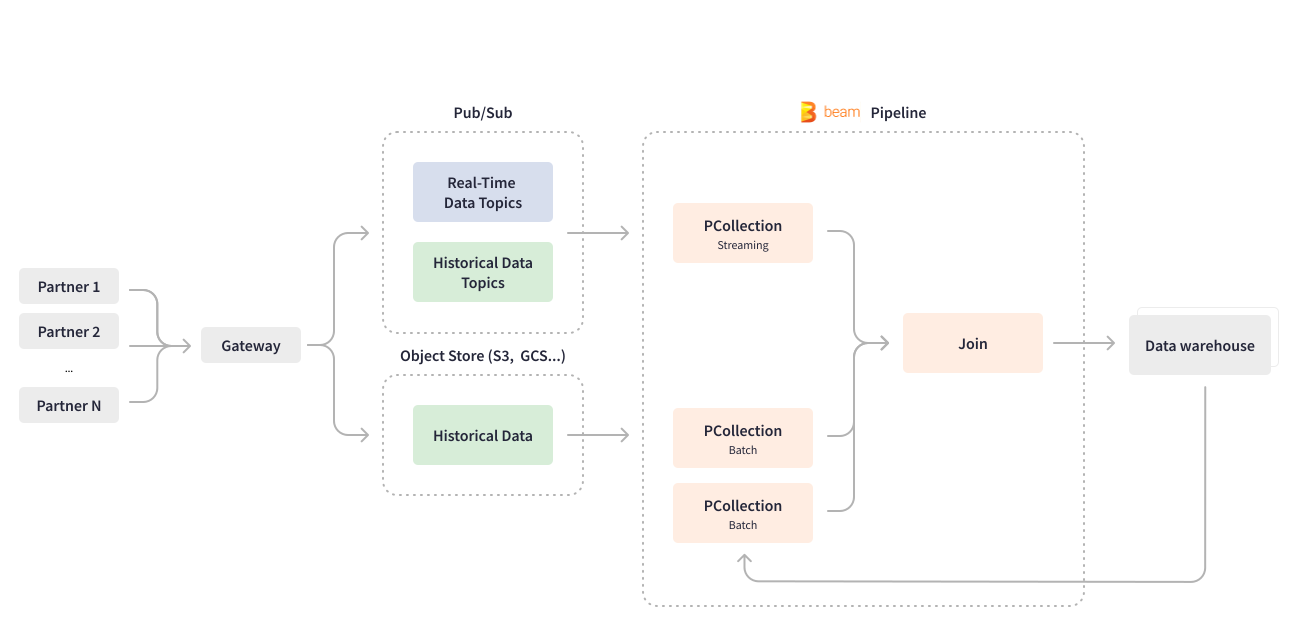
Apache Beamは柔軟性があり、その構造により、パイプラインコードを変更せずに新しいデータ属性、ソース、およびパートナーを追加するための汎用パイプラインコーディングと構成の容易さが実現します。Cloud Dataflowサービスは、進行中のストリーミングジョブを新しいパイプラインで動的に置き換えるなど、高度な機能を提供します。Apache Beam Dataflowランナーにより、Credit Karmaのデータエンジニアリングチームは、進行中のジョブをドレインすることなく、パイプラインコードの更新をデプロイできます。
Credit Karmaは、サードパーティのデータプロバイダーパートナーが内部の意思決定と予測のために独自のモデルをデプロイする方法を提供しています。これらのモデルの一部では、モデルのトレーニングのために過去3〜8か月間のカスタム属性をバックフィルする必要があり、これにより、データの急増が発生します。Apache Beamの抽象化レイヤーとそのDataflowランナーは、これらの定期的なスパイクを処理する際のインフラストラクチャ管理の労力を最小限に抑えるのに役立ちます。
Apache Beamを使用すると、複雑な処理ロジックを簡単に追加できます。たとえば、処理時間に設定可能なトリガーを追加できます。同時に、Dataflowランナーは実行を管理し、実行可能コードと依存関係を自動的にアップロードします。また、Dataflowの自動スケーリングはすぐに使用できます。水平方向のスケーリングについて心配する必要はありません。
現在、データ取り込みパイプラインは、定期的なバックフィルとともに1億を超えるメッセージを処理および変換します。これは、約5〜10 TBのデータに相当します。
セルフサービスの機械学習
Credit Karmaでは、データサイエンティストはデータのモデリングと分析を扱っており、新しいモデルを簡単に作成、テスト、デプロイできる能力と柔軟性を提供することが重要でした。Apache Beamは、データサイエンティストが効率的なMLエンジニアリングのために生の特徴空間に独自の変換を記述できるようにする抽象化を提供しながら、モデルサービングレイヤーをカスタムコードから独立させました。
Apache Beamは、Credit Karmaの機械学習ワークフローの自動化、モデルの連結とスコアリング、そしてMLモデル学習のためのデータ準備を支援しました。Apache Beamは、Beam DataFrame APIを提供することで、本番環境への迅速な反復に必要な前処理ステップの特定と実装を可能にします。Apache Beamに組み込まれたI/O変換により、TensorFlow TFRecordファイルのネイティブな読み書きが可能になり、Credit Karmaはこの接続性を活用してデータの前処理、モデルのスコアリング、そしてモデルスコアに基づいた金融商品やコンテンツの推奨を行っています。
Apache Beamにより、Credit Karmaは大規模なデータの前処理とモデル検証の両方を処理し、前処理中にデータを活用した実験を行うことができます。彼らは、バッチおよびリアルタイムのモデル推論におけるデータ変換にTensorFlow Transformsを使用しています。TensorFlow Transformsの出力はTensorFlowグラフとしてエクスポートされ、モデルに添付されるため、予測サービスはあらゆる変換から独立します。Credit Karmaは、データエンジニアリングチームの関与を必要とする集計データではなく、生データに対してオンザフライ変換を実行することで、予測サービスのアドホックな変更をオフロードすることができました。データサイエンティストは、SQLで生データに対してあらゆる種類の変換を記述し、インフラストラクチャを変更することなく新しいモデルをデプロイできるようになりました。
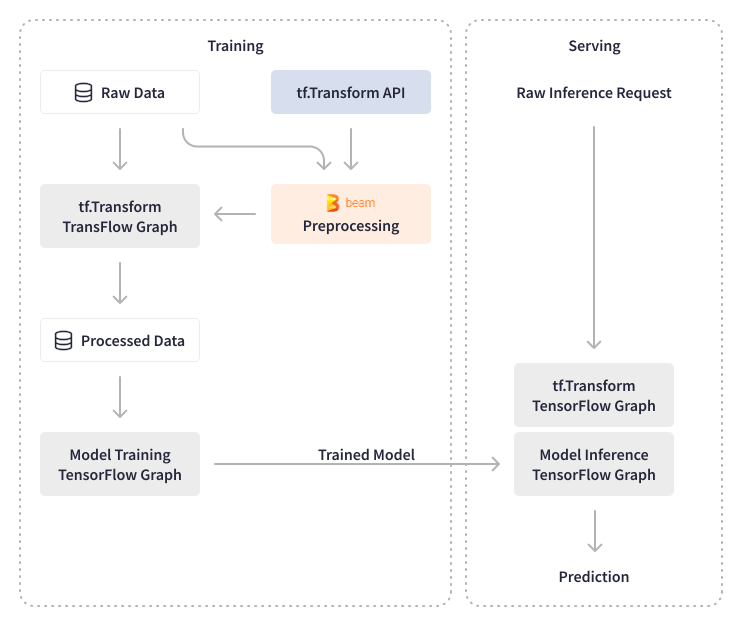
Apache Beamとカスタム抽象化により、Credit Karmaのデータサイエンスチームは、エンジニアリングのオーバーヘッドなしに、特にCredit Karmaの推奨を強化するための新しいモデルを作成できます。データサイエンティストによって作成されたコードは、自動的にAirflow DAGにコンパイルされ、ステージングサンドボックスにデプロイされ、その後本番環境にデプロイされます。モデルのトレーニングと推論の面では、Credit Karmaのデータエンジニアは、Apache Beam上に構築されたTensorflowライブラリ(TensorFlow Model Analysis(TFMA)およびTensorFlow Data Validation(TFDV))を使用して、MLモデルと機能の検証を実行し、MLモデルの自動更新を可能にします。モデル分析のために、彼らは統計を計算するためにネイティブのApache Beam変換を活用し、パフォーマンスと精度について新しいモデルを検証する内部ライブラリ変換を構築しました。たとえば、バッチApache Beamパイプラインは、MLモデルのアルゴリズム機能(スコア)を計算します。
Apache Beamは、データサイエンティスト向けのセルフサービスMLを実現しました。彼らはコードをプラグインするだけで、それらの変換はエンジニアの関与なしに自動的にモデルに添付されます。データサイエンスチームは、デプロイパスを変更するだけで、数秒以内にDAGを実験から本番環境に移行できます。
Apache Beamを搭載したMLパイプラインは非常に信頼性が高く、毎日1億件以上のイベントを処理し、最新のデータでMLモデルを更新しています。
リアルタイムデータ可用性の有効化
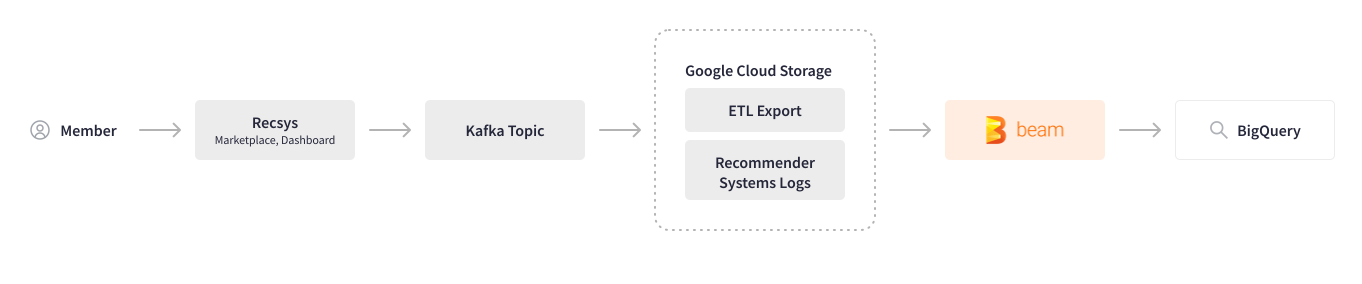
Credit Karmaは、機械学習を活用してユーザーの行動を分析し、最も関連性の高いオファーとコンテンツを推奨しています。Apache Beamを使用する前は、複数のシステムにわたるユーザーアクション(ログ)の収集には、無数の手動ステップと複数のツールが必要でした。そのため、処理パフォーマンスが低下し、変更が必要になるたびにチーム間でやり取りが発生していました。Apache Beamは、このロギングパイプラインの自動化に役立ちました。クロスシステムユーザーセッションログはKafkaトピックに記録され、Google Cloud Storageに保存されます。Scioで記述されたバッチApache Beamパイプラインは、特定の追跡IDのユーザーアクションを解析し、データを変換およびクレンジングし、BigQueryに書き込みます。
ロギングパイプラインをApache Beamに移行したことで、その速度とパフォーマンスに非常に満足しており、このバッチパイプラインをストリーミングパイプラインに変換することを計画しています。
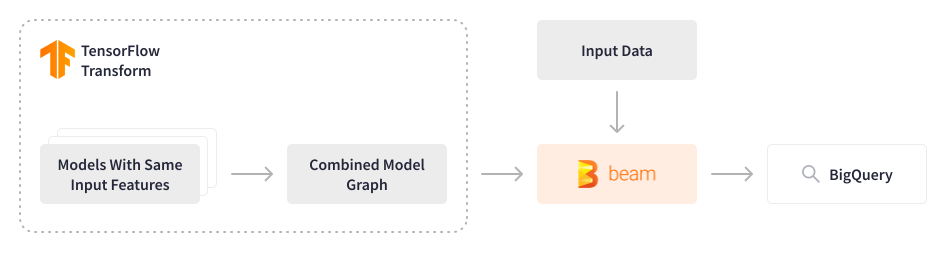
約1億3000万人のメンバー向けに推奨事項を提供し、データを処理するMLモデルのサブセットを使用して、Credit KarmaはFinOpsカルチャーを採用し、処理パフォーマンスを向上させながらインフラストラクチャコストを最適化する方法を継続的に模索しています。Credit Karmaで使用されているTensorflowモデルは、これまで入力機能が同じであっても一度に1つずつ順番にスコアリングされていたため、計算コストが過剰にかかっていました。
Apache Beamは、このアプローチを再考する機会を提供しました。データエンジニアリングチームは、複数のTensorflowモデルを単一の統合モデルに結合するApache Beamバッチパイプラインを開発し、過去3〜9か月(〜2〜3 TB)のデータを1秒あたり5,000イベントで処理し、出力をフィーチャストアに保存します。これらの機能は、メンバーがプラットフォームにログインした瞬間に関連コンテンツを推奨するためのリアルタイム予測のための軽量モデルで使用されます。この洗練されたソリューションにより、計算リソースを節約し、関連コストを大幅に削減しながら、処理パフォーマンスを向上させることができました。構成は動的であり、データサイエンティストは新しいモデルをシームレスに実験およびデプロイできます。
結果
Apache Beamは、Credit Karmaのデータエコシステムのスケーラビリティと回復力を将来にわたって保証し、200のMLモデルによって処理される20,000を超える機能を管理し、毎日約1億3000万人のメンバーに推奨事項を提供することを可能にしました。Apache Beamの導入以来、データ処理の規模は2倍に増加しましたが、データエンジニアリングチームはインフラストラクチャに大きな変更を加える必要はありませんでした。新しいパートナーのオンボーディングには、Apache Beamを使用する前に必要だった数週間と比較して、パイプラインに最小限の変更を加えるだけで済みます。Apache Beam取り込みパイプラインにより、ウェアハウスへのデータの読み込みが数日から1時間未満に短縮され、毎日約5〜10 TBのデータが処理されます。Apache Beamバッチスコアリングパイプラインは、履歴データを処理し、軽量MLモデルの機能を生成し、Credit Karmaメンバーにリアルタイムエクスペリエンスを提供します。
Apache Beamは、インフラストラクチャの低レベルの詳細を抽象化し、統合されたセルフサービスMLワークフローのためのデータ処理フレームワークを提供することにより、Credit Karmaにおけるエンドツーエンドのデータサイエンスプロセスと効率的なMLエンジニアリングへの道を開きました。Credit Karmaのデータサイエンティストは、エンジニアリングリソースやインフラストラクチャの変更を必要とせずに、新しいモデルを実験し、自動的に本番環境にデプロイできるようになりました。Credit Karmaは、セルフサービスデータおよびMLプラットフォームの構築とApache Beamを使用したMLOpsパイプラインのスケーリングの経験をBeam Summit 2022で発表しました。
影響
これらのスケーラビリティへの取り組みは、Credit Karmaがそのメンバーに透明性、選択、そしてパーソナライゼーションに基づいた金融体験を提供することを可能にします。特に経済が不確実な時期には、人々の経済状況は常に流動的であり、金融機関の消費者向け金融商品の承認基準も同様です。Credit Karmaがモデルの自動更新を含むデータエコシステムの規模を拡大し続けるにつれて、メンバーはCredit Karmaを使用する際に、承認される可能性を知ることによって、より自信を持って金融商品を購入できるという安心感を得ることができます。これにより、どんなに不確実な時代であっても、メンバーとパートナーの両方にとってwin-winのシナリオが生まれます。
詳細はこちら
Vega:Apache BeamとDataflowを使用したCredit KarmaでのMLOpsパイプラインのスケーリング
この情報は役に立ちましたか?