



ブログ
2016/05/27
私のPCollection.map()はどこ?
BeamがPCollectionにメソッドを持たせるのではなく、あらゆる操作にPTransformを持つ理由について疑問に思ったことはありませんか? この(およびその他の)設計決定に至った経緯を見てみましょう。
Beamは比較的新しいものですが、その設計は、実際のパイプラインに関する長年の経験に基づいています。主なインスピレーションの1つは、2009年に初めて導入されたMapReduceの後継であるGoogle社内のFlumeJavaです。
元のFlumeJava APIには、PCollectionに`count`や`parallelDo`などのメソッドがあります。少し簡潔ですが、このアプローチは拡張性に関して多くの欠点があります。FlumeJavaの新しいユーザーは皆、変換を追加したかったのですが、それらをPCollectionにメソッドとして追加するだけではうまくスケールしません。対照的に、BeamのPCollectionには、任意のPTransformを引数として取る単一の`apply`メソッドがあります。
| FlumeJava | Beam |
|---|---|
PCollection<T> input = …
PCollection<O> output = input.count()
.parallelDo(...);
| PCollection<T> input = …
PCollection<O> output = input.apply(Count.perElement())
.apply(ParDo.of(...));
|
これは、いくつかの理由でよりスケーラブルなアプローチです。
線引きはどこに?
PCollectionにメソッドを追加すると、この特別な扱いに値するほど「有用」な操作とそうでない操作の間に線を引くことを強制されます。フラットマップ、グループバイキー、コンバインパーキーの場合は簡単に説明できます。しかし、フィルターはどうでしょうか?カウント?近似カウント?近似分位数?最頻値?WriteToMyFavoriteSource?この道を進むと、やりたいことすべてを含む1つの巨大なクラスになってしまいます。(FlumeJavaのPCollectionクラスは、約70の異なる操作で5000行を超えており、すべての提案を受け入れていれば*はるかに*大きくなっていた可能性があります。)さらに、Javaではクラスにメソッドを追加できないため、PCollectionに追加される操作と追加されない操作の間には、明確な構文上の違いがあります。コードを共有する従来の方法は関数のライブラリを使用することですが、(少なくともJavaのような従来の言語では)関数はプレフィックススタイルで記述されるため、fluent builderスタイル(例:`input.operation1().operation2().operation3()`と`operation3(operation1(input).operation2())`)とはうまく調和しません。
代わりに、Beamでは、プリミティブ操作、SDKにバンドルされた複合操作、外部ライブラリの一部など、すべての変換を同等に扱うスタイルを選択しました。これにより、簡単に交換できる代替実装(異なるオプションを取る場合もあります)も容易になります。
| FlumeJava | Beam |
|---|---|
PCollection<O> output =
ExternalLibrary.doStuff(
MyLibrary.transform(input, myArgs)
.parallelDo(...),
externalLibArgs);
| PCollection<O> output = input
.apply(MyLibrary.transform(myArgs))
.apply(ParDo.of(...))
.apply(ExternalLibrary.doStuff(externalLibArgs));
|
設定可能性
値(PCollection)をオブジェクトとして渡し、操作する(つまり、遅延実行グラフへのハンドル)ことでfluentスタイルになりますが、構成可能で拡張可能である必要があるのは操作自体です。操作にPCollectionメソッドを使用すると、特にデフォルトの引数やキーワード引数がない言語では、うまくスケールしません。たとえば、ParDo操作には任意の数のサイド入力とサイド出力があり、書き込み操作にはエンコーディングと圧縮に関する構成がある場合があります。1つのオプションは、これらを複数のオーバーロードまたはメソッドに分割することですが、上記の問を悪化させます。(FlumeJavaは、`parallelDo`メソッドの12を超えるオーバーロードに進化しました!)別のオプションは、ビルダーパターンなどのよりfluentなイディオムを使用して構築できる構成オブジェクトを各メソッドに渡すことですが、その時点では、Beamが行うように、構成オブジェクトを操作自体にすることもできます。
型安全性
多くの操作は、要素が特定のタイプの coleção にのみ適用できます。たとえば、GroupByKey操作は`PCollection<KV<K, V>>`にのみ適用する必要があります。少なくともJavaでは、要素の型パラメーターだけでメソッドを制限することはできません。FlumeJavaでは、これはキーと値のペアのPCollectionに固有のすべての操作を含む`PCollection<KV<K, V>>`をサブクラス化する`PTable<K, V>`を追加するようになりました。これは、どの要素タイプがPCollectionサブクラスによってキャプチャされるほど特別なのかという同じ疑問につながります。サードパーティにとって拡張性がなく、多くの場合、手動のダウンキャスト/変換(Javaでは安全にチェーン化できない)と、これらのPCollectionの特殊化を生成する特別な操作が必要になります。
これは、出力の要素タイプが入力の要素タイプと同じ(または関連する)変換にとって特に不便であり、正しいサブクラスを生成するための追加のサポートが必要になります(例:PTableのフィルターは、キーと値のペアの生のPCollectionではなく、別のPTableを生成する必要があります)。
PTransformを使用すると、この問題全体を回避できます。入力のタイプに基づいて、変換を使用できるコンテキストに任意の制約を設けることができます。たとえば、GroupByKeyは、`PCollection<KV<K, V>>`にのみ適用するように静的に型付けされています。これが発生する方法は、PTableなどの特殊な型を導入する必要なく、任意の形状に一般化できます。
再利用性と構造
PTransformは一般的に使用されるサイトで構築されますが、それらを別々のオブジェクトとして引き出すことで、それらを保存して渡すことができます。
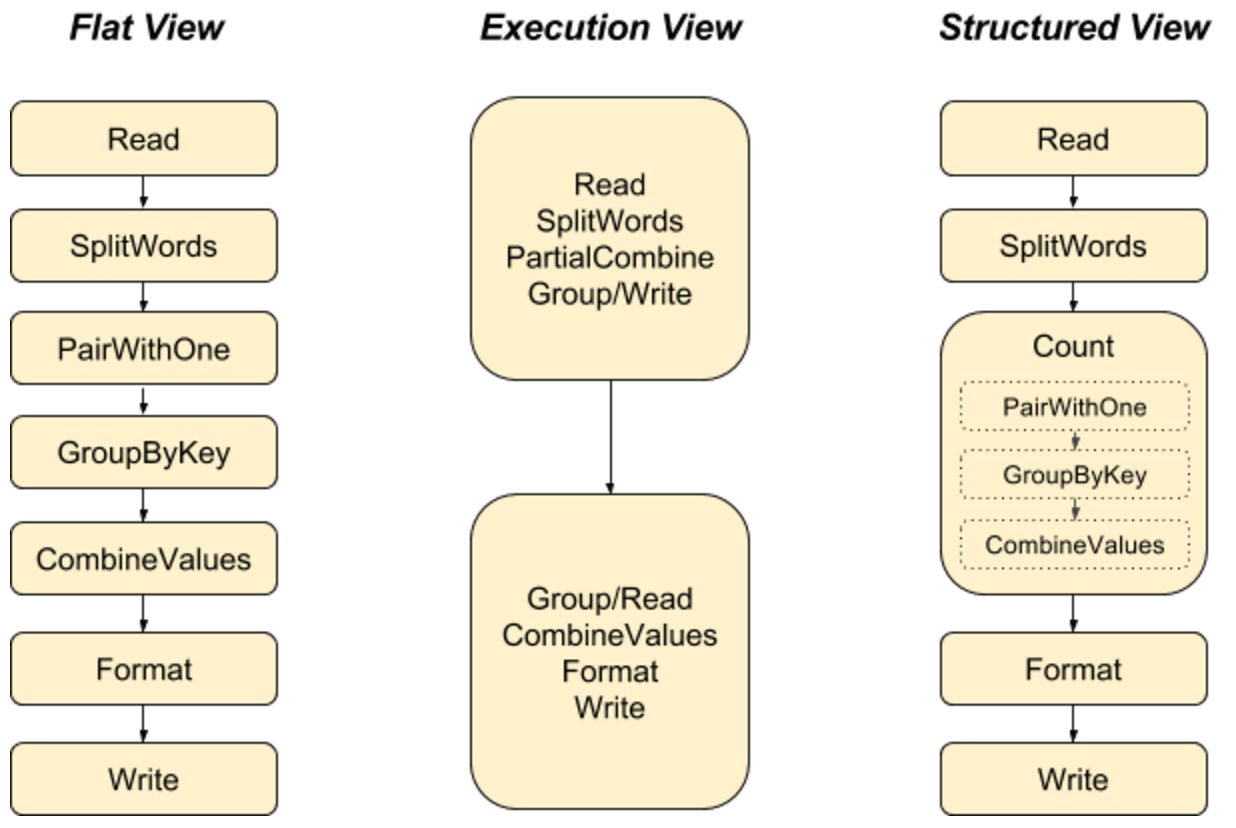
パイプラインが成長し、進化するにつれて、パイプラインをモジュール化された、多くの場合再利用可能なコンポーネントに構造化することが مفید であり、PTransformはデータ処理パイプラインでこれを行うことができます。さらに、モジュール化されたPTransformは、コードの論理構造をシステムに公開します(例:監視のため)。以下のWordCountパイプラインの3つの異なる表現のうち、構造化されたビューのみがパイプラインの高レベルの意図を捉えています。単純な操作でさえPTransformにすることで、複合操作にパッケージ化する際の急激なエッジが少なくなります。
まとめ
PCollectionにメソッドを追加したいと思うかもしれませんが、そのようなアプローチはスケーラブルではなく、拡張性がなく、十分に表現力がありません。PCollectionに単一のapplyメソッドを配置し、すべてのロジックを操作自体に配置することで、両方の長所を得ることができ、単純なパイプラインと複雑なパイプラインの間、および事前定義された操作とユーザー定義の操作の間で単一の一貫したスタイルを持つことで、複雑さのハードクリフを回避できます。