



ブログ
2017/08/28
Apache Beam によるタイムリー(かつステートフル)な処理
以前のブログ記事で、Apache Beamにおけるステートフル処理の基本を紹介しました。これは、要素ごとの処理に状態を追加することに焦点を当てています。Beamにおけるいわゆるタイムリーな処理は、将来のある時点で(ステートフルな)コールバックをリクエストするようにタイマーを設定することで、ステートフル処理を補完します。
Beamでタイマーを使って何ができるでしょうか?以下に例をいくつか示します。
- 一定の処理時間後に状態にバッファリングされたデータを出力できます。
- ウォーターマークが、イベント時間の特定の時点までのすべてのデータを受信したと推定した場合に、特別なアクションを実行できます。
- 一定時間追加の入力がない場合に、状態を変更し、出力を行うタイムアウト付きのワークフローを作成できます。
これらはほんの一例です。状態とタイマーを組み合わせることで、さまざまなワークフローを表現するための、きめ細かい制御のための強力なプログラミングパラダイムが形成されます。Beamにおけるステートフル処理とタイムリーな処理は、データ処理エンジン間で移植可能であり、ストリーミング処理とバッチ処理の両方でBeamのイベント時間ウィンドウ処理の統合モデルと統合されています。
ステートフル処理とタイムリーな処理とは何ですか?
以前の記事では、結合法則と可換法則を満たすコンバイナーとの対比によって、ステートフル処理の理解を深めました。この記事では、以前に軽く触れた視点を強調します。それは、キーごとおよびウィンドウごとの状態とタイマーにアクセスできる要素ごとの処理が、Beamにおける他の処理とは異なる「非常に並列化しやすい」計算の基本的なパターンを表しているという視点です。
実際、ステートフルでタイムリーな計算は、他の計算の基盤となる低レベルの計算パターンです。まさに低レベルであるからこそ、計算を細かく管理して、新しいユースケースや効率性を解き放つことができます。これには、状態とタイマーを手動で管理するという複雑さが伴います。魔法ではありません!まず、Beamにおける2つの主要な計算パターンをもう一度見てみましょう。
要素ごとの処理(ParDo、Mapなど)
最も基本的な非常に並列化しやすいパターンは、多数のコンピューターを使用して、大規模なコレクションのすべての入力要素に同じ関数を適用することです。Beamでは、このような要素ごとの処理は、基本的なParDoとして表現されます。これは、MapReduceの「Map」に類似しており、関数型プログラミングの強化された「map」、「flatMap」などに似ています。
次の図は、要素ごとの処理を示しています。入力要素は正方形、出力要素は三角形です。要素の色はキーを表しており、これは後で重要になります。各入力要素は、対応する出力要素に完全に独立してマップされます。処理は任意の方法でコンピューター間で分散でき、実質的に無制限の並列処理が実現します。
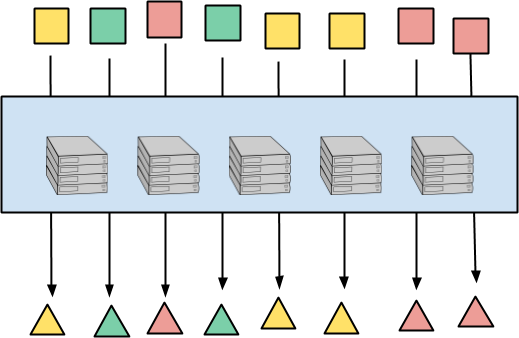
このパターンは明らかであり、すべてのデータ並列パラダイムに存在し、単純なステートレス実装が可能です。すべての入力要素は、個別にまたは任意のバンドルで処理できます。コンピューター間の作業のバランスをとることが実際には難しい部分であり、分割、進捗状況の推定、作業窃盗などによって対処できます。
キーごと(およびウィンドウ)の集計(Combine、Reduce、GroupByKeyなど)
Beamの中核となる、もう1つの非常に並列化しやすい設計パターンは、キーごと(およびウィンドウ)の集計です。キーを共有する要素は同じ場所に配置され、結合法則と可換法則を満たす演算子を使用して結合されます。Beamでは、これはGroupByKeyまたはCombine.perKeyとして表現され、MapReduceのシャッフルと「Reduce」に対応します。キーごとのCombineを基本的な操作とみなし、生のGroupByKeyを入力要素を連結するだけのコンバイナーと考えると役立つ場合があります。入力要素の通信パターンは同じですが、Combineで可能な最適化がいくつかあります。
ここで、各要素の色がキーを表していることを思い出してください。したがって、すべての赤い正方形は同じ場所にルーティングされ、そこで集計され、赤い三角形が出力されます。同様に、黄色と緑色の正方形などにも当てはまります。実際のアプリケーションでは、何百万ものキーが存在する可能性があり、並列処理は依然として大規模です。
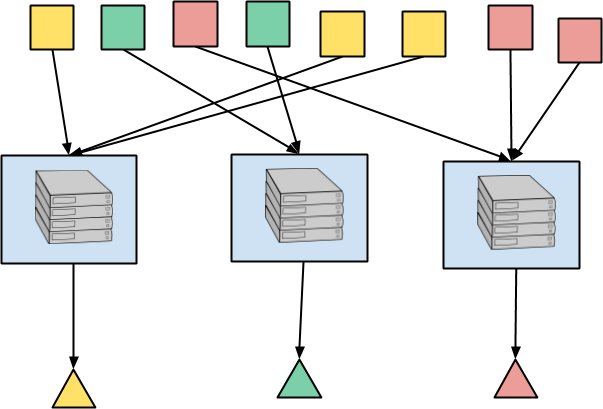
基盤となるデータ処理エンジンは、ある抽象化レベルで、キーに到着するすべての要素に対してこの集計を実行するために状態を使用します。特に、ストリーミング実行では、集計プロセスは、さらにデータが到着するのを待つか、ウォーターマークがイベント時間ウィンドウのすべての入力が完了したと推定するのを待つ必要がある場合があります。これには、入力要素間の集計の中間状態を格納する方法と、結果を出力する時間が来たときにコールバックを受信する方法が必要です。結果として、ストリーム処理エンジンによるキーごとの集計の実行には、本質的に状態とタイマーが関与します。
ただし、ユーザーのコードは、集計演算子の宣言的な表現にすぎません。ランナーは、演算子を実行するためにさまざまな方法を選択できます。この点については、状態のみに焦点を当てた以前の記事で詳しく説明しました。要素が定義された順序で観察されず、可変の状態やタイマーを直接操作しないため、これをステートフル処理ともタイムリーな処理とも呼びません。
キーごとおよびウィンドウごとのステートフルでタイムリーな処理
ParDoとCombine.perKeyはどちらも、数十年前から存在する標準的な並列処理パターンです。これらを大規模分散データ処理エンジンに実装する場合、特に重要な特徴をいくつか強調できます。
ParDoの特性について考えてみましょう。
- 1つの要素を処理するためのシングルスレッドコードを記述します。
- 要素は、要素の処理間に依存関係や相互作用がない、任意の順序で処理されます。
そして、Combine.perKeyの特性は以下のとおりです。
- 共通のキーとウィンドウの要素が集められます。
- ユーザー定義の演算子がこれらの要素に適用されます。
無制限の並列マッピングとキーごとおよびウィンドウごとの結合の特性の一部を組み合わせることで、ステートフル処理とタイムリーな処理を構築するメガプリミティブを識別できます。
- 共通のキーとウィンドウの要素が集められます。
- 要素は任意の順序で処理されます。
- 1つの要素またはタイマーを処理するシングルスレッドコードを記述します。状態にアクセスしたり、タイマーを設定したりすることもできます。
下の図では、赤い正方形が集められ、状態を保持したタイムリーなDoFnに1つずつ供給されます。各要素が処理されると、DoFnは状態(右側の色分けされた円筒)にアクセスでき、コールバックを受信するタイマー(左側のカラフルな時計)を設定できます。
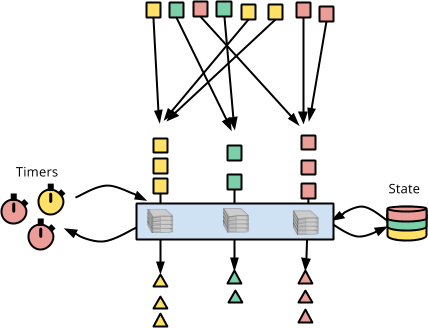
これが、Apache Beamにおけるキーごとおよびウィンドウごとのステートフルでタイムリーな処理の抽象的な概念です。次に、状態にアクセスし、タイマーを設定し、コールバックを受け取るコードを記述するのがどのようなものかを見てみましょう。
例:バッチRPC
ステートフル処理とタイムリーな処理を説明するために、コードを使用した具体的な例を見ていきましょう。
イベントを分析するシステムを作成しているとします。大量のデータが到着しており、外部システムへのRPCによって各イベントを強化する必要があります。イベントごとにRPCを発行することはできません。これはパフォーマンスに非常に悪いだけでなく、外部システムとのクォータを使い果たしてしまう可能性もあります。そのため、多数のイベントを収集し、それらすべてに対して1つのRPCを作成し、次にすべての強化されたイベントを出力することをお勧めします。
状態
要素のバッチを追跡するために必要な状態を設定しましょう。各要素が到着すると、バッファリングした要素の数を追跡しながら、要素をバッファに書き込みます。コード内の状態セルは次のとおりです。
new DoFn<Event, EnrichedEvent>() {
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
… TBD …
}class StatefulBufferingFn(beam.DoFn):
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())コードを詳しく見ていきましょう。
- 状態セル
"buffer"は、バッファリングされたイベントの順序付けられていないバッグです。 - 状態セル
"count"は、バッファリングされたイベントの数を追跡します。
次に、状態の読み取りと書き込みの復習として、@ProcessElementメソッドを記述しましょう。バッファのサイズ制限として、MAX_BUFFER_SIZEを選択します。バッファがこのサイズに達すると、すべてのイベントを強化するために1つのRPCを実行し、出力します。
new DoFn<Event, EnrichedEvent>() {
private static final int MAX_BUFFER_SIZE = 500;
@StateId("buffer")
private final StateSpec<BagState<Event>> bufferedEvents = StateSpecs.bag();
@StateId("count")
private final StateSpec<ValueState<Integer>> countState = StateSpecs.value();
@ProcessElement
public void process(
ProcessContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
int count = firstNonNull(countState.read(), 0);
count = count + 1;
countState.write(count);
bufferState.add(context.element());
if (count >= MAX_BUFFER_SIZE) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… TBD …
}class StatefulBufferingFn(beam.DoFn):
MAX_BUFFER_SIZE = 500;
BUFFER_STATE = BagStateSpec('buffer', EventCoder())
COUNT_STATE = CombiningValueStateSpec('count',
VarIntCoder(),
combiners.SumCombineFn())
def process(self, element,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
buffer_state.add(element)
count_state.add(1)
count = count_state.read()
if count >= MAX_BUFFER_SIZE:
for event in buffer_state.read():
yield event
count_state.clear()
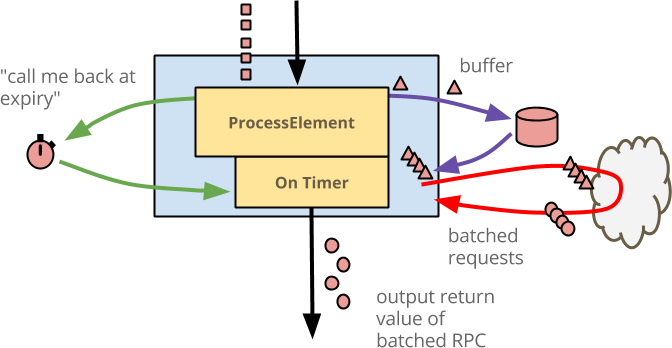
buffer_state.clear()コードに付随する図を次に示します。
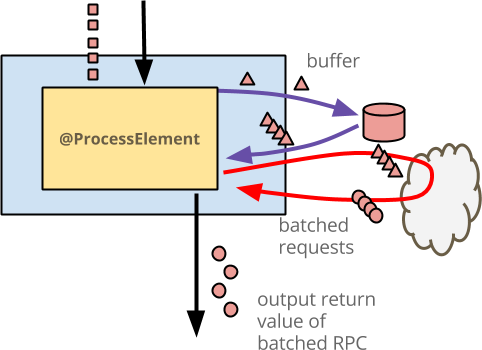
- 青いボックスは
DoFnです。 - その中の黄色いボックスは
@ProcessElementメソッドです。 - 各入力イベントは赤い正方形です。この図は、単一のキー(色赤で表される)のアクティビティのみを示しています。
DoFnは、おそらくユーザーIDであるすべてのキーに対して同じワークフローを並行して実行します。 - 各入力イベントは、赤い三角形としてバッファに書き込まれます。これは、このコードではそうではない場合でも、生の入力以上のものを実際にバッファリングする可能性があることを表しています。
- 外部サービスはクラウドとして描かれています。バッファリングされたイベントが十分にある場合、
@ProcessElementメソッドは状態からイベントを読み取り、1つのRPCを発行します。 - 各出力強化イベントは、赤い円として描かれています。この出力のコンシューマーには、要素ごとの操作のように見えます。
これまでのところ、状態のみを使用しており、タイマーは使用していません。問題があることに気付いたかもしれません。通常、バッファにデータが残ります。それ以上の入力がない場合、そのデータは処理されません。Beamでは、すべてのウィンドウには、ウィンドウに対するそれ以上の入力が遅すぎると見なされて破棄される、イベント時間の時点があります。この時点で、ウィンドウが「期限切れ」になったと言います。それ以上の入力がそのウィンドウの状態にアクセスできないため、状態も破棄されます。この例では、ウィンドウの期限が切れたときに、残りのすべてのイベントが出力されるようにする必要があります。
イベント時間タイマー
イベント時間タイマーは、入力PCollectionのウォーターマークがあるしきい値に達したときにコールバックをリクエストします。言い換えれば、イベント時間における特定の瞬間、つまりPCollectionの完全性の特定の時点(ウィンドウの期限切れ時など)でアクションを実行するためにイベント時間タイマーを使用できます。
この例では、ウィンドウの期限が切れたときに、バッファに残っているイベントが処理されるように、イベント時間タイマーを追加してみましょう。
new DoFn<Event, EnrichedEvent>() {
…
@TimerId("expiry")
private final TimerSpec expirySpec = TimerSpecs.timer(TimeDomain.EVENT_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState,
@TimerId("expiry") Timer expiryTimer) {
expiryTimer.set(window.maxTimestamp().plus(allowedLateness));
… same logic as above …
}
@OnTimer("expiry")
public void onExpiry(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
}
}
}class StatefulBufferingFn(beam.DoFn):
…
EXPIRY_TIMER = TimerSpec('expiry', TimeDomain.WATERMARK)
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER)):
expiry_timer.set(w.end + ALLOWED_LATENESS)
… same logic as above …
@on_timer(EXPIRY_TIMER)
def expiry(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()このスニペットの各部分を分解してみましょう。
@TimerId("expiry")を使用して、イベント時間タイマーを宣言します。コールバック時間を設定したり、コールバックを受信したりするために、識別子"expiry"を使用します。@TimerIdでアノテーションが付けられた変数expiryTimerは、TimerSpecs.timer(TimeDomain.EVENT_TIME)の値に設定されます。これは、入力要素のイベント時間ウォーターマークに従ってコールバックを必要とすることを示します。@ProcessElement要素では、@TimerId("expiry") Timerパラメータにアノテーションを付けます。Beam ランナーは、タイマーを設定(およびリセット)するために使用できるこのTimerパラメータを自動的に提供します。タイマーを繰り返しリセットするのはコストがかからないため、単純にすべての要素で設定します。onExpiryメソッドを定義します。これは、@OnTimer("expiry")でアノテーションが付けられており、最終的なイベントエンリッチメント RPC を実行し、結果を出力します。Beam ランナーは、識別子を照合することで、このメソッドにコールバックを配信します。
このロジックを図で示すと、以下のようになります。
@ProcessElement メソッドと @OnTimer("expiry") メソッドの両方で、バッファリングされた状態への同じアクセスを実行し、同じバッチ RPC を実行して、エンリッチされた要素を出力します。
ここで、これをストリーミングのリアルタイム方式で実行している場合、特定のバッファリングされたデータに対して依然として無制限のレイテンシーが発生する可能性があります。ウォーターマークの進行が非常に遅い場合や、イベント時間ウィンドウが非常に大きく選択されている場合、十分な要素またはウィンドウの有効期限に基づいて出力が生成されるまでに多くの時間が経過する可能性があります。バッファリングされた要素を処理するまでのウォールクロック時間、つまり処理時間量を制限するためにタイマーを使用することもできます。外部サービスとのクォータを超えないように、RPC の数が少なすぎる場合でも、妥当な時間を設定できます。
処理時間タイマー
処理時間(パイプラインの実行中に経過する時間)におけるタイマーは、直感的に単純です。一定時間待機してからコールバックを受けたいだけです。
例に仕上げを加えるために、データがバッファリングされたらすぐに処理時間タイマーを設定します。現在のバッファが空の場合にのみタイマーを設定して、タイマーを継続的にリセットしないようにします。最初の要素が到着すると、現在時刻に MAX_BUFFER_DURATION を加算した時間を設定します。割り当てられた処理時間が経過すると、コールバックが起動し、バッファリングされた要素をエンリッチして出力します。
new DoFn<Event, EnrichedEvent>() {
…
private static final Duration MAX_BUFFER_DURATION = Duration.standardSeconds(1);
@TimerId("stale")
private final TimerSpec staleSpec = TimerSpecs.timer(TimeDomain.PROCESSING_TIME);
@ProcessElement
public void process(
ProcessContext context,
BoundedWindow window,
@StateId("count") ValueState<Integer> countState,
@StateId("buffer") BagState<Event> bufferState,
@TimerId("stale") Timer staleTimer,
@TimerId("expiry") Timer expiryTimer) {
if (firstNonNull(countState.read(), 0) == 0) {
staleTimer.offset(MAX_BUFFER_DURATION).setRelative();
}
… same processing logic as above …
}
@OnTimer("stale")
public void onStale(
OnTimerContext context,
@StateId("buffer") BagState<Event> bufferState,
@StateId("count") ValueState<Integer> countState) {
if (!bufferState.isEmpty().read()) {
for (EnrichedEvent enrichedEvent : enrichEvents(bufferState.read())) {
context.output(enrichedEvent);
}
bufferState.clear();
countState.clear();
}
}
… same expiry as above …
}class StatefulBufferingFn(beam.DoFn):
…
STALE_TIMER = TimerSpec('stale', TimeDomain.REAL_TIME)
MAX_BUFFER_DURATION = 1
def process(self, element,
w=beam.DoFn.WindowParam,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE),
expiry_timer=beam.DoFn.TimerParam(EXPIRY_TIMER),
stale_timer=beam.DoFn.TimerParam(STALE_TIMER)):
if count_state.read() == 0:
# We set an absolute timestamp here (not an offset like in the Java SDK)
stale_timer.set(time.time() + StatefulBufferingFn.MAX_BUFFER_DURATION)
… same logic as above …
@on_timer(STALE_TIMER)
def stale(self,
buffer_state=beam.DoFn.StateParam(BUFFER_STATE),
count_state=beam.DoFn.StateParam(COUNT_STATE)):
events = buffer_state.read()
for event in events:
yield event
buffer_state.clear()
count_state.clear()最終的なコードの図を以下に示します。
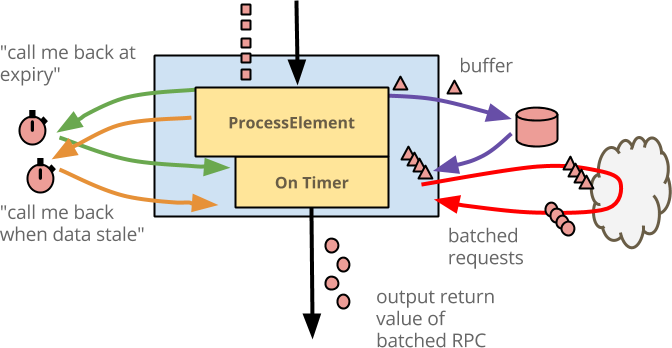
ロジック全体をまとめます。
@ProcessElementにイベントが到着すると、状態にバッファリングされます。- バッファのサイズが最大値を超えると、イベントがエンリッチされて出力されます。
- バッファの充填が遅すぎて、最大値に達する前にイベントが古くなる場合、タイマーによってコールバックが発生し、バッファリングされたイベントがエンリッチされて出力されます。
- 最後に、ウィンドウの有効期限が切れると、そのウィンドウにバッファリングされたイベントがすべて処理され、そのウィンドウの状態が破棄される前に出力されます。
最終的に、状態とタイマーを使用して、Beam でパフォーマンスに敏感な変換の低レベルの詳細を明示的に管理する完全な例ができました。機能を追加すればするほど、DoFn は実際にはかなり大きくなりました。これは、ステートフルでタイムリーな処理の通常の特性です。Beam の高レベル API を使用してロジックを表現する際に自動的に処理される多くの詳細を、実際に掘り下げて管理することになります。この追加の労力から得られるのは、他の方法では不可能だったかもしれないユースケースに取り組み、効率を達成する能力です。
Beam の統一モデルにおける状態とタイマー
ストリーミング処理とバッチ処理全体でのイベント時間の Beam の統一モデルは、状態とタイマーに新たな影響を与えます。通常、ステートフルでタイムリーな DoFn を Beam モデルで正常に動作させるために、何もする必要はありません。ただし、特に Beam 以外で同様の機能を使用したことがある場合は、以下の考慮事項を認識しておくと役立ちます。
イベント時間ウィンドウは「そのまま動作する」
Beam の存在理由の 1 つは、ほとんどすべてのイベントデータである順序が狂ったイベントデータを正しく処理することです。順序が狂ったデータに対する Beam のソリューションは、イベント時間ウィンドウ処理です。イベント時間のウィンドウでは、ユーザーが選択するウィンドウ処理やイベントの順序に関係なく、正しい結果が得られます。
ステートフルでタイムリーな変換を作成する場合、周囲のパイプラインがイベント時間をどのようにウィンドウ処理することを選択しても動作するはずです。パイプラインが 1 時間の固定ウィンドウ(タンブリングウィンドウと呼ばれることもあります)または 10 分ずつスライドする 30 分のウィンドウを選択した場合でも、ステートフルでタイムリーな変換は透過的に正しく動作する必要があります。
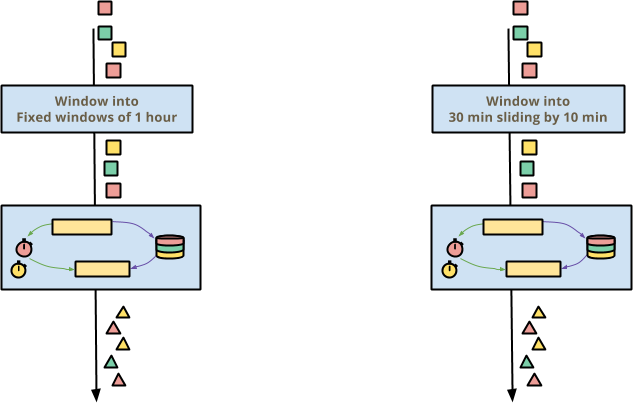
Beam では、状態とタイマーがキーとウィンドウごとに分割されるため、これは自動的に動作します。各キーとウィンドウ内では、ステートフルでタイムリーな処理は基本的に独立しています。さらに、イベント時間(ウォーターマークの進行とも呼ばれる)の経過により、ウィンドウの有効期限が切れると、到達不能な状態が自動的に解放されるため、古い状態を削除することを心配する必要はほとんどありません。
リアルタイム処理と履歴処理の統合
Beam のセマンティックモデルの 2 番目の原則は、バッチ処理とストリーミング処理の間で処理を統合する必要があるということです。この統合の重要なユースケースの 1 つは、リアルタイムのイベントストリームと、同じイベントのアーカイブストレージに同じロジックを適用する機能です。
アーカイブされたデータの一般的な特徴は、大幅に順序が狂って到着する可能性があるということです。アーカイブされたファイルのシャーディングは、ほとんどリアルタイムで到着するイベントとは、処理の順序が完全に異なる結果になることがよくあります。データはすべて利用可能であり、パイプラインの観点からは即座に配信されます。過去のデータで実験を実行する場合でも、データ処理バグを修正するために過去の結果を再処理する場合でも、処理ロジックが、ほぼリアルタイムで到着するデータと同じように、アーカイブされたイベントにも簡単に適用できることが非常に重要です。
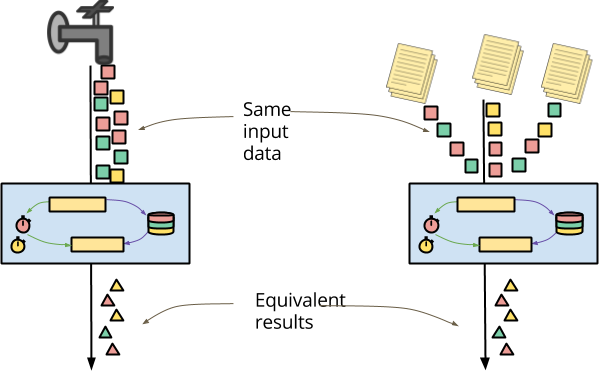
順序または配信のタイミングに依存する結果を配信するステートフルでタイムリーな DoFn を(意図的に)記述することは可能です。この意味では、この非決定性が文書化された許容範囲内になるように、DoFn の作成者であるあなたに追加の負担がかかります。
ぜひお試しください。
この投稿の終わりも、前回の投稿と同じように締めくくります。ステートフルでタイムリーな処理を伴う Beam をぜひ試してみてください。それがあなたの新しい可能性を開くのであれば、素晴らしいです。そうでない場合は、ぜひお知らせください。これは新しい機能であるため、ケイパビリティマトリックス を確認して、お好みの Beam バックエンドのサポートレベルを確認してください。
また、user@beam.apache.org で Beam コミュニティに参加し、Twitter で @ApacheBeam をフォローしてください。