



ブログ
2017/02/13
Apache Beamによるステートフル処理
Beamを使用すると、ポータブルな高レベルパイプラインで、境界のない、順不同のグローバルスケールデータを処理できます。ステートフル処理は、Beamモデルの新しい機能であり、Beamの機能を拡張し、新しいユースケースと新しい効率性を実現します。この記事では、Beamでのステートフル処理について説明します。その仕組み、Beamモデルの他の機能との適合性、そのユースケース、およびコードでの表現について説明します。
注:この投稿は、Pythonスニペットを含めるために、2019年5月に更新されました!
警告:新しい機能が追加されました!:これはBeamモデルの非常に新しい側面です。ランナーはまだサポートを追加しています。今日では、複数のランナーで試すことができますが、各ランナーの現在のステータスについては、ランナー機能マトリックスを確認してください。
まず、簡単な要約から始めましょう。Beamでは、ビッグデータ処理のパイプラインは、PTransformsと呼ばれる並列演算の有向非巡回グラフであり、PCollectionsからのデータを処理します。この図を順を追って説明することで、それを詳しく見ていきましょう。
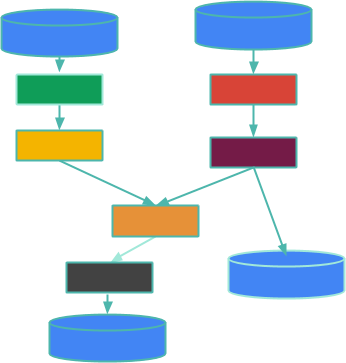
ボックスはPTransformsであり、エッジはPCollections内のデータが1つのPTransformから次のPTransformに流れることを表しています。PCollectionは、境界付き(有限であり、それがわかっていることを意味します)または境界なし(有限かどうかをわからないことを意味します。基本的には、終了するかどうかわからない着信データストリームのようなものです)にすることができます。シリンダーは、ログファイルの境界付きコレクションやKafkaトピックを介してストリーミングされる境界なしデータなど、パイプラインのエッジにあるデータソースとシンクです。このブログ記事は、ソースやシンクについてではなく、その間、つまりデータ処理についてです。
Beamでデータを処理するための2つの主要な構成要素があります。1つはすべての要素に対して並列に操作を実行するParDo、もう1つは同じキーを割り当てた要素を集約するためのGroupByKey(および私がすぐに説明する、密接に関連するCombinePerKey)です。下の図(多くのプレゼンテーションで取り上げられている)では、色は要素のキーを示しています。したがって、GroupByKey/CombinePerKey変換は、すべての緑の四角形を集めて1つの出力要素を生成します。
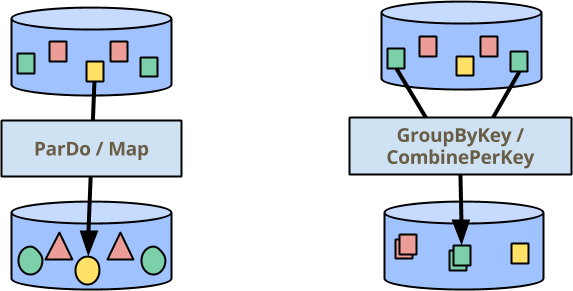
ただし、すべてのユースケースを、単純なParDo/MapおよびGroupByKey/CombinePerKey変換のパイプラインとして簡単に表現できるわけではありません。このブログ記事のトピックは、Beamプログラミングモデルの新しい拡張機能である、可変状態が拡張された要素ごとの操作です。
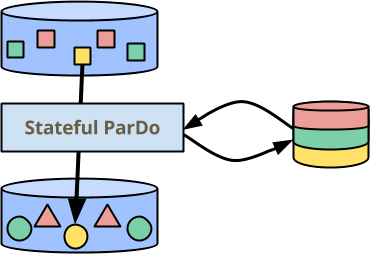
上の図では、ParDoの横に、永続的な一貫性のある状態が少し追加されました。これは、各要素の処理中に読み取りおよび書き込みできます。状態はキーによってパーティション分割されるため、各色に対して分離されたセクションを持つように描画されます。また、ウィンドウごとにパーティション分割されていますが、私が思ったのは、格子縞![]() が少し多いということです。状態がこのようにパーティション分割される理由については、最初の例を挙げて後で少し説明します。
が少し多いということです。状態がこのようにパーティション分割される理由については、最初の例を挙げて後で少し説明します。
この記事の残りの部分では、Beamのこの新しい機能について、詳細に説明します。高レベルでの動作、既存の機能との違い、大規模な拡張性を維持する方法。モデルレベルでの紹介の後、Beam Java SDKでの使用方法の簡単な例を順を追って説明します。
Beamでのステートフル処理はどのように機能しますか?
ParDo変換の処理ロジックは、各要素に適用されるDoFnによって表現されます。ステートフル拡張がない場合、DoFnは入力から1つ以上の出力へのほとんど純粋な関数であり、MapReduceのマッパーに対応します。状態を使用すると、DoFnは各入力要素の処理中に永続的な可変状態にアクセスできます。この図を検討してください。
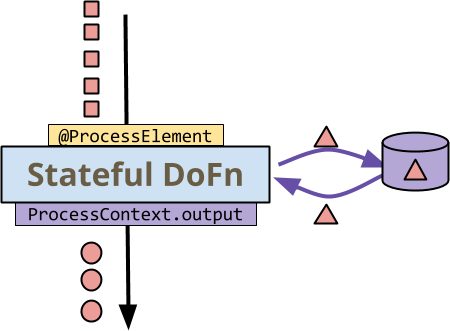
最初に注意すべき点は、小さな四角形、円、三角形などのすべてのデータが赤色であることです。これは、ステートフル処理が単一のキーのコンテキストで発生することを示すためです。つまり、すべての要素は同じキーを持つキーと値のペアです。選択したBeamランナーからDoFnへの呼び出しは黄色で色分けされ、DoFnからランナーへの呼び出しは紫色で色分けされています。
- ランナーは、キー+ウィンドウの各要素に対して、
DoFnの@ProcessElementメソッドを呼び出します。 DoFnは、状態を読み書きします。つまり、側面のストレージとの間の曲線矢印です。DoFnは、ProcessContext.output(resp.ProcessContext.sideOutput)を介して、通常どおりランナーに出力(またはサイド出力)を送信します。
この非常に高レベルでは、非常に直感的です。プログラミング経験では、他のアクションを実行しながら、可変変数を更新する要素に対してループを記述したことがあるでしょう。興味深い点は、これがBeamモデルにどのように適合するかです。他の機能とどのように関連しているか?状態はいくつかの同期を意味するため、どのように拡張するか?他の機能と比較して、いつ使用する必要があるか?
ステートフル処理はBeamモデルにどのように適合しますか?
ステートフル処理がBeamモデルに適合する場所を確認するために、多くの要素を処理しながら「状態」を維持できる別の方法を検討してください。CombineFnです。Beamでは、JavaまたはPythonでCombine.perKey(CombineFn)を記述して、共通キー(およびウィンドウ)を持つすべての要素にわたって結合的で可換な累積演算を適用できます。
これは、CombineFnの基本を示す図です。ランナーがキー単位で呼び出して、アキュムレーターを構築し、最後のアキュムレーターから出力を抽出する最も簡単な方法です。
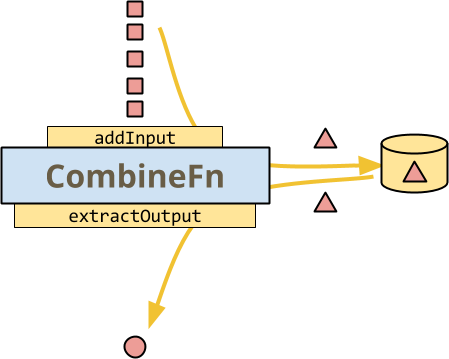
ステートフルDoFnの図と同様に、すべてのデータは赤色で色付けされています。これは、単一キーのCombineの処理であるためです。図示されたメソッド呼び出しは、すべてランナーによって制御されるため、黄色で色分けされています。ランナーは、各メソッドでaddInputを呼び出して、現在のアキュムレーターに追加します。
- ランナーは、選択したときにアキュムレーターを永続化します。
- ランナーは、出力要素を送信する準備ができたら、
extractOutputを呼び出します。
この時点で、CombineFnの図は、ステートフルDoFnの図と非常によく似ています。実際には、データの流れは実際には非常に似ています。しかし、それでも重要な違いがあります。
- ランナーは、ここですべての呼び出しとストレージを制御します。状態が永続化される時期や方法、トリガーに基づいてアキュムレーターが破棄される時期、アキュムレーターから出力が抽出される時期を決定しません。
- 状態は1つしか持つことができません。つまり、アキュムレーターです。ステートフルDoFnでは、知る必要があるものだけを読み取り、変更されたものだけを書き込むことができます。
- 入力ごとの複数の出力やサイド出力など、
DoFnの拡張機能はありません。(これらは十分に複雑なアキュムレーターによってシミュレートできますが、自然でも効率的でもありません。サイド入力やウィンドウへのアクセスなど、DoFnの他の機能の一部はCombineFnに最適です)
しかし、CombineFnがランナーに許可する主なことは、mergeAccumulators、つまりCombineFnの結合性の具体的な表現です。これにより、いくつかの大規模な最適化が可能になります。ランナーは、この図のように、多数の入力に対してCombineFnの複数のインスタンスを呼び出し、後で古典的な分割統治アーキテクチャでそれらを組み合わせることができます。
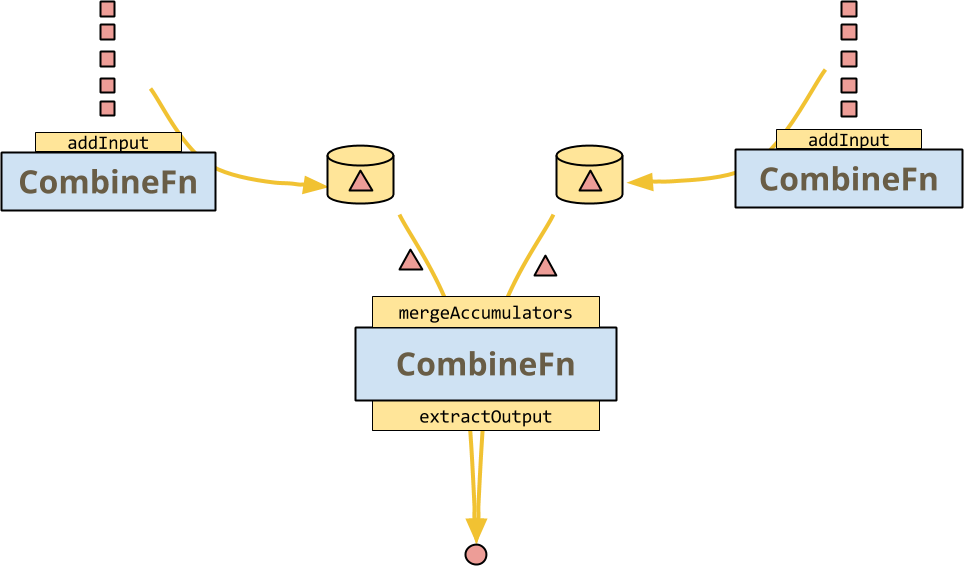
CombineFnの契約は、ランナーが実際にそのようなこと、またはホットキーファンアウトなどを含むより複雑なツリーを実行するかどうかに関係なく、結果はまったく同じである必要があるということです。
このマージ操作は、ステートフルDoFnでは(必ずしも)提供されません。ランナーは、実行を自由に分岐して状態を再結合することはできません。入力要素はまだ任意の順序で受信されるため、DoFnは順序とバンドルに左右されない必要がありますが、出力が完全に等しい必要はないことを意味します。(楽しく簡単な事実:出力が実際に常に等しい場合、DoFnは結合的で可換な演算子です)
これで、ステートフルDoFnがCombineFnとどのように異なるかがわかりましたが、ここで少し戻って、Beamの状態が同じまたは同様の目標を達成するために他の機能を使用することにどのように関連しているかについて、高レベルの全体像に外挿したいと思います。多くの場合、ステートフル処理が表すのは、Beamの高度に抽象化されたほとんど決定論的な関数型パラダイムの「内部」に潜り込み、他の方法では表現が難しい、潜在的に非決定論的な命令型プログラミングを実行するチャンスです。
例:任意だが一貫性のあるインデックス割り当て
キーとウィンドウのすべての着信要素にインデックスを付けたいとします。インデックスが何であるかは気にしません。インデックスが一意で一貫性がある限り。Beam SDKでこれを実行する方法のコードに入る前に、モデルのレベルからこの例について説明します。図では、次のように入力を出力にマッピングする変換を記述します。
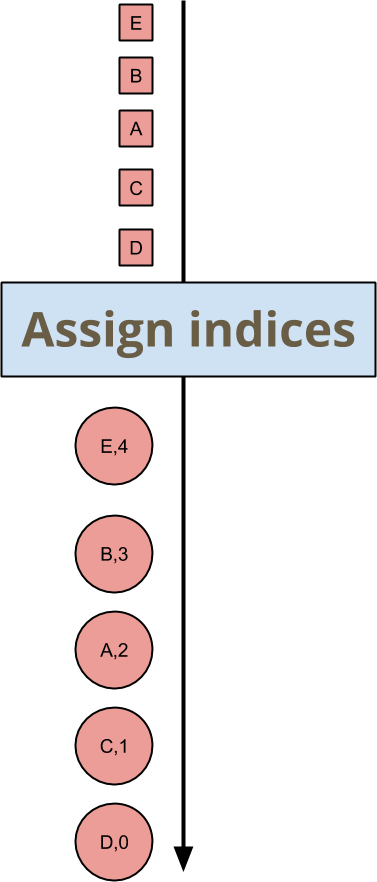
要素A、B、C、D、Eの順序は任意であるため、割り当てられたインデックスも任意ですが、ダウンストリームの変換はこれで問題ありません。実際の値に関する限り、結合性や可換性はありません。この変換の順序依存性のないのは、出力の必要なプロパティを保証する点までです。つまり、重複したインデックスがなく、ギャップがなく、すべての要素にインデックスが付けられます。
これをステートフルループとして概念的に表現することは、想像できるほど簡単です。保存する必要がある状態は、次のインデックスです。
- 要素が入ってきたら、次のインデックスとともに出力します。
- インデックスをインクリメントします。
これは、ビッグデータと並列処理について話し合う良い機会です。なぜなら、上記の箇条書きのアルゴリズムはまったく並列化できないからです。このロジックをPCollection全体に適用したい場合は、PCollectionの各要素を一度に1つずつ処理する必要があります...これは明らかに悪い考えです。Beamの状態は厳密に範囲が定められているため、ほとんどの場合、ステートフルParDo変換はランナーが並行して実行することも可能である必要がありますが、それでも注意深く検討する必要があります。
Beamの状態セルは、キー+ウィンドウのペアに範囲が設定されています。DoFnが"index"という名前で状態を読み書きする場合、実際には"index"で指定された可変セルにアクセスしています。これは、現在処理中のキーとウィンドウとともにです。したがって、状態セルについて考える場合は、変換の完全な状態をテーブルとして考えると役立つ場合があります。行はプログラムで使用する名前("index"など)に従って名前が付けられ、列は次のようにキー+ウィンドウのペアになります。
| (キー、ウィンドウ)1 | (キー、ウィンドウ)2 | (キー、ウィンドウ)3 | … | |
|---|---|---|---|---|
"インデックス" | 3 | 7 | 15 | … |
"フィズまたはバズ?" | "フィズ" | "7" | "フィズバズ" | … |
| … | … | … | … | … |
(空間感覚に優れている場合は、これをキーとウィンドウが独立した次元である立方体として想像してください)
テーブルに十分な列があることを確認することで、並列処理の機会を提供できます。多くのキーと多くのウィンドウがある場合もあれば、どちらか一方だけが多い場合もあります。
- 例えば、ユーザーIDでキー付けされたグローバルウィンドウのステートフルな計算のように、少数のウィンドウに多くのキーがある場合。
- 例えば、グローバルキーに対する固定ウィンドウのステートフルな計算のように、少数のキーに対して多くのウィンドウがある場合。
注意:今日のすべてのBeamランナーは、キーのみで並列化を行います。
多くの場合、状態のメンタルモデルは、テーブルの単一の列、つまり単一のキー+ウィンドウのペアにのみ焦点を当てることができます。列間の相互作用は、設計上、直接的には発生しません。
BeamのJava SDKにおける状態
Beamモデルにおけるステートフルな処理について少し説明し、抽象的な例を説明したので、BeamのJava SDKを使用してステートフルな処理コードを記述するとどうなるかを示したいと思います。以下は、キーごとおよびウィンドウごとに各要素に任意の(ただし一貫性のある)インデックスを割り当てるステートフルなDoFnのコードです。
new DoFn<KV<MyKey, MyValue>, KV<Integer, KV<MyKey, MyValue>>>() {
// A state cell holding a single Integer per key+window
@StateId("index")
private final StateSpec<ValueState<Integer>> indexSpec =
StateSpecs.value(VarIntCoder.of());
@ProcessElement
public void processElement(
ProcessContext context,
@StateId("index") ValueState<Integer> index) {
int current = firstNonNull(index.read(), 0);
context.output(KV.of(current, context.element()));
index.write(current+1);
}
}class IndexAssigningStatefulDoFn(DoFn):
INDEX_STATE = CombiningStateSpec('index', sum)
def process(self, element, index=DoFn.StateParam(INDEX_STATE)):
unused_key, value = element
current_index = index.read()
yield (value, current_index)
index.add(1)これを詳しく見ていきましょう。
- 最初に注目すべき点は、いくつかの
@StateId("index")アノテーションの存在です。これは、このDoFnで「index」という名前の可変状態セルを使用していることを示します。Beam Java SDKと、そこから選択したランナーもこれらのアノテーションに注目し、それらを使用してDoFnを正しく配線します。 - 最初の
@StateId("index")は、StateSpec(「状態仕様」)型のフィールドに注釈が付けられています。これは、状態セルを宣言および構成します。型パラメータValueStateは、このセルから取得できる状態の種類を示します。ValueStateは単一の値を保存します。仕様自体は使用可能な状態セルではないことに注意してください。パイプラインの実行中にランナーがそれを提供する必要があります。 ValueStateセルを完全に指定するには、保存する値をシリアル化するためにランナーが(必要に応じて)使用するコーダーを提供する必要があります。これは、StateSpecs.value(VarIntCoder.of())の呼び出しです。- 2番目の
@StateId("index")アノテーションは、@ProcessElementメソッドのパラメータにあります。これは、以前に指定されたValueStateセルへのアクセスを示します。 - 状態には最も簡単な方法でアクセスできます。
read()で読み取り、write(newvalue)で書き込みます。 DoFnの他の機能は、context.output(...)などの通常の方法で利用できます。また、サイド入力、サイド出力を使用したり、ウィンドウにアクセスしたりすることもできます。
SDKとランナーがこのDoFnをどのように認識するかについてのいくつかの注意事項
- 状態セルはすべて明示的に宣言されているため、Beam SDKまたはランナーはそれらについて推論できます。たとえば、ウィンドウが期限切れになったときにそれらをクリアできます。
- 状態セルを宣言し、それを間違った型で使用すると、Beam Java SDKがそのエラーを検出します。
- 同じIDで2つの状態セルを宣言すると、SDKもそれを検出します。
- ランナーは、これがステートフルな
DoFnであることを認識しており、例えば、状態セルへの同時アクセスを回避するために、追加のデータシャッフルと同期を行うことで、非常に異なる方法で実行する場合があります。
このAPIの使用方法の別の例を見てみましょう。今度はもう少し現実的な例です。
例:異常検出
例えば、不正行為を検出するために、ユーザーによるアクションのストリームを、彼らが取るアクションの種類を定量的に表現したものを予測するための複雑なモデルに入力するとします。イベントからモデルを構築し、最新のモデルに対して着信イベントを比較して、何かが変化したかどうかを判断します。
モデルの構築をCombineFnとして表現しようとすると、mergeAccumulatorsで問題が発生する可能性があります。それが表現できると仮定すると、次のようになる可能性があります。
class ModelFromEventsFn extends CombineFn<Event, Model, Model> {
@Override
public abstract Model createAccumulator() {
return Model.empty();
}
@Override
public abstract Model addInput(Model accumulator, Event input) {
return accumulator.update(input); // this is encouraged to mutate, for efficiency
}
@Override
public abstract Model mergeAccumulators(Iterable<Model> accumulators) {
// ?? can you write this ??
}
@Override
public abstract Model extractOutput(Model accumulator) {
return accumulator; }
}class ModelFromEventsFn(apache_beam.core.CombineFn):
def create_accumulator(self):
# Create a new empty model
return Model()
def add_input(self, model, input):
return model.update(input)
def merge_accumulators(self, accumulators):
# Custom merging logic
def extract_output(self, model):
return modelこれで、Combine.perKey(new ModelFromEventsFn())としてウィンドウの特定のユーザーのモデルを計算する方法ができました。このモデルを、計算元のイベントの同じストリームに適用するにはどうすればよいでしょうか? Combine変換の結果を取得し、PCollectionの要素を処理中に使用する標準的な方法は、それをParDo変換へのサイド入力として読み取ることです。したがって、モデルをサイド入力し、それに対してイベントのストリームを確認し、予測を出力することができます。次のようになります。
PCollection<KV<UserId, Event>> events = ...
final PCollectionView<Map<UserId, Model>> userModels = events
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());
PCollection<KV<UserId, Prediction>> predictions = events
.apply(ParDo.of(new DoFn<KV<UserId, Event>>() {
@ProcessElement
public void processElement(ProcessContext ctx) {
UserId userId = ctx.element().getKey();
Event event = ctx.element().getValue();
Model model = ctx.sideinput(userModels).get(userId);
// Perhaps some logic around when to output a new prediction
… c.output(KV.of(userId, model.prediction(event))) …
}
}));# Events is a collection of (user, event) pairs.
events = (p | ReadFromEventSource() | beam.WindowInto(....))
user_models = beam.pvalue.AsDict(
events
| beam.core.CombinePerKey(ModelFromEventsFn()))
def event_prediction(user_event, models):
user = user_event[0]
event = user_event[1]
# Retrieve the model calculated for this user
model = models[user]
return (user, model.prediction(event))
# Predictions is a collection of (user, prediction) pairs.
predictions = events | beam.Map(event_prediction, user_models)このパイプラインでは、Combine.perKey(...)によってユーザーごと、ウィンドウごとに1つのモデルが出力され、それがView.asMap()変換によってサイド入力の準備が整えられます。イベントに対するParDoの処理は、そのサイド入力の準備が整うまでブロックされ、イベントをバッファリングし、各イベントをモデルに対して確認します。これは、高レイテンシー、高完全性のソリューションです。モデルはウィンドウ内のすべてのユーザー行動を考慮に入れますが、ウィンドウが完了するまで出力は行われません。
より早く結果を得たい場合、または自然なウィンドウ処理がない場合でも、「これまでのモデル」で継続的な分析を行いたい場合はどうすればよいでしょうか。モデルが完全でなくてもです。イベントを確認するモデルの更新をどのように制御できますか?トリガーは、完全性とレイテンシーのトレードオフを管理するための一般的なBeam機能です。したがって、入力が到着してから1秒後に新しいモデルを出力するトリガーが追加された同じパイプラインを次に示します。
PCollection<KV<UserId, Event>> events = ...
PCollectionView<Map<UserId, Model>> userModels = events
// A tradeoff between latency and cost
.apply(Window.triggering(
AfterProcessingTime.pastFirstElementInPane(Duration.standardSeconds(1)))
.apply(Combine.perKey(new ModelFromEventsFn()))
.apply(View.asMap());events = ...
user_models = beam.pvalue.AsDict(
events
| beam.WindowInto(GlobalWindows(),
trigger=trigger.AfterAll(
trigger.AfterCount(1),
trigger.AfterProcessingTime(1)))
| beam.CombinePerKey(ModelFromEventsFn()))これは多くの場合、レイテンシーとコストの間の非常に優れたトレードオフです。1秒間に大量のイベントが流入した場合、新しいモデルは1つしか出力されないため、古くなる前に使用することすらできないモデルの出力で溢れることはありません。実際には、キャッシュとサイド入力を準備する処理の遅延により、新しいモデルがサイド入力チャネルに表示されるまでにさらに数秒かかる場合があります。多くのイベント(おそらくアクティビティのバッチ全体)がParDoを通過し、以前のモデルに従って予測が計算されます。ランナーがキャッシュの有効期限に十分な制限を与え、より積極的なトリガーを使用した場合、追加コストでレイテンシーを改善できる可能性があります。
ただし、考慮すべき別のコストがあります。下流で処理されるParDoから多くの面白くない出力が出力されています。出力の「面白さ」が以前の出力に対してのみ明確に定義されている場合、Filter変換を使用して下流のデータ量を削減することはできません。
ステートフルな処理を使用すると、サイド入力のレイテンシーの問題と、過剰な面白くない出力のコストの問題の両方に対処できます。次に、すでに紹介した機能のみを使用したコードを示します。
new DoFn<KV<UserId, Event>, KV<UserId, Prediction>>() {
@StateId("model")
private final StateSpec<ValueState<Model>> modelSpec =
StateSpecs.value(Model.coder());
@StateId("previousPrediction")
private final StateSpec<ValueState<Prediction>> previousPredictionSpec =
StateSpecs.value(Prediction.coder());
@ProcessElement
public void processElement(
ProcessContext c,
@StateId("previousPrediction") ValueState<Prediction> previousPredictionState,
@StateId("model") ValueState<Model> modelState) {
UserId userId = c.element().getKey();
Event event = c.element().getValue()
Model model = modelState.read();
Prediction previousPrediction = previousPredictionState.read();
Prediction newPrediction = model.prediction(event);
model.add(event);
modelState.write(model);
if (previousPrediction == null
|| shouldOutputNewPrediction(previousPrediction, newPrediction)) {
c.output(KV.of(userId, newPrediction));
previousPredictionState.write(newPrediction);
}
}
};class ModelStatefulFn(beam.DoFn):
PREVIOUS_PREDICTION = BagStateSpec('previous_pred_state', PredictionCoder())
MODEL_STATE = CombiningValueStateSpec('model_state',
ModelCoder(),
ModelFromEventsFn())
def process(self,
user_event,
previous_pred_state=beam.DoFn.StateParam(PREVIOUS_PREDICTION),
model_state=beam.DoFn.StateParam(MODEL_STATE)):
user = user_event[0]
event = user_event[1]
model = model_state.read()
previous_prediction = previous_pred_state.read()
new_prediction = model.prediction(event)
model_state.add(event)
if (previous_prediction is None
or self.should_output_prediction(
previous_prediction, new_prediction)):
previous_pred_state.clear()
previous_pred_state.add(new_prediction)
yield (user, new_prediction)詳しく見ていきましょう。
- ユーザーのモデルの現在の状態を保持する
@StateId("model")と、以前に出力された予測を保持する@StateId("previousPrediction")の2つの状態セルが宣言されています。 @ProcessElementメソッドのアノテーションによる2つの状態セルへのアクセスは以前と同じです。modelState.read()を介して現在のモデルを読み取ります。キーごと、ウィンドウごとに、これは現在処理されているイベントのUserIdのみのモデルです。- 新しい予測
model.prediction(event)を導出し、previousPredicationState.read()を介してアクセスされた、以前に出力したものと比較します。 - 次に、モデルを更新
model.update()し、modelState.write(...)を介して書き込みます。CombineFnアキュムレータをミューテートすることが推奨されているように、状態からプルした値をミューテートすることも、ミューテートされた値を書き込むことを覚えていれば問題ありません。 - 予測が前回出力時から大幅に変更されている場合は、
context.output(...)を介して出力し、previousPredictionState.write(...)を使用して予測を保存します。ここでの決定は、最後に計算されたものではなく、以前の予測出力に関連しています。実際には、ここにいくつかの複雑な条件がある可能性があります。
上記のほとんどはJavaについて説明しているだけです。しかし、すべてのパイプラインをステートフルな処理を使用するように変換する前に、それがユースケースに適しているかどうかに関するいくつかの考慮事項について説明したいと思います。
パフォーマンスに関する考慮事項
キーごとのウィンドウごとの状態を使用するかどうかを決定するには、どのように実行されるかを考慮する必要があります。特定のランナーが状態をどのように管理するかを詳しく調べることができますが、覚えておくべき一般的なことがいくつかあります。
- キーごとのウィンドウごとのパーティショニング:おそらく最も重要な考慮事項は、ランナーが特定のキー+ウィンドウのすべてのデータを同じ場所に配置するためにデータをシャッフルする必要がある場合があることです。データがすでに正しくシャッフルされている場合、ランナーはこれを利用できる場合があります。
- 同期オーバーヘッド:APIは、ランナーが同時実行制御を処理するように設計されていますが、これは、ランナーが他の場合に有利であっても、特定のキー+ウィンドウの要素の処理を並列化できないことを意味します。
- 状態のストレージとフォールトトレランス:状態はキーごと、ウィンドウごとであるため、同時に処理するキーとウィンドウが多いほど、ストレージが増えます。状態はBeamの他のデータのすべてのフォールトトレランス/一貫性プロパティの恩恵を受けるため、処理結果のコミットコストも増加します。
- 状態の有効期限:また、状態はウィンドウごとであるため、ランナーはウィンドウが期限切れになったとき(ウォーターマークが許可された遅延を超えたとき)にリソースを再利用できますが、これは、ランナーが再利用コードを実行するために、キーとウィンドウごとに追加のタイマーを追跡している可能性があることを意味します。
さあ、使ってみましょう!
Beamを初めて使用する場合は、ステートフルな処理を備えたBeamがユースケースに対応するかどうかに興味を持っていただければ幸いです。すでにBeamを使用している場合は、このモデルへの新しい追加が新しいユースケースを切り開くことを願っています。お気に入りのバックエンドでのこの新しいモデル機能のサポートレベルについては、機能マトリックスを確認してください。
また、user@beam.apache.orgでコミュニティに参加してください。皆様からのご連絡をお待ちしております。