



ブログ
2017/08/16
Apache Beamにおける分割可能なDoFnによる強力でモジュール化されたIOコネクタ
Apache Beamエコシステムで最も重要な部分の1つは、Beamパイプラインがさまざまなデータストレージシステム(「IO」)との間でデータを読み書きできるようにする、急速に成長しているコネクタセットです。現在、Beamには20以上のIOコネクタが同梱されており、さらに多くのコネクタが活発に開発されています。IOコネクタに対するユーザーの要求が高まるにつれて、関連するBeam API(特にSource API)の改善に取り組んだ結果、Beamの最も基本的なプリミティブであるDoFnの一般化という予期せぬ結果が得られました。
読者への注意
読者の皆様、こんにちは!このブログは分割可能なDoFn(Splittable DoFn:SDF)の良い入門編ですが、ドキュメントが追いついていない間に書かれました。この記事を読んだ後、公式のBeamドキュメントで、分割可能なDoFnが何であるか、どのように実装するかについての学習を続けることができます。
ミニパイプラインとしてのコネクタ
この活気あるIOコネクタエコシステムの主な理由の1つは、基本的なIOの開発が比較的簡単であることです。多くのコネクタの実装は、基本的なBeamのParDoおよびGroupByKeyプリミティブで構成されるミニパイプライン(複合PTransform)にすぎません。たとえば、ElasticsearchIO.write()は展開されて、パフォーマンス向上のためのバッチ処理を含む単一のParDoになります。JdbcIO.read()は展開されて、Create.of(query)、フュージョンを防ぐためのリシャッフル、およびParDo(execute sub-query)になります。一部のIOは、かなり複雑なパイプラインを構築します。
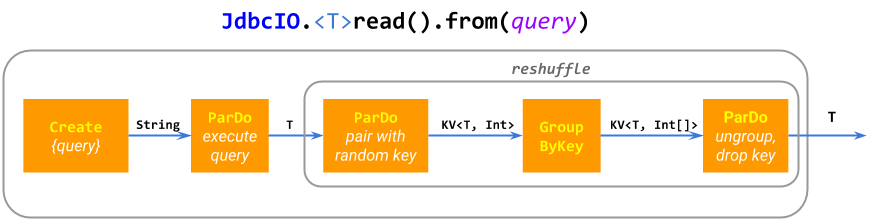
この「ミニパイプライン」アプローチは柔軟性があり、モジュール化されており、動的に計算された場所のPCollectionから読み取るデータソースに一般化できます。たとえば、SpannerIO.readAll()はCloud SpannerからのクエリのPCollectionの結果を読み取りますが、SpannerIO.read()は単一のクエリを実行します。このような動的なデータソースは非常に便利な機能であり、他のデータ処理フレームワークでは見過ごされがちだと考えています。
ParDoとGroupByKeyだけでは不十分な場合
ParDo、GroupByKey、およびそれらの派生物の柔軟性にもかかわらず、効率的なIOコネクタを構築するには、追加の機能が必要になる場合があります。
たとえば、シーケンスParDo(filepattern → ファイルに展開)、ParDo(filename → レコードを読み取る)を使用してファイルを読み取ったり、ParDo(topic → パーティションをリストする)、ParDo(topic, partition → レコードを読み取る)を使用してKafkaトピックを読み取ったりすることを想像してください。このアプローチには2つの大きな問題があります。
ファイル例では、一部のファイルが他のファイルよりもはるかに大きい場合があるため、2番目の
ParDoの個々の@ProcessElement呼び出しが非常に長くなる可能性があります。その結果、パイプラインは処理の遅延が原因でパフォーマンスが低下する可能性があります。Kafkaの例では、2番目の
ParDoを実装することは、通常のDoFnではまったく不可能です。なぜなら、入力要素topic, partitionごとに無限の数のレコードを出力する必要があるからです(ステートフル処理は近いですが、このタスクには不十分な他の制限があります)。
Beam Source API
Apache Beamは歴史的にSource API(BoundedSourceおよびUnboundedSource)を提供しており、これらの制限がなく、バッチおよびストリーミングシステム向けの効率的なデータソースの開発を可能にします。パイプラインは、Read.from(Source)組み込みPTransformを介してこのAPIを使用します。
Source APIは、他のほとんどのデータ処理フレームワークのAPIとほぼ同様であり、システムが複数のワーカーを使用して並行してデータを読み取ったり、無制限のデータソースからの読み取りをチェックポイントして再開したりできるようにします。さらに、BeamのBoundedSource APIは、進捗状況のレポートや動的なリバランス(これらが合わさってオートスケーリングを可能にします)などの高度な機能を提供し、UnboundedSourceはソースのウォーターマークとバックログのレポートをサポートします(SDFまで、私たちは「バッチ」と「ストリーミング」のデータソースは根本的に異なり、したがって根本的に異なるAPIが必要であると考えていました)。
残念ながら、これらの機能には代償が伴います。Source APIに対してコーディングするには多くのボイラープレートが含まれており、エラーが発生しやすく、Sourceはパイプラインのルートにのみ表示できるため、Beamモデルの他の部分とうまく構成できません。例えば
Source APIを使用すると、ファイルパターンの
PCollectionを読み取ることはできません。Sourceは、サイド入力を読み取ったり、他のパイプラインステップがデータを生成するのを待つことはできません。Sourceは、(たとえば、解析に失敗したレコードなどの)追加の出力を出力することはできません。
Source APIは、それ自体とも構成できません。たとえば、アリスが新しい一致ファイルを監視する無制限のSourceを実装し、ボブがファイルをテールする無制限のSourceを実装するとします。Source APIでは、ソースを単純に連結して、ディレクトリ内の新しいログファイル内の新しいレコードを返すSourceを取得することはできません(これは非常に一般的なユーザーの要求です)。代わりに、このようなソースはほとんどゼロから開発する必要があり、私たちの経験から、このようなSourceのフル機能を備えたモノリシックな実装は信じられないほど困難でエラーが発生しやすいことがわかっています。
Source APIに関するもう1つのクラスの問題は、その厳格な境界あり/なしの二分法に起因します。
たとえば、シーケンス
[a, b)を生成するBoundedSourceと、シーケンス[a, inf)を生成するUnboundedSourceなど、見た目上は非常に似ている境界ありソースと境界なしソースの間でコードを再利用することは困難または不可能です。Beam Java SDKでは、何も共有していません。非常に大きく、継続的に成長しているデータセットの取り込みをどのように分類するかは明確ではありません。「既に使用可能」な部分を取り込むには、
BoundedSourceが必要なようです。ランナーはサイズを知ることでメリットが得られ、動的なリバランスを実行できる可能性があります。ただし、継続的に到着する新しいデータを取り込むには、ウォーターマークを提供するためにUnboundedSourceが必要なようです。この観点から、SourceAPIには、ラムダアーキテクチャと同じ問題があります。
約2年前、私たちはSource APIの制限に対処する方法を考え始め、最終的に驚くべきことに、代わりにDoFnの制限に対処することになりました。
分割可能なDoFnが登場
分割可能なDoFn(Splittable DoFn:SDF)は、DoFnの一般化であり、DoFnの構文、柔軟性、モジュール性、コーディングの容易さを維持しながら、Sourceのコア機能を提供します。その結果、これまでよりも強力なIOコネクタを、より短く、よりシンプルで、再利用可能なコードで開発できるようになります。
Sourceとは異なり、SDFは通常のDoFnと同様に、明確な境界あり/なしのAPIを持たないことに注意してください。これらのユースケースとそれらの間のすべてをカバーするAPIは1つしかありません。したがって、SDFは、Apache Beamの統合されたバッチ/ストリーミングプログラミングモデルの最後のギャップを埋めます。
以下に示すSDFの説明を読むときは、ファイル名を入力として受け取り、そのファイル内のレコードを出力するDoFnの実行例を念頭に置いてください。Source APIに詳しい人は、SDFを、ソース自体をパイプライン内の単なる別のデータとして扱い、ソースのPCollectionを読み取る方法として考えると便利かもしれません(実際、これはSDFの作成につながる作業の中で初期のデザイン反復の1つでした)。
Sourceが通常のDoFnよりも優位性を持つ2つの側面は次のとおりです。
分割可能性:単一の要素に
DoFnを適用することはモノリシックですが、Sourceから読み取ることは非モノリシックです。Source全体を一度に読み取る必要はありません。むしろ、バンドルと呼ばれる部分に分けて読み取られます。たとえば、通常、大きなファイルは、ファイル内のオフセットのサブ範囲を読み取る複数のバンドルで読み取られます。同様に、Kafkaトピック(もちろん、「完全に」読み取ることはできません)は、有限数の要素を読み取る各バンドルで、無限の数のバンドルで読み取られます。ランナーとの相互作用: ランナーは
DoFnを単一の要素に対して「ブラックボックス」として適用しますが、Sourceとは非常に密接に相互作用します。Sourceは、推定サイズ(またはその一般化である「バックログ」)、バンドルの読み込みの進行状況、ウォーターマークなどの情報をランナーに提供します。ランナーはこの情報を使用して実行を調整し、Sourceのバンドルへの分割を制御します。たとえば、ファイルの進行が遅い大規模なバンドルは、ストラグラーになる前に、バッチ処理に重点を置いたランナーによって動的に分割される場合があり、レイテンシに重点を置いたストリーミングランナーは、レイテンシとバンドルごとのオーバーヘッドのバランスを最適化するために、各バンドルでソースから読み取る要素数を制御する場合があります。
制限付きの非モノリシックな要素処理
分割可能な DoFn は、単一の要素の処理を非モノリシックにすることで、Source のような機能をサポートします。
SDFによる1つの要素の処理は、(無限の可能性もある)多数の制限に分解されます。各制限は、要素全体に対して実行される作業の一部を記述します。SDFの@ProcessElement呼び出しへの入力は、要素と制限のペアです(要素のみを受け取る通常のDoFnと比較して)。
すべての要素の処理は、作業全体を記述する初期制限を作成することから始まり、初期制限は、論理的に元の制限に追加されるサブ制限にさらに分割されます。たとえば、ファイル名を受け取り、ファイル内のレコードを出力する分割可能な DoFn ReadFn の場合、制限は開始バイトオフセットと終了バイトオフセットのペアになり、ReadFn はそれを指定された範囲内で開始オフセットを持つレコードを読み取ると解釈できます。
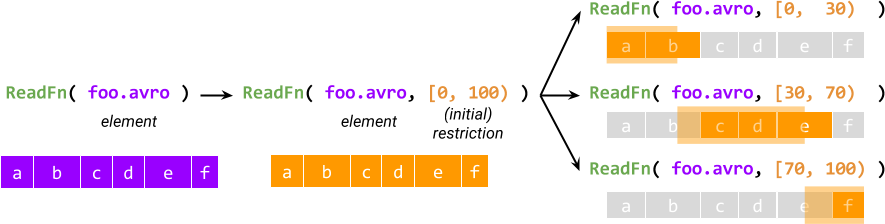
制限の概念は、非モノリシックな実行を提供します。これは、Sourceとの同等性を実現するための最初の要素です。もう1つの要素はランナーとの相互作用です。ランナーは、SDFのアクティブな@ProcessElement呼び出しの制限にアクセスでき、呼び出しの進行状況を照会できます。そして最も重要なのは、処理中に制限を分割できることです(したがって、名前が分割可能なDoFnとなります)。
分割すると、分割される元の制限に追加されるプライマリ制限と残余制限が生成されます。現在の@ProcessElement呼び出しはプライマリの処理を継続し、残余は別の@ProcessElement呼び出しによって処理されます。たとえば、ランナーは、別のワーカーで並行して処理されるように残余をスケジュールできます。
実行中の@ProcessElement呼び出しの分割には、2つの非常に重要な用途があります。
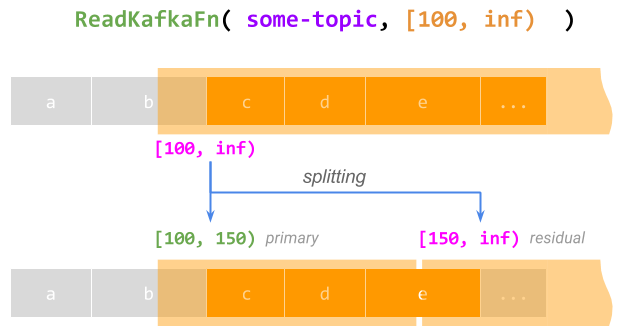
- 要素ごとの無限の作業のサポート。制限は、一般に、有限量の作業を記述する必要はありません。たとえば、オフセット100から始まるKafkaトピックからの読み取りは、制限[100, inf)で表すことができます。この制限全体を処理する
@ProcessElement呼び出しは、もちろん、完了することはありません。ただし、そのような呼び出しが実行されている間、ランナーは制限を有限のプライマリ[100, 150)(現在の呼び出しにこの部分を完了させる)と、後で処理される無限の残余[150, inf)に分割して、実質的に呼び出しをチェックポイントして再開できます。これは永遠に繰り返すことができます。
- 動的なリバランス。(通常はバッチ処理に重点を置いた)ランナーが、
@ProcessElement呼び出しに時間がかかりすぎ、ストラグラーになると検出した場合、プライマリがストラグラーにならないほど短くなるように、制限をある割合で分割し、別のワーカーで並行して残余をスケジュールできます。詳細については、No Shard Left Behindを参照してください。
論理的には、要素に対するSDFの実行は、次の図に従って行われます。ここで、「魔法」は、制限を分割し、残余の処理をスケジュールするランナー固有の能力を表します。
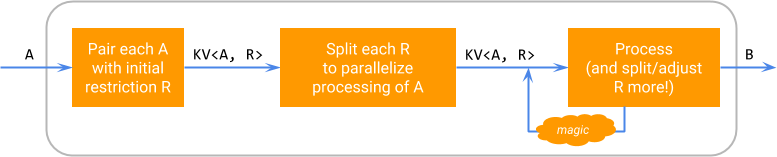
この図は、分割可能性が特定のDoFnの実装の詳細であることを強調しています。分割可能なDoFnは、ユーザーにとってはDoFn<A, B>のように見え、ParDoを介してPCollection<A>に適用してPCollection<B>を生成できます。
どのDoFnを分割可能にする必要があるか
要素を要素/制限ペアに分解することは、自動または「魔法」ではないことに注意してください。SDFは、既存のDoFnを実行する新しい方法ではなく、DoFnを作成するための新しいAPIです。DoFnを分割可能にする場合、作成者は次のことを行う必要があります。
要素ごとに実行する作業の構造を検討します。
制限を使用してこの作業の一部を記述するためのスキームを考案します。
初期制限を作成し、それを分割し、要素/制限のペアを実行するためのコードを作成します。
ユーザーパイプラインにあるDoFnの圧倒的な大多数は、分割可能にする必要はありません。SDFは高度で強力なAPIであり、主に新しいIOコネクタの作成者を対象としています(ただし、興味深い非IOアプリケーションもあります:非IOの例を参照)。
制限の実行とデータの一貫性
分割可能なDoFn設計の最も重要な部分の1つは、分割中にデータの一貫性をどのように実現するかに関連しています。たとえば、ランナーがアクティブな@ProcessElement呼び出しの制限を分割する準備をしている間、呼び出しが分割のポイントを既に超えていないことをどのように確認できますか?
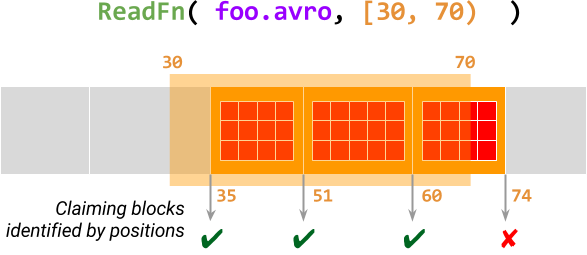
これは、制限の処理が特定のパターンに従うことを要求することによって実現されます。制限をブロックのシーケンスと見なします。ブロックは、位置で識別される、作業の最小単位の分割不可能なユニットです。@ProcessElement呼び出しは、ブロックの位置をクレームして、そのブロックがまだ制限の範囲内にあるかをアトミックにチェックし、制限全体が処理されるまで、ブロックを1つずつ処理します。
下の図は、制限[30, 70)を持つ要素foo.avroを処理するReadFn(Avroファイルを読み取る分割可能なDoFn)のこの様子を示しています。この@ProcessElement呼び出しは、オフセット30から始まるデータブロックに対してAvroファイルをスキャンし、この範囲内の各ブロックの位置をクレームします。ブロックが正常にクレームされた場合、呼び出しはこのデータブロック内のすべてのレコードを出力します。それ以外の場合、終了します。
詳細については、設計提案書の制限、ブロック、位置を参照してください。
コード例
SDFコードの例を見てみましょう。この例では、Beam Java SDKを使用します。Beam Java SDKは、分割可能なDoFnを、柔軟なアノテーションベースのDoFnメカニズムの一部として表現し、Python用の提案されたSDF構文を使用します。
分割可能な
DoFnはDoFnです。新しい基本クラスは必要ありません。SDFはすべてDoFnクラスから派生し、@ProcessElementメソッドを持ちます。@ProcessElementメソッドは、現在の要素に加えて、現在の制限にアクセスできるようにする追加のRestrictionTrackerパラメーターを受け取ります。SDFは、特定の要素に対する作業全体を記述する制限を作成できる
@GetInitialRestrictionメソッドを定義する必要があります。初期制限をいくつかの小さな制限に事前分割するための
@SplitRestrictionや、その他いくつかの重要度の低いオプションのメソッドがあります。
SDFの「Hello World」はカウンターで、入力としてペア(x, N)を受け取り、出力としてペア(x, 0), (x, 1), …, (x, N-1)を生成します。
class CountFn<T> extends DoFn<KV<T, Long>, KV<T, Long>> {
@ProcessElement
public void process(ProcessContext c, OffsetRangeTracker tracker) {
for (long i = tracker.currentRestriction().getFrom(); tracker.tryClaim(i); ++i) {
c.output(KV.of(c.element().getKey(), i));
}
}
@GetInitialRestriction
public OffsetRange getInitialRange(KV<T, Long> element) {
return new OffsetRange(0L, element.getValue());
}
}
PCollection<KV<String, Long>> input = …;
PCollection<KV<String, Long>> output = input.apply(
ParDo.of(new CountFn<String>());class CountFn(DoFn):
def process(element, tracker=DoFn.RestrictionTrackerParam)
for i in xrange(*tracker.current_restriction()):
if not tracker.try_claim(i):
return
yield element[0], i
def get_initial_restriction(element):
return (0, element[1])この短いDoFnは、CountingSourceの機能を包含していますが、より柔軟性があります。CountingSourceは、パイプライン構築時に指定された1つのシーケンスのみを生成しますが、このDoFnは、入力コレクション内の要素ごとに1つずつ、動的なシーケンスファミリーを生成できます(入力コレクションが有界か非有界かは関係ありません)。
ただし、CountingSourceのSource固有の機能は、CountFnでも利用できます。たとえば、シーケンスに多数の要素がある場合、バッチ処理に重点を置いたランナーは、動的なリバランスを適用して、OffsetRangeを分割することにより、シーケンスの異なるサブ範囲を並行して生成できます。同様に、ストリーミングに重点を置いたランナーは、同じ分割ロジックを使用して、実質的に無限である場合でも(たとえば、KV(..., Long.MAX_VALUE)に適用される場合)、シーケンスの生成をチェックポイントして再開できます。
少し複雑な例は、上記のReadFnで、Avroファイルからデータを読み取り、ブロックの概念を示しています。アプローチを説明するための擬似コードを提供します。
class ReadFn extends DoFn<String, AvroRecord> {
@ProcessElement
void process(ProcessContext c, OffsetRangeTracker tracker) {
try (AvroReader reader = Avro.open(filename)) {
// Seek to the first block starting at or after the start offset.
reader.seek(tracker.currentRestriction().getFrom());
while (reader.readNextBlock()) {
// Claim the position of the current Avro block
if (!tracker.tryClaim(reader.currentBlockOffset())) {
// Out of range of the current restriction - we're done.
return;
}
// Emit all records in this block
for (AvroRecord record : reader.currentBlock()) {
c.output(record);
}
}
}
}
@GetInitialRestriction
OffsetRange getInitialRestriction(String filename) {
return new OffsetRange(0, new File(filename).getSize());
}
}class AvroReader(DoFn):
def process(filename, tracker=DoFn.RestrictionTrackerParam)
with fileio.ChannelFactory.open(filename) as file:
start, stop = tracker.current_restriction()
# Seek to the first block starting at or after the start offset.
file.seek(start)
block = AvroUtils.get_next_block(file)
while block:
# Claim the position of the current Avro block
if not tracker.try_claim(block.start()):
# Out of range of the current restriction - we're done.
return
# Emit all records in this block
for record in block.records():
yield record
block = AvroUtils.get_next_block(file)
def get_initial_restriction(self, filename):
return (0, fileio.ChannelFactory.size_in_bytes(filename))この仮想のDoFnは、単一のAvroファイルからレコードを読み取ります。ファイルパターンを展開するコードが特に欠落しています。これは、このDoFnの一部である必要がなくなりました。代わりに、SDKには、ファイルパターンをファイル名のPCollectionに展開するためのFileIO.matchAll()変換が含まれており、異なるファイル形式のIOは、同じ変換を再利用して、異なるDoFnでファイルを読み取ることができます。
この例は、SDFによって可能になるモジュール性の向上による利点を示しています。FileIO.matchAll()は、.continuously()を使用してストリーミングパイプラインでの新しいファイルの継続的な取り込みをサポートしており、この機能は、さまざまなファイル形式のIOで自動的に利用可能になります。たとえば、TextIO.read().watchForNewFiles()は、内部でFileIO.matchAll()を使用しています)。
現在のステータス
分割可能なDoFnは、主要な新しいAPIであり、その提供と広範な採用には、Apache Beamエコシステムのさまざまな部分での多くの作業が必要です。その作業の一部は既に完了しており、新しいIOコネクタを通じてユーザーに直接的なメリットを提供しています。ただし、多くの作業が進行中または計画されています。
2017年8月現在、SDFはBeam Java DirectランナーとDataflowストリーミングランナーで使用でき、FlinkおよびApexランナーで実装が進行中です。現在のステータスについては、機能マトリックスを参照してください。Python SDKでのSDFのサポートは、活発に開発中です。
いくつかのSDFベースの変換とIOコネクタがHEADでBeamユーザーに利用可能になり、Beam 2.2.0に含まれる予定です。TextIOとAvroIOは、.watchForNewFiles()を介して、(最も頻繁に要求された機能の1つである)ファイルの継続的な取り込みを最終的に提供します。これは、ユーティリティ変換FileIO.matchAll().continuously()と、より一般的なWatch.growthOf()によってサポートされています。これらのユーティリティ変換は、「パワーユーザー」のユースケースにも独立して役立ちます。
現在Source APIに基づいているIOのより柔軟なユースケースを可能にするため、これらをSDFを使用するように変更します。この移行はTextIOによって先導されており、SDFを直接実行する機能を持たないランナーをサポートするために、一時的にSource API経由でSDFを実行することを含みます。
新しいIOを可能にするだけでなく、SDFに関する作業は、Beamプログラミングモデルの他の部分に関する私たちの考え方にも影響を与えています。
SDFは、バッチ/ストリーミングに依存しない(
SourceAPI)Beamプログラミングモデルの最後の残りの部分を統一しました。これにより、純粋にバッチまたはストリーミングとして記述できないユースケース(例えば、大量の履歴データをインジェストし、リアルタイムでより多くのデータが到着し続けるなど)を検討し、「進捗」と「バックログ」の統一された概念を開発しました。Fn API - Beamの将来のクロスランゲージパイプラインのサポートの基盤 - は、データ取り込みを表す唯一の概念としてSDFを使用しています。
SDFの実装は、パイプライン終了セマンティクスを形式化し、ランナー間で一貫性を持たせることにつながりました。
SDFは、モジュール式IOコネクターがどのようにあるべきかの新しい基準を確立し、非SDFベースのコネクター(例えば、
SpannerIO.readAll()や計画中のJdbcIO.readAll())向けの同様のAPIの作成を促しました。
行動喚起
Apache Beamは、多数の貢献者コミュニティを持つことで繁栄しています。SDFの取り組みに参加し、Beam IOコネクターのエコシステムをよりモジュール化するために貢献できる方法をいくつかご紹介します。
現在利用可能なSDFベースのIOコネクターを使用し、フィードバックを提供し、バグを報告し、改善点を提案または実装してください。
SDFに基づいて新しいIOコネクターを提案または開発してください。
お気に入りのランナーでのSDFのサポートを実装または改善してください。
user@beam.apache.org(Beamユーザー向けのメーリングリスト)およびdev@beam.apache.org(Beam開発者向けのメーリングリスト)でのSDF関連の議論に参加して貢献してください。