



ブログ
2024/01/03
Apache Beamでのストリーミングワークロードのスケーリング:1秒あたり100万イベント以上

ストリーミングワークロードのスケーリングは、パイプラインが大量のデータを処理できると同時に、レイテンシを最小限に抑え、効率的に実行することを保証するために非常に重要です。適切なスケーリングがないと、パイプラインはパフォーマンスの問題が発生したり、完全に失敗したりする可能性があり、ビジネスにとってのインサイトを得るまでの時間が遅れます。
Apache Beamがワークロードに必要なソースとシンクをサポートしているため、ストリーミングパイプラインの開発は簡単です。処理(変換、エンリッチメント、または集計)と、各ケースに適した構成を設定することに集中できます。
ただし、主要なパフォーマンスボトルネックを特定し、パイプラインが負荷を効率的に処理するために必要なリソースを確保する必要があります。これには、ワーカーの数の適切なサイズ設定、パイプラインのソースとシンクに必要な設定の理解、処理ロジックの最適化、さらにはトランスポート形式の決定が含まれる場合があります。
この記事では、Apache Beamで開発され、Dataflowを使用してGoogle Cloudで実行されるストリーミングワークロードのスケーリングと最適化の問題を管理する方法について説明します。目標は、1秒あたり100万件のイベントに到達することであり、実行中のレイテンシとリソース使用量を最小限に抑えることです。ワークロードは、ストリーミングソースとしてPub/Subを使用し、シンクとしてBigQueryを使用します。ワークロードが目的のスケールを達成し、それを超えるために使用した構成設定とコード変更の背後にある理由について説明します。
この記事で説明する進捗状況は、簡略化された現実のワークロードの進化に対応しています。パイプラインの初期のビジネス要件が達成された後、焦点はパフォーマンスの最適化とパイプラインの実行に必要なリソースの削減に移りました。
実行設定
この記事では、パイプラインの実行に必要なコンポーネントを作成するテストスイートを作成しました。コードはこのGitHubリポジトリにあります。各実行で導入される後続の構成変更は、このフォルダーに、同様の結果を達成するために実行できるスクリプトとしてあります。
すべての実行スクリプトは、Terraformベースの自動化を実行して、ワークロードを実行するためのPub/Subトピックとサブスクリプション、およびBigQueryデータセットとテーブルを作成することもできます。また、2つのパイプラインを起動します。1つはPub/Subトピックにイベントをプッシュするデータ生成パイプライン、もう1つは改善の可能性を示すインジェストパイプラインです。
すべての場合において、パイプラインは空のPub/Subトピックとサブスクリプション、および空のBigQueryテーブルから開始します。計画では、1秒あたり100万件のイベントを生成し、数分後、インジェストパイプラインが時間とともにどのようにスケーリングするかを確認します。自動生成されるデータは、構成に与えられたスキーマまたはIDL(またはインターフェース記述言語)に基づいており、目標は、約800バイトから2 KBの範囲のメッセージを生成し、約1 GB/秒のボリュームスループットにすることです。また、インジェストパイプラインはすべての実行で同じワーカータイプ構成(n2d-standard-4 GCEマシン)を使用しており、非常に大規模なフリートを避けるために最大ワーカー数を制限しています。
すべての実行はDataflowを使用してGoogle Cloudで実行されますが、他のサポートされているApache Beamランナーで実行中に、すべての構成と形式の変更をスイートに適用できます。変更と推奨事項はランナー固有のものではありません。
ローカル環境の要件
起動スクリプトを開始する前に、ローカル環境に次の項目をインストールしてください
- 正しい権限を持つ
gcloud - Terraform
- JDK 17以降
- Maven 3.6以降
詳細については、GitHubリポジトリの要件セクションを参照してください。
また、Google Cloudプロジェクトで利用可能なサービス割り当てとリソースを確認してください。具体的には、Pub/Subリージョンキャパシティ、BigQueryインジェスト割り当て、およびテスト用に選択されたリージョンで利用可能なCompute Engineインスタンスです。
ワークロードの説明
インジェストパイプラインに焦点を当てると、ワークロードは簡単です。次の手順を実行します
- Pub/Subから特定の形式(この場合はApache Thrift)でデータを読み取ります
- 潜在的な圧縮およびバッチ設定を処理します(デフォルトでは有効になっていません)
- UDF(デフォルトでは同一性関数)を実行します
- 入力形式を
BigQueryIO変換でサポートされている形式の1つに変換します - 構成されたテーブルにデータを書き込みます
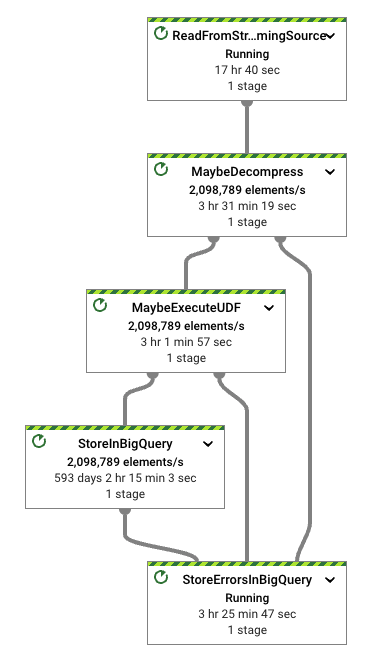
テストに使用したパイプラインは高度に構成可能です。インジェストの調整方法の詳細については、ファイルのオプションを参照してください。いずれのステップでもコードを変更する必要はありません。実行スクリプトは必要な構成を処理します。
これらのテストはPub/Subからのデータの読み取りに重点を置いていますが、インジェストパイプラインは汎用的なストリーミングソースからデータを読み取ることができます。リポジトリには、Pub/Sub LiteおよびKafkaからデータを読み取るこの同じテストスイートを起動する方法を示す他の例が含まれています。いずれの場合も、パイプラインの自動化によってストリーミングインフラストラクチャが設定されます。
最後に、構成オプションでは、パイプラインがThrift、Avro、JSONなどの入力に対して多くのトランスポート形式オプションをサポートしていることを確認できます。このスイートはThriftに焦点を当てています。これは、一般的なオープンソース形式であり、形式変換のニーズを生成するためです。意図は、ワークロード処理にいくらかの負荷をかけることです。AvroおよびJSON入力データについても同様のテストを実行できます。ストリーミングデータジェネレーターパイプラインは、実行用に提供されたスキーマ(AvroとJSON)またはIDL(Thrift)を直接ウォークすることにより、3つのサポートされている形式でランダムデータを生成できます。
最初の実行:デフォルト設定
実行のデフォルト値では、BigQueryIOのSTREAMING_INSERTSモードを使用して、BigQueryにデータが書き込まれます。このモードは、BigQueryのtableData insertAll APIに対応しています。このAPIはJSON形式のデータをサポートしています。Apache Beamの観点からは、BigQueryIO.writeTableRowsメソッドを使用すると、BigQueryへの書き込みを解決できます。
インジェストパイプラインの場合、Thrift形式をTableRowに変換する必要があります。そのためには、Thrift IDLをBigQueryテーブルスキーマに変換する必要があります。これは、Thrift IDLをAvroスキーマに変換し、次にBeamユーティリティを使用してBigQueryのテーブルスキーマを変換することで実現できます。これはブートストラップ時に行うことができます。スキーマ変換はDoFnレベルでキャッシュされます。
データ生成パイプラインとインジェストパイプラインを設定し、パイプラインを数分間実行させた後、パイプラインが目的のスループットを維持できないことがわかります。
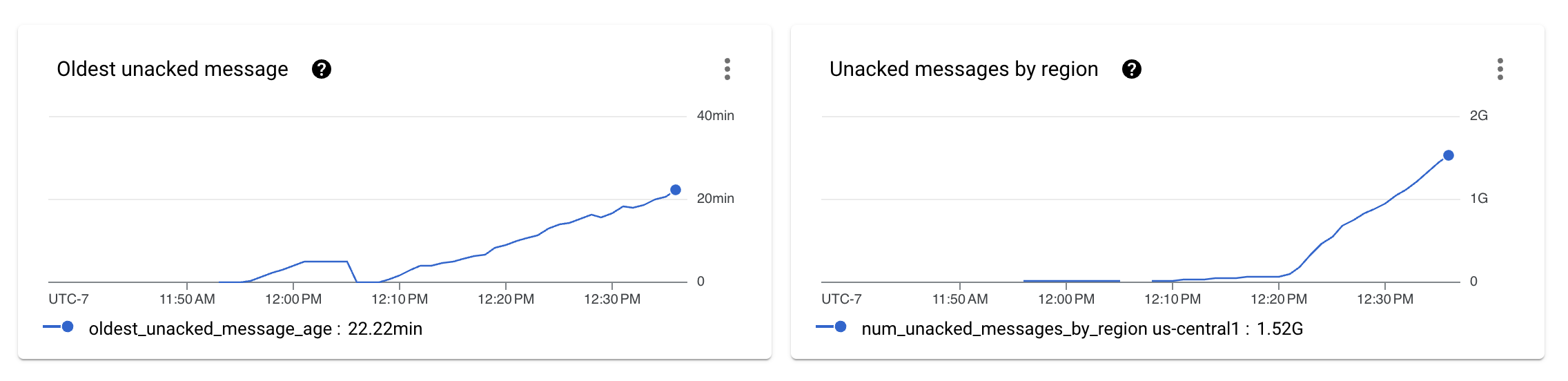
前の図は、インジェストパイプラインで処理されていないメッセージの数がPub/Subメトリクスで未確認メッセージとして表示され始めることを示しています。
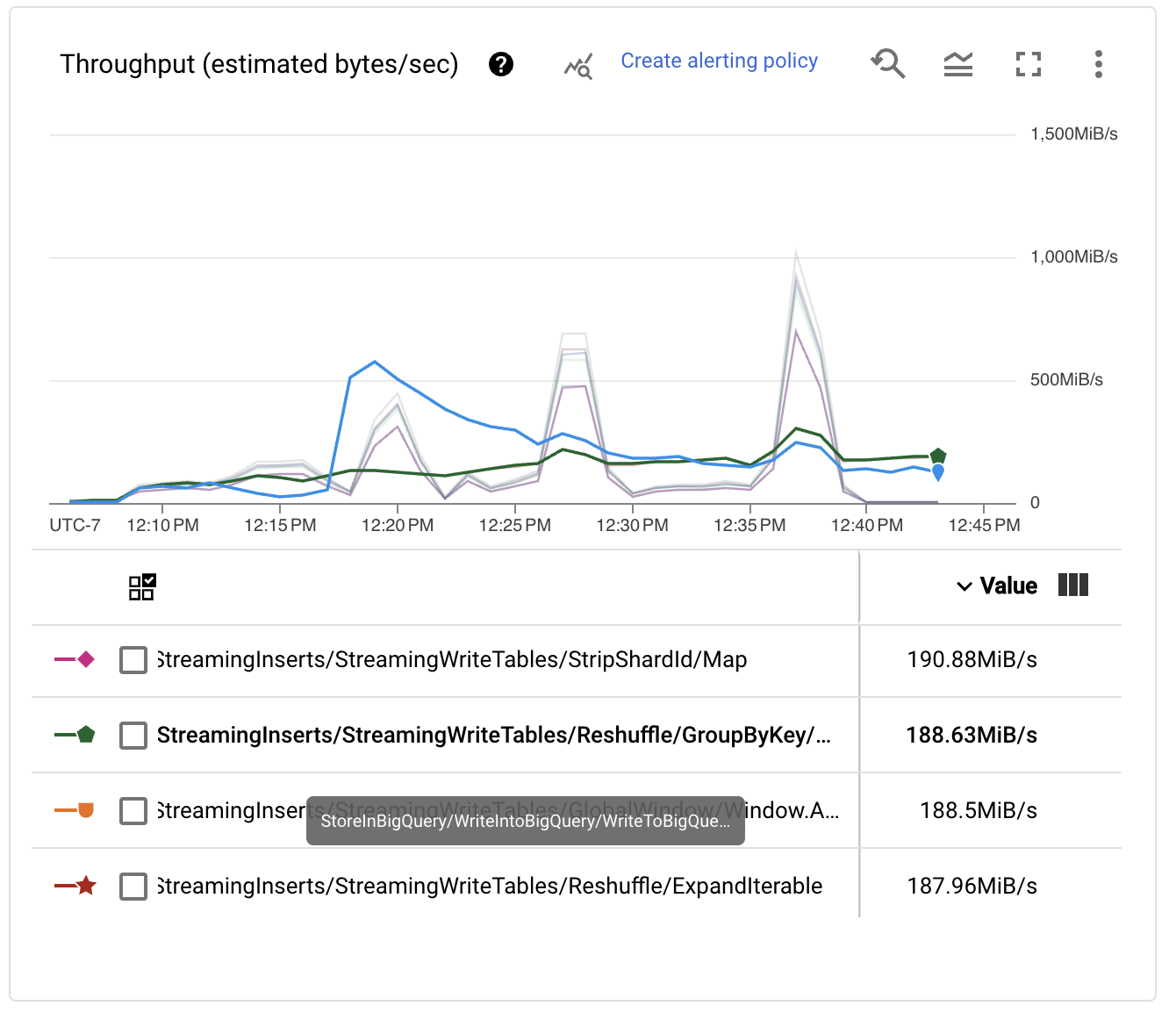
ステージごとのパフォーマンスメトリクスを確認すると、パイプラインが鋸歯状の形状を示しています。これは、一部のステージがスループットのボトルネックとして機能している場合にDataflowランナーが使用するスロットリングメカニズムに関連付けられていることがよくあります。また、BigQueryIO書き込み変換のReshuffleステップが期待どおりにスケールしないことがわかります。
この動作が発生するのは、デフォルトでBigQueryOptionsが、BigQueryでの書き込みが発生する前に、データをワーカーにシャッフルするために50個の異なるキーを使用しているためです。この問題を解決するには、書き込み操作をより多くのワーカーにスケールできるようにする構成を起動スクリプトに追加して、パフォーマンスを向上させることができます。
2回目の実行:書き込みボトルネックの改善
ストリーミングキーの数をより大きな数(この場合は512キー)に増やした後、テストスイートを再起動しました。Pub/Subメトリクスは改善し始めました。バックログのサイズの初期ランプの後、曲線は落ち着き始めました。
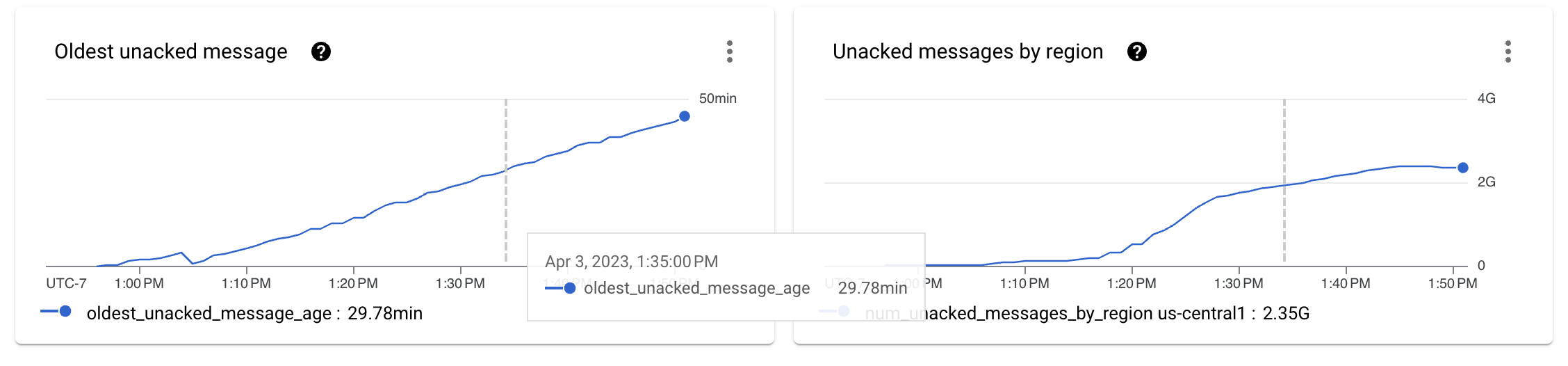
これは良いことですが、この演習で設定した目標を達成しているかどうかを理解するために、ステージごとのスループット数を確認する必要があります。
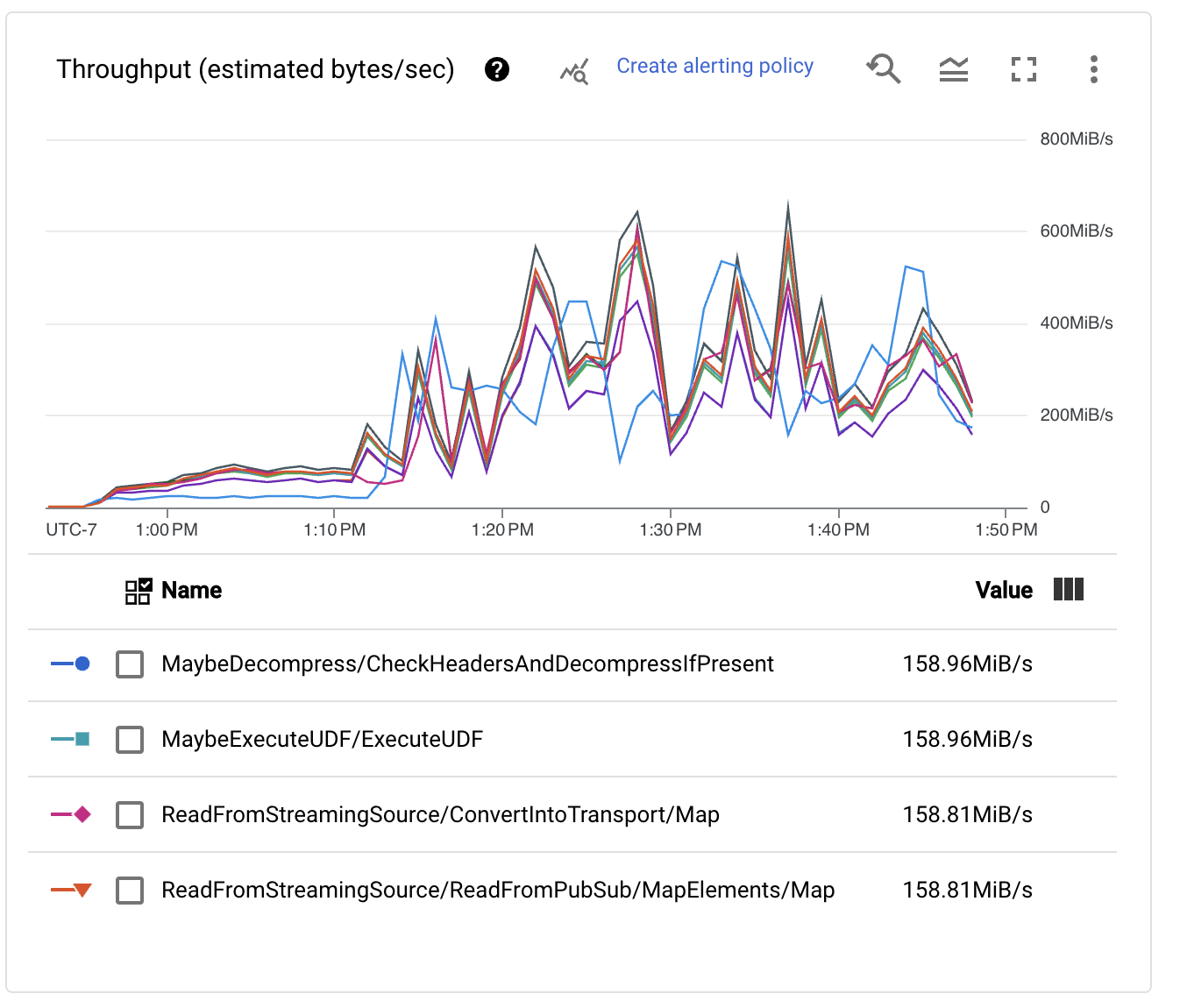
パフォーマンスは明らかに向上し、Pub/Subバックログはもはや単調に増加していませんが、インジェストパイプラインの1秒あたり100万件のイベント(1 GB/秒)の処理という目標にはまだ遠く及んでいません。実際、スループットメトリクスはあちこちにジャンプしており、ボトルネックによって処理がそれ以上スケールできなくなっていることを示しています。
3回目の実行:自動スケーリングの解放
幸いなことに、BigQueryに書き込む場合、書き込みを自動スケーリングできます。このステップにより、適切なシャード数を推測する必要がなくなるように構成が簡素化されます。パイプラインの構成を切り替え、次の起動スクリプトでこの設定を有効にしました。
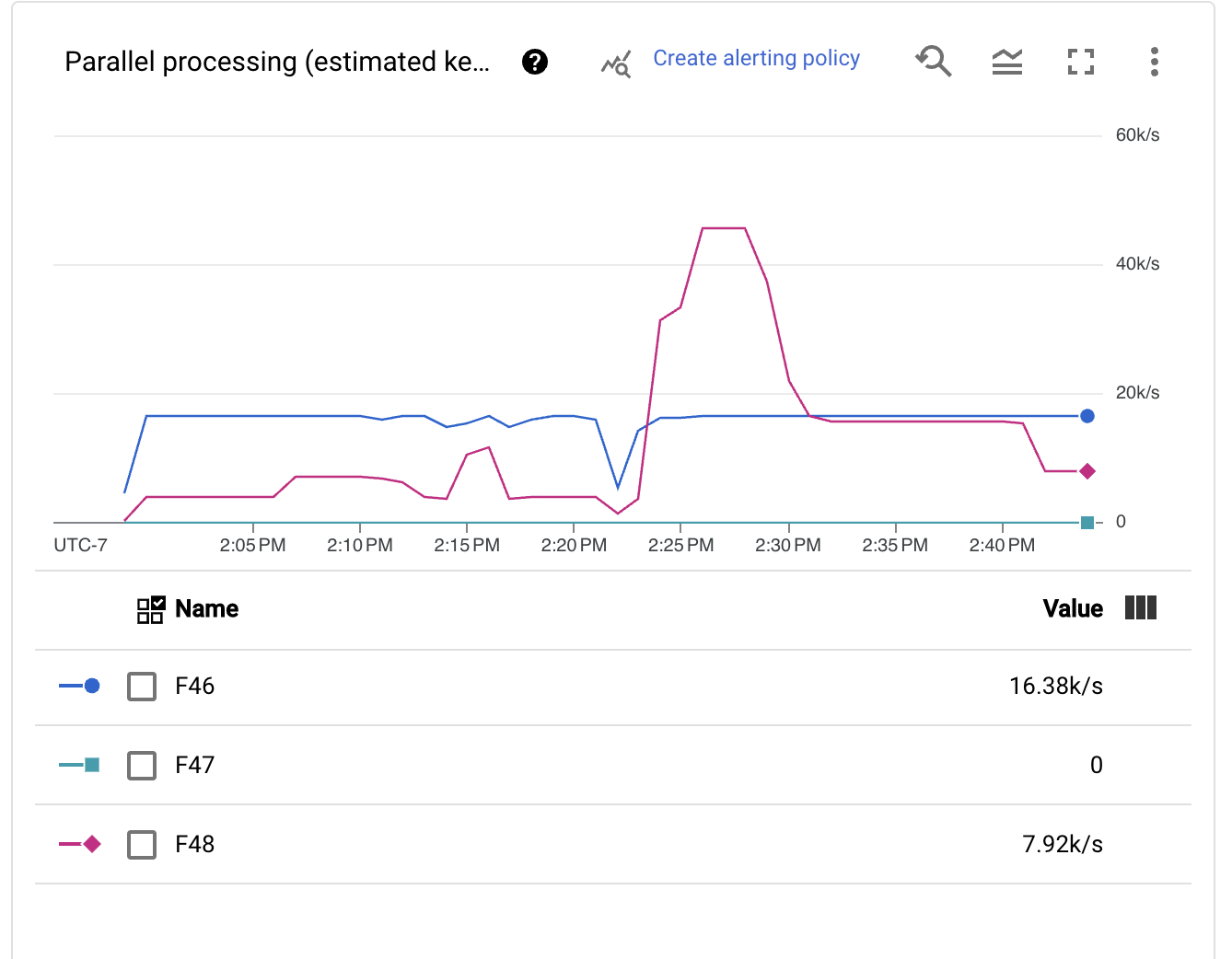
すぐに、自動シャーディングメカニズムがキーの数を非常に積極的に動的な方法で調整していることがわかります。この変更は、初期のバックログ回復や実行のスパイクなど、時間によってスケールのニーズが異なる可能性があるため、優れています。
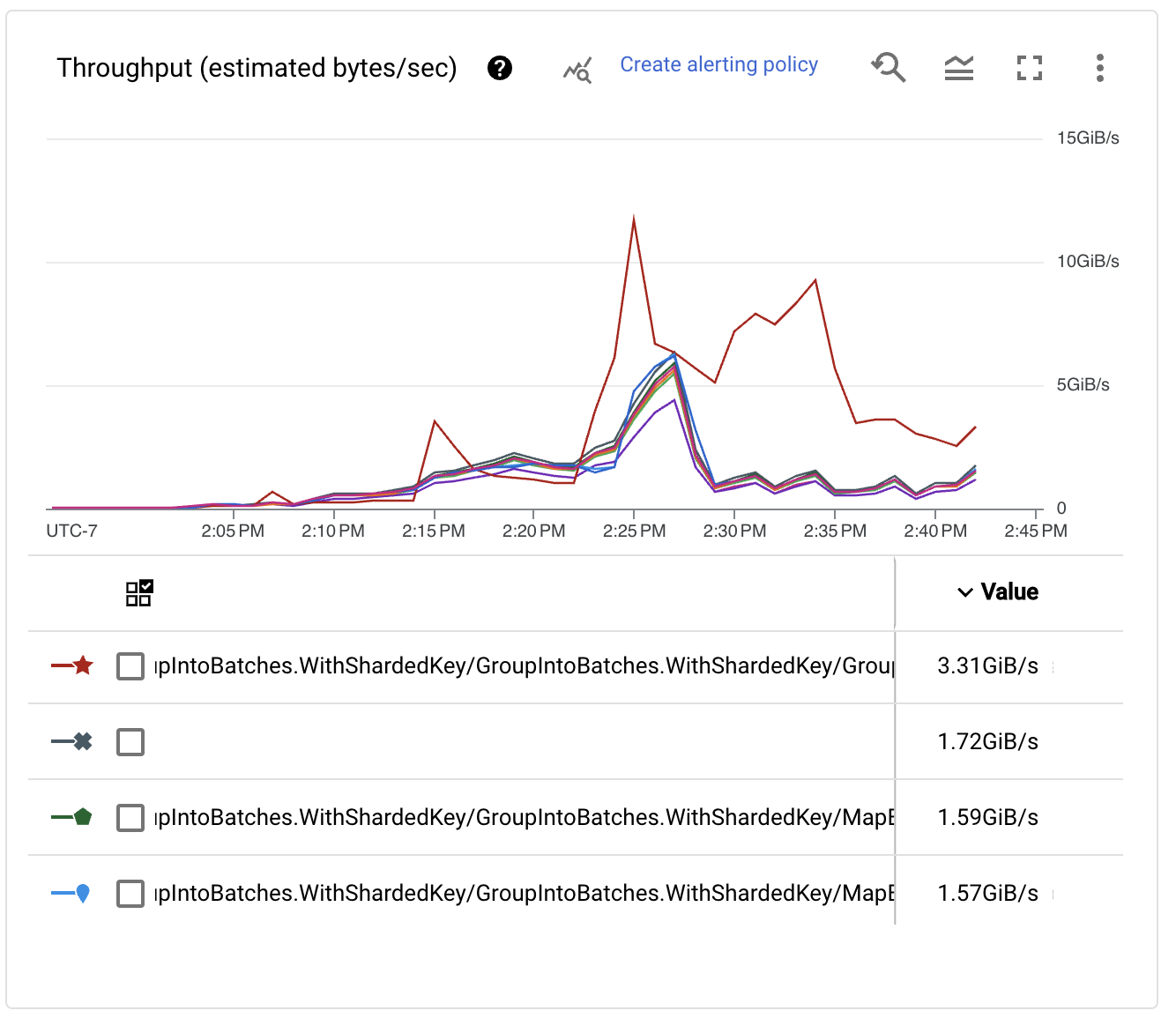
ステージごとのスループットパフォーマンスを調べると、キーの数が増加するにつれて、書き込みのパフォーマンスも向上することがわかります。実際、非常に大きな数値に達します!
初期バックログが消費され、パイプラインが安定した後、目的のパフォーマンス数値に達したことがわかりました。パイプラインは、Pub/Subから1秒あたり100万件以上のイベントを処理し、BigQueryインジェストを数GB/秒で維持できます。やった!
それでも、私たちはさらに改善できるかどうかを検討したいと考えています。パイプラインの実行効率を向上させるために、いくつかの改善策を導入することができます。ほとんどの場合、改善策は構成の変更です。次にどこに焦点を当てるべきかを知るだけで済みます。
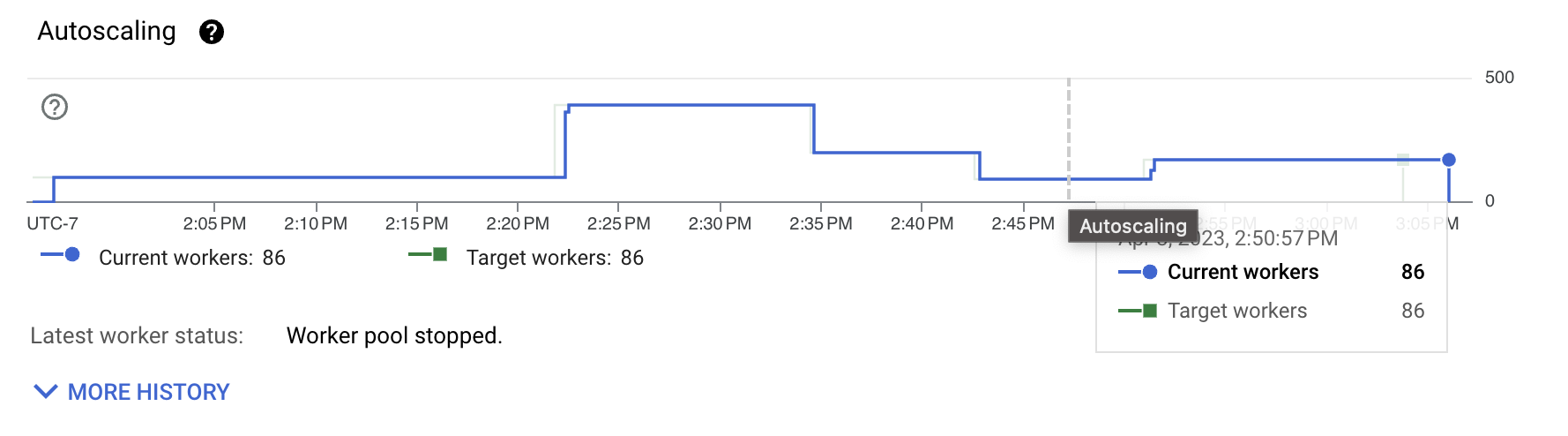
前の図から、このスループットを維持するために必要なワーカーの数が依然としてかなり多いことがわかります。ワークロード自体はCPUを大量に消費するものではありません。コストのほとんどは、形式変換と、シャッフルや実際の書き込みなどのI/Oインタラクションに費やされています。改善すべき点を理解するために、まずトランスポート形式を調査します。
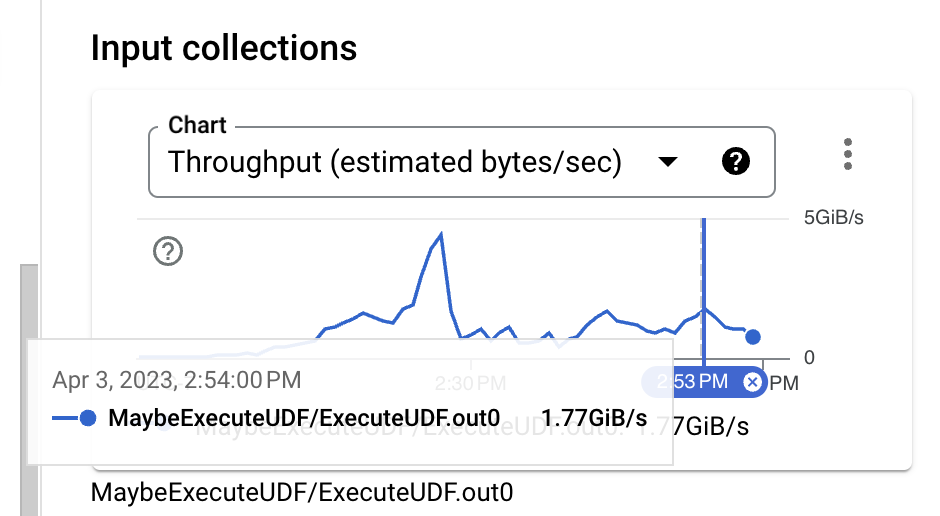
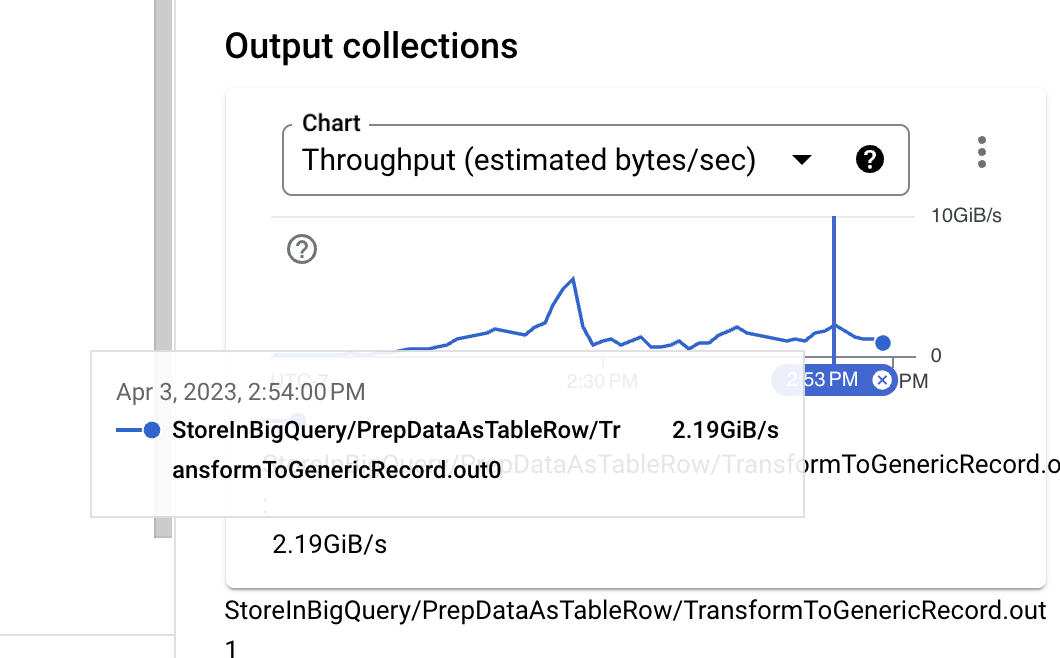
入力サイズを見ると、アイデンティティUDFの実行直前では、データ形式はバイナリThriftであり、圧縮を使用していなくてもかなりコンパクトな形式です。ただし、PCollectionの概算サイズとBigQueryの取り込みに必要なTableRow形式を比較すると、サイズが明らかに増加していることがわかります。これは、使用中のBigQuery書き込みAPIを変更することで改善できます。
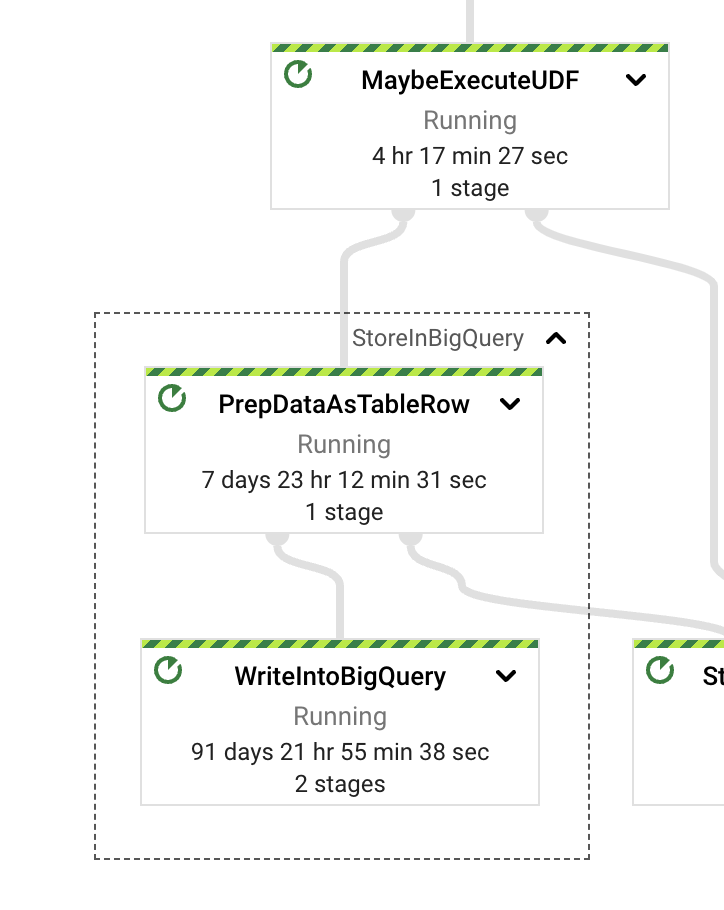
StoreInBigQuery変換を調べると、ウォールタイムの大部分が実際の書き込みに費やされていることがわかります。また、データの変換にかかるウォールタイム(TableRows)と実際の書き込みにかかるウォールタイムを比較すると、書き込みの方が13倍も大きくなっています。この動作を改善するために、パイプラインの書き込みモードを切り替えることができます。
4回目の実行:新しいものを導入
この実行では、StorageWrite APIを使用します。このパイプラインでStorageWrite APIを有効にするのは簡単です。書き込みモードをSTORAGE_WRITE_APIに設定し、書き込みトリガー頻度を定義します。このテストでは、最大10秒ごとにデータを書き込みます。書き込みトリガー頻度は、ストリームごとにデータが蓄積される時間を制御します。数値が大きいほど、ストリーム割り当て後に書き込まれる出力が大きくなりますが、Pub/Subから読み取られるすべての要素のエンドツーエンドのレイテンシーも大きくなります。STREAMING_WRITES構成と同様に、BigQueryIOは書き込みの自動シャーディングを処理できます。これは、パフォーマンスに最適な設定であることがすでに実証されています。
両方のパイプラインが安定した後、BigQueryIOでStorageWrite APIを使用した場合に見られるパフォーマンス上の利点が明らかです。新しい実装を有効にした後、形式変換と書き込み操作の間のウォールタイムレートが減少します。書き込みに費やされるウォールタイムは、形式変換よりも約34%大きいだけです。
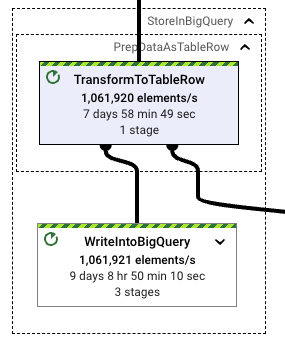
安定化後、パイプラインのスループットも非常にスムーズになります。ランナーは、目的のスループットを維持するために必要なパイプラインリソースを迅速かつ着実に縮小できます。
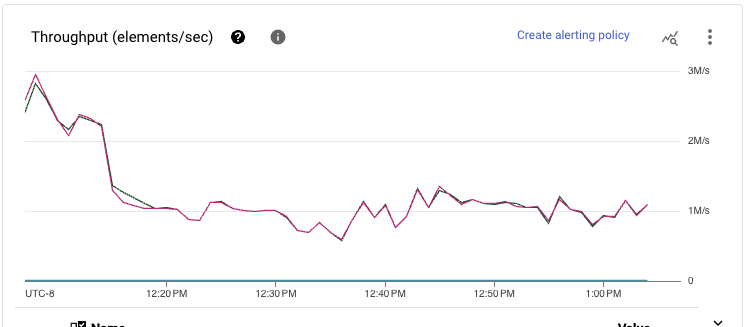
データを処理するために必要なリソーススケールを見ると、もう1つの劇的な改善が見られます。ストリーミング挿入ベースのパイプラインではスループットを維持するために80を超えるワーカーが必要だったのに対し、ストレージ書き込みパイプラインでは49のみで済み、40%の改善が見られます。
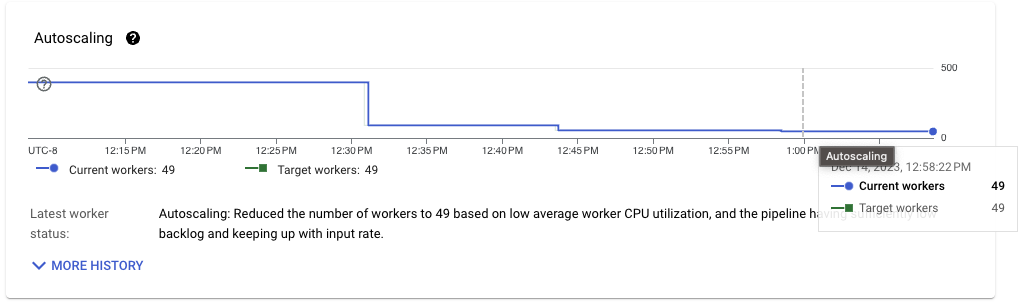
データ生成パイプラインを参考として使用できます。このパイプラインは、データをランダムに生成し、イベントをPub/Subに書き込むだけで済みます。平均40ワーカーで着実に実行されます。ワークロードに適した構成を使用した取り込みパイプラインの改善により、生成に必要なリソースに近づいています。
ストリーミング挿入ベースのパイプラインと同様に、データをBigQueryに書き込むには、形式変換(前者の場合はThriftからTableRow、後者の場合はThriftからプロトコルバッファ(protobuf))を実行する必要があります。BigQueryIO.writeTableRowsメソッドを使用しているため、形式変換にもう1つのステップを追加します。また、TableRow形式では、処理されるPCollectionのサイズも増加するため、このステップを改善できるかどうかを検討したいと思います。
5回目の実行:より良い書き込み形式
STORAGE_WRITE_APIを使用する場合、BigQueryIO変換は、Beam行型をBigQueryに直接書き込むために使用できるメソッドを公開します。このステップは、相互運用性とスキーマ管理のために行型が提供する柔軟性があるため便利です。また、シャッフルにも効率的で、TableRowよりも密度が高いため、パイプラインのPCollectionサイズが小さくなります。
次の実行では、データ量が少なくないため、BigQueryへの書き込み時のトリガー頻度を下げます。異なる形式を使用するため、わずかに異なるコードが実行されます。この変更のために、テストパイプラインスクリプトはフラグ--formatToStore=BEAM_ROWで構成されます。
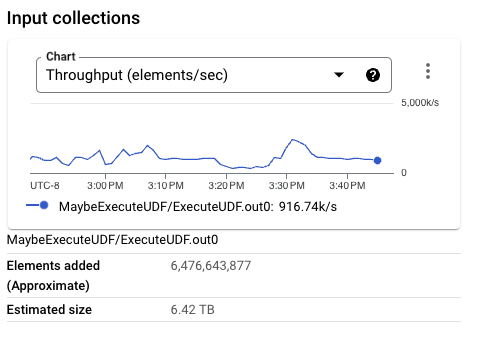
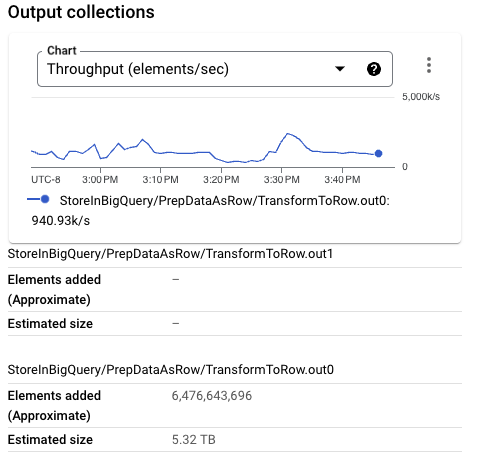
BigQueryに書き込まれるPCollectionのサイズは、以前の実行よりもかなり小さくなっています。実際、この特定の実行では、Beam行形式はThrift形式よりも小さいサイズです。要素ごとのサイズが大きいPCollectionは、ワーカー構成が小さい場合にかなりのメモリプレッシャーをかける可能性があり、全体的なスループットを低下させる可能性があります。
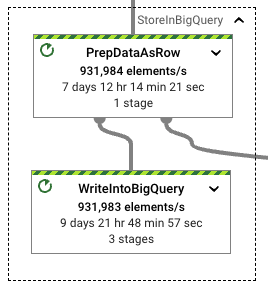
形式変換と実際のBigQuery書き込みのウォールクロックレートも、非常に類似したレートを維持しています。Beam行形式の処理は、形式変換と後続の書き込みでパフォーマンスの低下をもたらしません。これは、スループットが安定したときにパイプラインで使用されるワーカーの数によって確認され、前の実行よりもわずかに小さいものの、明らかに同じ範囲にあります。
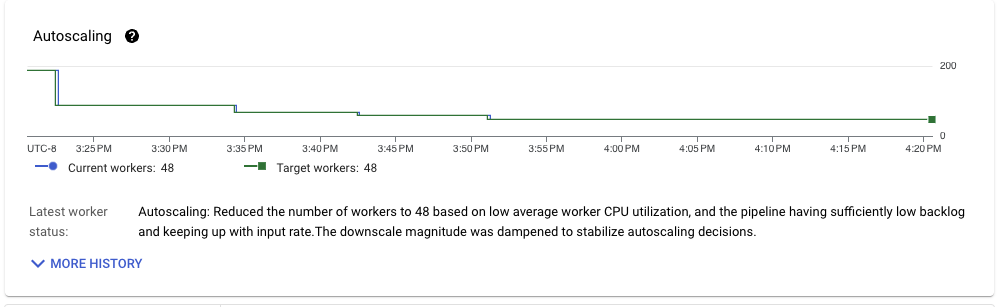
開始時よりもはるかに良い状況にありますが、テストパイプラインの入力形式を考慮すると、まだ改善の余地があります。
6回目の実行:形式変換の労力をさらに削減
BigQueryIO変換での入力PCollectionでサポートされている別の形式が、入力形式に有利になる可能性があります。メソッドwriteGenericRecordsを使用すると、変換は書き込み操作の前にAvro GenericRecordsをprotobufに直接変換できます。Apache Thriftは、非常に効率的にAvro GenericRecordsに変換できます。実行スクリプトでオプション--formatToStore=AVRO_GENERIC_RECORDを設定してテスト取り込みパイプラインを構成することで、別のテスト実行を行うことができます。
今回は、形式変換と書き込みの差が大幅に増加し、パフォーマンスが向上しています。Avro GenericRecordsへの変換は、それらのレコードをBigQueryに書き込むのに費やされる書き込み作業のわずか20%です。テストパイプラインの実行時間が類似しており、WriteIntoBigQueryステージで確認されたウォールクロックも他のStorageWrite関連の実行と一致していることを考えると、この形式を使用することはこのワークロードに適しています。
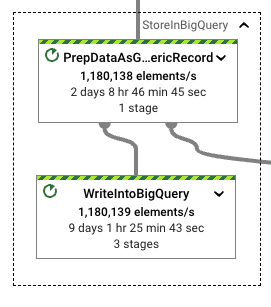
リソースの使用状況を見ると、さらなる利点が見られます。目的のスループットを達成しながら、ワークロードの形式変換を実行するために必要なCPU時間が少なくなります。
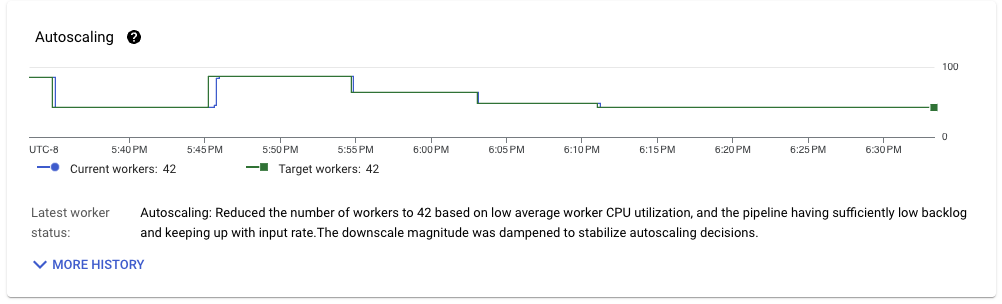
このパイプラインは前の実行よりも改善されており、スループットが安定すると42ワーカーで着実に実行されます。使用されているワーカー構成(nd2-standard-4)とワークロード処理のボリュームスループット(約1GB/秒)を考慮すると、CPUコアあたり約6MB/秒のスループットを達成しており、これはちょうど1回セマンティクスを使用したストリーミングパイプラインとしては非常に印象的です。
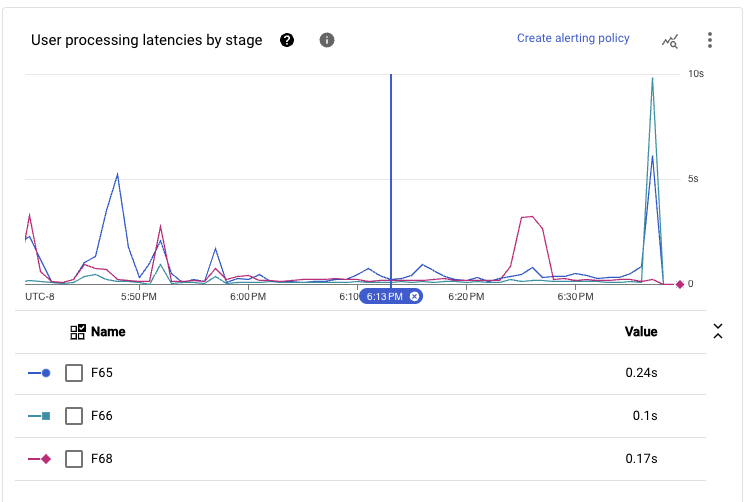
パイプラインのメインパスで実行されるすべてのステージを追加すると、このスケールで観察されるレイテンシーは、継続的な期間中に1秒未満のエンドツーエンドレイテンシーを達成します。
ワークロードの要件と実装されたパイプラインコードを考えると、このパフォーマンスは、ランナーの特定の設定をさらに調整することなく抽出できる最高のパフォーマンスです。
7回目の実行:リラックスしましょう(少なくともいくつかの制約を)
BigQueryIOのSTORAGE\_WRITE\_API設定を使用する場合、書き込みにちょうど1回セマンティクスを適用します。この構成は、処理されるデータに強力な整合性を必要とするユースケースに最適ですが、パフォーマンスとコストのペナルティが発生します。
大まかに言うと、BigQueryへの書き込みはバッチで行われ、現在のシャーディングとトリガー頻度に基づいて解放されます。特定のバンドルの実行中に書き込みが失敗した場合、再試行されます。データのバンドルは、その特定のバンドル内のすべてのデータがストリームに正しく追加された場合にのみ、BigQueryにコミットされます。この実装では、書き込まれるバッチを作成するためにデータの全量をシャッフルする必要があり、また後でコミットするための完了したバッチの情報もシャッフルする必要があります(ただし、この最後の部分は最初と比較して非常に小さいです)。
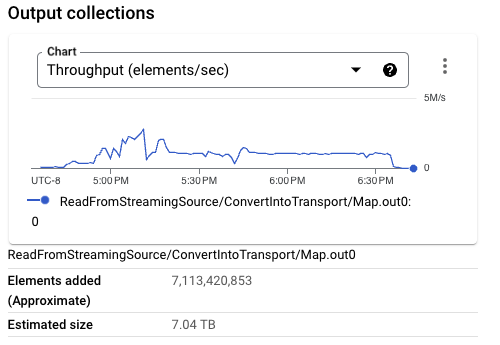
前のパイプライン実行を見ると、Streaming Engineによってパイプライン用に処理される合計データは、Pub/Subから読み取られるデータよりも大きくなっています。たとえば、7TBのデータがPub/Subから読み取られますが、パイプラインの実行全体のデータ処理では、Streaming Engineとの間で25TBのデータが移動します。

データ整合性が取り込みの必須要件ではない場合は、BigQueryIO書き込みモードで少なくとも1回セマンティクスを使用できます。この実装では、書き込みのためにデータのシャッフルとグループ化を回避します。ただし、この変更により、宛先テーブルに少数の重複行が書き込まれる可能性があります。これは、追加エラー、頻繁ではないワーカーの再起動、その他のさらに頻繁ではないエラーで発生する可能性があります。
したがって、STORAGE_API_AT_LEAST_ONCE書き込みモードを使用する構成を追加します。データを書き込んでいる間、StorageWriteクライアントに接続を再利用するように指示するために、構成フラグ–useStorageApiConnectionPoolも追加します。この構成オプションはSTORAGE_API_AT_LEAST_ONCEモードでのみ機能し、Storage Api write delay more than 8 secondsと同様の警告の発生を減らします。
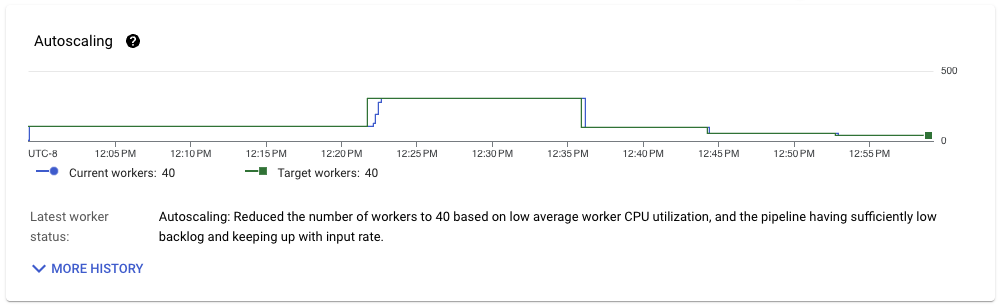
パイプラインスループットが安定すると、ワークロードのリソース使用状況に同様のパターンが見られます。使用中のワーカー数は40に達し、前回の実行と比較してわずかな改善が見られます。ただし、Streaming Engineから移動されるデータ量は、Pub/Subから読み取られるデータ量に非常に近くなっています。
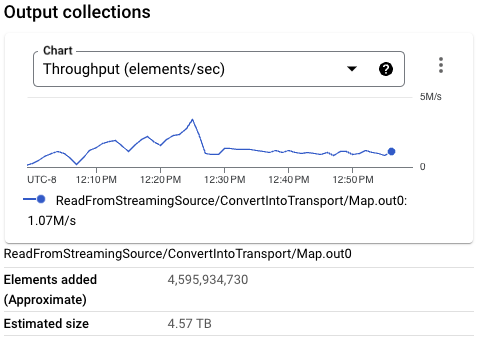

これらの要因をすべて考慮すると、この変更によりワークロードがさらに最適化され、CPUコアあたり6.4MB/秒のスループットが達成されます。この改善は、BigQueryへの一貫した書き込みを使用する場合の同じワークロードと比較すると小さいですが、ストリーミングデータリソースの使用量は少なくなっています。この構成は、ワークロードに最適なセットアップを表しており、リソースあたりのスループットが最大で、ワーカー間でのストリーミングデータが最小です。
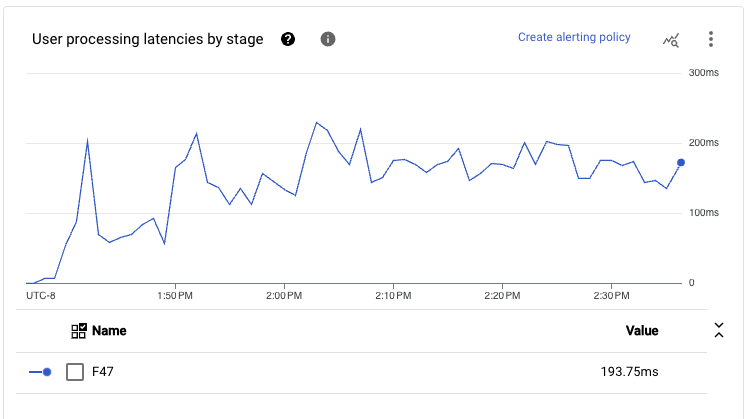
この構成は、エンドツーエンド処理のレイテンシーも非常に低くなっています。パイプラインのメインパスは、読み取りから書き込みまでの単一の実行ステージに融合されているため、p99でも、レイテンシーはかなり大量のスループット(前述のように約1GB/秒)で300ミリ秒を下回る傾向があります。
まとめ
低レイテンシーと効率的な実行のためにApache Beamストリーミングワークロードを最適化するには、慎重な分析と意思決定、および適切な構成が必要です。
この記事で説明したシナリオを考慮すると、ワークロードに適したパイプラインを作成することに加えて、全体的なCPU使用率、ステージごとのスループットとレイテンシー、PCollectionサイズ、ステージごとのウォールタイム、書き込みモード、トランスポート形式などの要素を考慮することが不可欠です。
私たちの実験では、StorageWrite API、書き込みの自動シャーディング、およびトランスポート形式としてAvro GenericRecordsを使用すると、最も効率的な結果が得られることがわかりました。書き込みの一貫性を緩和することで、パフォーマンスをさらに向上させることができます。
付属のGithubリポジトリには、Google Cloudプロジェクトや別のランナー設定で分析を再現できるテストスイートが含まれています。ぜひお試しください。コメントやPRはいつでも歓迎です。