



ブログ
2022/10/15
クラウドDataflowを用いたApache Hopウェブバージョン
Hopは、Dataflow、Flink、Sparkなどの任意のBeamランナーでジョブを実行できる、Apache Beamパイプライン用のコードレスのビジュアル開発環境です。以前の投稿では、Apache Hopのデスクトップバージョンを紹介しました。Hopには、コンテナから実行できるWeb環境であるHop Webもあり、コンピュータに何もインストールしなくても使用できます。
この詳細なチュートリアルでは、Webブラウザを使用してインターネット経由でHopにアクセスし、Google Cloudの仮想マシンで実行されているコンテナを指定します。そのコンテナはDataflowでジョブを起動し、それらのジョブの結果を報告します。Hopインスタンスに誰でもアクセスできるようにしたくないため、あなただけがその仮想マシンにアクセスできるように保護します。次の図は、セットアップを示しています。

前述のデプロイメントを実行し、Webブラウザのみを使用してBeamパイプラインを構築するWebおよびビジュアル開発環境を作成する方法を示します。完了すると、Webブラウザでパイプラインを作成し、Google Cloud Dataflowを使用して起動するために使用できる安全なWeb環境が作成されます。
この例を実行するには何が必要ですか?
Google Cloudを使用しているため、最初に必要なのはGoogle Cloudプロジェクトです。必要に応じて、https://cloud.google.com/freeでGoogle Cloudの無料トライアルにサインアップできます。
プロジェクトを作成したら、追加の設定なしでWebブラウザでCloud Shellを使用できます。Cloud Shellでは、Google Cloud SDKがプロジェクトと認証情報に合わせて自動的に構成されます。ここでは、そのオプションを使用します。または、ローカルコンピュータでGoogle Cloud SDKを構成することもできます。手順については、https://cloud.google.com/sdk/docs/installを参照してください。
Cloud Shellを開くには、[Google Cloudコンソール](http://console.cloud.google.com)にアクセスし、プロジェクトが選択されていることを確認して、Cloud Shellボタン をクリックします。Cloud Shellが開き、この投稿に示されているコマンドを実行するために使用できます。
をクリックします。Cloud Shellが開き、この投稿に示されているコマンドを実行するために使用できます。
次の手順で使用するコマンドは、GithubのGistで入手できます。このチュートリアルからコマンドをコピーする代わりに、そのスクリプトを実行することをお勧めします。
権限とアカウント
Dataflowパイプラインを実行する場合、個人のGoogle Cloud認証情報を使用してジョブを実行できます。ただし、Hop Webは仮想マシンで実行され、Google Cloudでは、仮想マシンは認証情報としてサービスアカウントを使用して実行されます。そのため、Dataflowジョブを実行する権限を持つサービスアカウントがあることを確認する必要があります。
デフォルトでは、仮想マシンは*Compute Engineデフォルトサービスアカウント*というサービスアカウントを使用します。簡単にするために、このアカウントを使用します。それでも、そのサービスアカウントでDataflowジョブを実行するために、いくつかの権限を追加する必要があります。
まず、必要なすべてのGoogle Cloud APIを有効にしていることを確認しましょう。このリンクをクリックして、このワークフローで使用するDataflow、BigQuery、Pub / Subを有効にします。リンクをクリックすると、Google Cloudコンソールのプロジェクトに移動し、そこでAPIを有効にできます。
それでは、VMアカウントに権限を与えましょう。まず、サービスアカウントのIDを見つけます。Cloud Shellを開き、次のコマンドを実行します。
gcloud iam service-accounts list | grep compute
出力は次のようになります。<PROJECT_NUMBER>はプロジェクト番号に置き換えられます。
EMAIL: <PROJECT_NUMBER>-compute@developer.gserviceaccount.com
そのサービスアカウントIDをコピーします。次の手順で使用します。次のコマンドを実行して、サービスアカウントにDataflow管理者ロールを付与します。このロールは、ジョブを実行するために必要です。
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT --member="serviceAccount:<SERVICE_ACCOUNT_ID>" --role="roles/dataflow.admin"
ここで、<SERVICE_ACCOUNT_ID>は、前に取得したIDです。Cloud Shellでこれらのコマンドを実行している場合、環境変数GOOGLE_CLOUD_PROJECTはすでにプロジェクトIDに設定されています。他の場所から実行している場合は、$GOOGLE_CLOUD_PROJECT変数をプロジェクトのIDに設定します。
これで、Dataflowの「ユーザー」はそのサービスアカウントになります。ジョブがBigQuery、Cloud Storage、Pub / Subなどのデータにアクセスしている場合は、それらのサービスのロールもサービスアカウントに付与する必要があります。
ディスクと仮想マシン
Apache HopのDockerコンテナを実行するために、Compute Engineに仮想マシン(VM)を作成しましょう。
Compute Engineでは、VMでコンテナを直接実行できます。Google Cloudでコンテナを実行する他のオプションもありますが、VMが最もシンプルで簡単な方法です。詳細は、Google CloudドキュメントのVMおよびMIGへのコンテナのデプロイページにあります。
このチュートリアルでは、常にゾーンeurope-west1-bで作業するため、多くのコマンドでそのゾーンが表示されます。ただし、任意のGoogle Cloudゾーンを選択できます。 europe-west1-bの代わりに、ゾーンの値を使用することを忘れないでください。ディスクやVMなど、すべてのリソースに常に同じゾーンを使用してください。Hop Webを使用する際のレイテンシを最小限に抑えるには、地理的に近いゾーンを選択してください。ゾーンを定義し、残りのコマンドでこの変数を使用しましょう。
ZONE=europe-west1-b
コンテナには一時的なストレージがあります。コンテナを再起動すると、コンテナのディスクは元の状態に戻ります。そのため、Hop Webコンテナを再起動すると、貴重なパイプラインがすべて失われます。これを回避するために、永続ディスクを作成し、Hop Webでのすべての作業を保存します。次のコマンドを実行して、ディスクを作成します。
gcloud compute disks create my-hop-disk \
--type=pd-balanced \
--size=10GB \
--zone=$ZONE
このディスクのおかげで、仮想マシンを停止しても、Hop Webのすべての個人用ファイルはそのままです。
VMを作成しましょう。VMの場合、ネットワーク(デフォルトでは`default`)を選択する必要があります。そのため、VMにはパブリックIPアドレスがありません。これはセキュリティ上の理由から重要ですが、Identity Aware Proxyのおかげで、WebブラウザからVMを使用できなくなります。これについては後で詳しく説明します。今のところ、VMを作成しましょう。
gcloud compute instances create-with-container my-hop-vm \
--zone=$ZONE \
--network-interface=subnet=default,no-address \
--scopes=https://www.googleapis.com/auth/cloud-platform \
--tags=http-server,https-server,ssh \
--container-image=apache/hop-web:2.0.1 \
--container-restart-policy=on-failure \
--container-mount-disk=mode=rw,mount-path=/root,name=my-hop-disk,partition=0 \
--disk=boot=no,device-name=my-hop-disk,mode=rw,name=my-hop-disk
これらの追加オプションが何であるか疑問が生じるかもしれません。これらは、VMがHop Webで正しく動作するために必要です。たとえば、`scopes`オプションはVMがDataflowを使用できるようにするものであり、`tags`オプションはブラウザがネットワークファイアウォールを介してHop Webアドレスに到達できるようにします。
Apache HopはHTTP接続用にポート8080でリッスンするため、プロジェクトに追加のカスタムファイアウォールルールがある場合は、ポート8080でTCPトラフィックを停止していないことを確認してください。
しかし、ちょっと待ってください。プライベートIPのみを持つマシンを作成しました。WebブラウザからHop Webにアクセスするにはどうすればよいですか?そのためにはパブリックIPアドレスが必要ありませんか?
Google Cloudには、Identity Aware Proxy(IAP)と呼ばれる機能があります。これは、サービスを承認レイヤーでラップして、内部IPのみを持つリソースへの接続を許可するために使用できます。
IAPを使用してApache Hop Webサーバーをラップできます。次のコマンドでは、VMのポート8080に接続するローカルポート8080でリッスンするトンネルを作成します。
gcloud compute start-iap-tunnel my-hop-vm 8080 --local-host-port=localhost:8080 --zone=$ZONE
トンネルを開いたままにするには、そのコマンドを実行したままにします。VMの作成直後にコマンドが失敗した場合は、数秒待ってから再試行してください。コンテナはまだ起動中かもしれません。
これで、Webブラウザを使用して接続できるトンネルができました。Cloud Shellではなくローカルコンピュータでこれらのコマンドを実行している場合は、ブラウザを`localhost:8080`に向けます。Hop UIが読み込まれます。
Cloud Shellでこれらのコマンドを実行している場合、ブラウザはどこを指しますか?Cloud Shellには、このような状況に対応するためのユーティリティが付属しています。Cloud Shellで、**Webプレビュー**ボタンを見つけます。
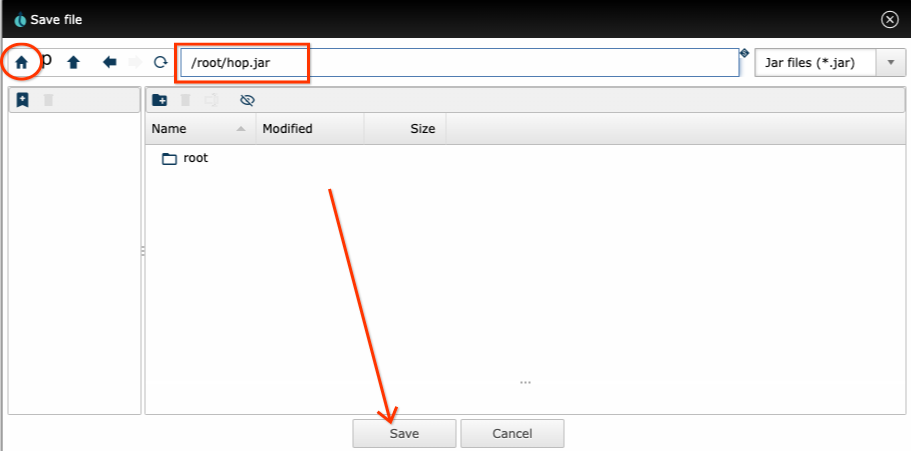
プレビューでポート8080を使用していない場合は、**ポートの変更**をクリックし、ポート8080に切り替えます。**ポートでプレビュー**をクリックすると、Cloud Shellはブラウザでトンネルアドレスを指す新しいタブを開きます。
**Identity Aware Proxy**は、Googleアカウントを使用して身元を確認するように求めます。
その後、Apache Hop Webインターフェースが読み込まれます。
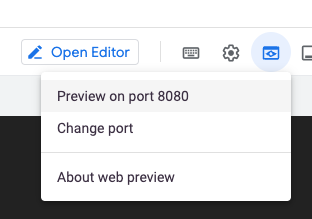
そのURLは、Google Cloudに使用しているものと同じGoogleアカウント(Google Cloud SDKで認証されているアカウント)を使用して認証されます。そのため、他の人がそのURLアドレスを取得しても、Apache Hopインスタンスにアクセスすることはできません。
これで、WebブラウザでApache Hopを使用する準備が整いました!
以前の投稿で示した例をHop Webを使用して複製するか、Hopに含まれているサンプルから他のプロジェクトを起動してみてください。
どこに自分のものを保存すればよいですか?
コンテナのファイルシステムのディレクトリは一時的なものです。パイプラインとJARを永続的な場所に保存していることを確認するにはどうすればよいですか?
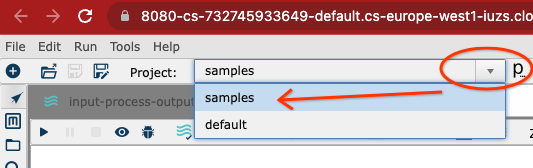
ホームディレクトリコンテナは`/root`であり、コンテナ内で唯一の**永続的な**ディレクトリです(前に作成したディスクのおかげで)。何らかの理由でVMを再起動すると、そのディレクトリに含まれるすべてのファイルは保持されます。しかし、残りのディレクトリは元の状態にリセットされます。そのため、パイプライン、Dataflow用に生成されたfat JARなど、すべてのものを`/root`ディレクトリまたはそのサブディレクトリに保存してください。
Hopファイルダイアログで、ホームアイコンをクリックすると、`/root`ディレクトリに移動するため、すべてを保存するために使用するのは非常に簡単です。写真の例では、**ホーム**ボタンをクリックして、その永続ディレクトリにJARを保存しています。
仮想マシンの電源を切る
仮想マシンを使用していないときに費用を節約したい場合は、VMを停止し、必要に応じて 다시 시작します。 _/root_ディレクトリのコンテンツは、仮想マシンを停止すると保存されます。
VMを停止するには、次のコマンドを実行します(または、コンソールのCompute Engine VMページで、**停止**をクリックします)。
gcloud compute instances stop my-hop-vm --zone=$ZONE
そして再起動するには、次のコマンドを実行します。
gcloud compute instances start my-hop-vm --zone=$ZONE
Hop Webにアクセスするには、Identity Aware Proxyを実行している必要があることに注意してください。そのため、VMの起動後、Identity Aware Proxyを起動するコマンドを実行することを忘れないでください(起動直後に失敗した場合は、数秒待ってから再実行してください)。
gcloud compute start-iap-tunnel my-hop-vm 8080 --local-host-port=localhost:8080 --zone=$ZONE
まとめ
この記事では、Hopを実行するために必要なのはWebブラウザだけであることを示しました。そして、もちろん、Google Cloudプロジェクトも必要です。
コンテナをGoogle Cloudの仮想マシンにデプロイしたので、どこからでもHopにアクセスできます。また、永続ディスクを作成したので、パイプライン用の永続ストレージを用意できます。これで、Webブラウザを使用してパイプラインを作成し、Dataflowジョブを実行できます。コンピュータにローカルで何かをインストールする必要はありません。Javaも、Dockerも、Google Cloud SDKも、何も必要ありません。お気に入りのWebブラウザだけです。
この記事の手順に従った場合は、Google Cloud DataflowでApache Hopビジュアルパイプラインを実行するの記事にアクセスして、Webブラウザから直接Dataflowパイプラインを実行してください!