



ブログ
2023/10/02
Apache Beamを使用したDIY生成AIコンテンツ探索プラットフォーム
Apache Beamを使用したDIY生成AIコンテンツ探索プラットフォーム
ドキュメント、PDF、スプレッドシート、プレゼンテーションなどのデジタル資産には、多くの貴重な情報が含まれていますが、必要な情報を見つけるのが難しい場合があります。このブログ投稿では、ニアリアルタイムのインジェスト処理と大規模言語モデル(LLM)に基づいたDIYスターターアーキテクチャを構築し、資産から有益な情報を抽出する方法について説明します。このモデルは、シンプルな自然言語クエリを通じて情報を提供し、検索可能にします。
コンテンツインジェストのためのニアリアルタイム処理パイプラインの構築は、複雑なタスクのように思えるかもしれませんが、実際そうなる可能性があります。パイプラインの構築を容易にするために、Apache Beamフレームワークは強力な構成要素のセットを提供します。これらの構成要素により、複数タイプのコンテンツソースと宛先とのやり取り、エラー処理、モジュール性などの複雑さを解消します。また、最小限の労力で回復力とスケーラビリティを維持することもできます。Apache Beamストリーミングパイプラインを使用して、次のタスクを実行できます。
- ソリューションの多くのコンポーネントに接続します。
- ドキュメントのコンテンツインジェスト要求を迅速に処理します。
- インジェストから数秒後にドキュメントの情報を利用できるようにします。
LLMは、多くの異なる場所に保存されているコンテンツを抽出し、情報を要約するために頻繁に使用されます。組織はLLMを使用して、長年にわたって作成された複数のドキュメントに公開されている関連情報を迅速に見つけることができます。情報は異なる形式である場合があり、ドキュメントが長すぎて複雑すぎて、迅速に読み理解できない場合があります。LLMを使用してこのコンテンツを処理し、ユーザーが必要な情報を簡単に見つけられるようにします。
このガイドの手順に従って、データ抽出、コンテンツインジェスト、ストレージのためのカスタムスケーラブルソリューションを作成します。Google Cloud製品と生成AIオファリングを使用して、LLMベースのソリューションの開発を迅速に開始する方法を学びます。Google Cloudは使いやすく、スケーラブルで柔軟な設計になっているため、さらなる拡張または実験の出発点として使用できます。
上位レベルのフロー
このワークフローでは、コンテンツの取得とクエリのやり取りは完全に分離されています。外部のコンテンツ所有者は、Googleドキュメントまたはバイナリテキスト形式で保存されているドキュメントを送信し、インジェスト要求の追跡IDを受け取ることができます。インジェストプロセスはドキュメントのコンテンツを取得し、サイズを構成可能なチャンクを作成します。各ドキュメントチャンクを使用して埋め込みを生成します。これらの埋め込みは、768次元のベクトルの形式で、コンテンツのセマンティクスを表します。ドキュメント識別子とチャンク識別子が与えられると、セマンティックマッチングのために埋め込みをベクトルデータベースに保存できます。このプロセスは、ユーザーの問い合わせのコンテキスト化に不可欠です。
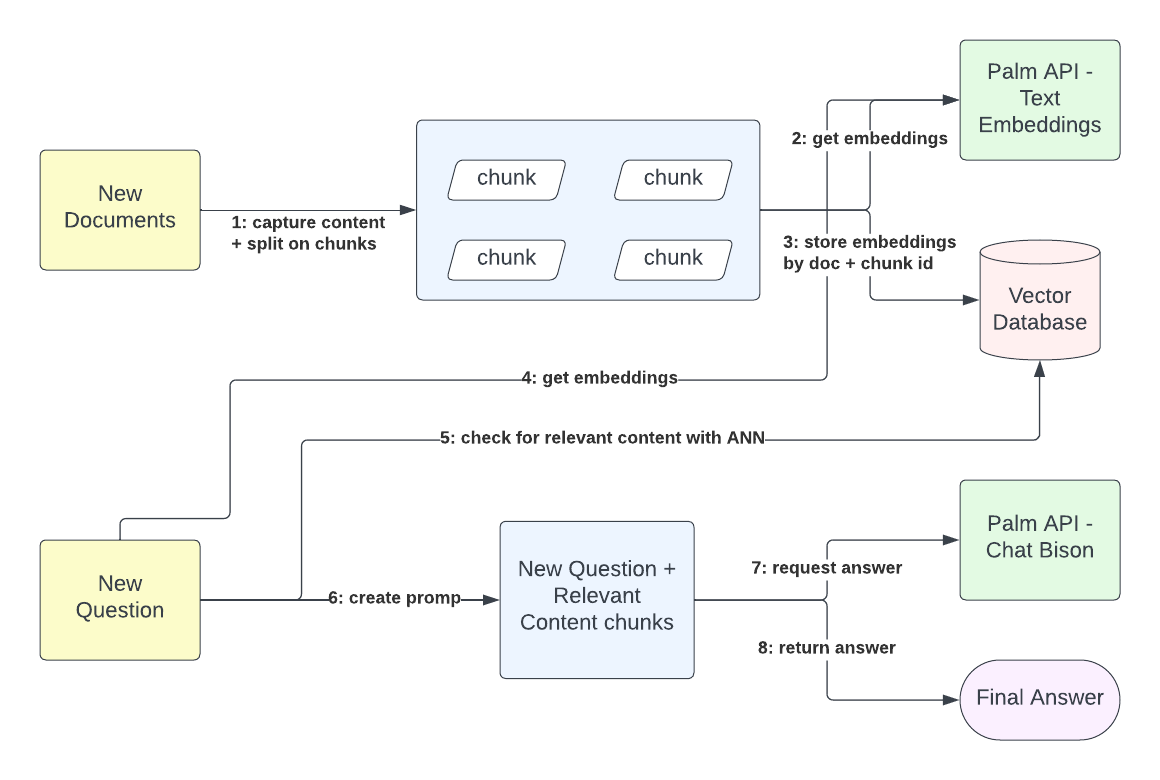
クエリ解決プロセスは、情報インジェストに直接依存しません。ユーザーは、クエリ要求の時点までにインジェストされたコンテンツに基づいて、関連する回答を受け取ります。プラットフォームに関連するコンテンツが保存されていない場合でも、プラットフォームは関連するコンテンツがないことを示す回答を返します。したがって、クエリ解決プロセスはまず、クエリコンテンツと、プラットフォームとの以前のやり取りなど、以前に存在するコンテキストから埋め込みを生成し、これらの埋め込みをコンテンツから保存された既存の埋め込みベクトルと照合します。プラットフォームに一致するものがある場合、コンテンツ埋め込みによって表されるプレーンテキストコンテンツを取得します。最後に、クエリのテキスト表現と一致したコンテンツのテキスト表現を使用して、LLMに要求を行い、元のユーザー問い合わせに対する最終的な回答を提供します。
ソリューションのコンポーネント
Google Cloudサービスのローオプス機能を使用して、一連の高度にスケーラブルな機能を作成します。ソリューションは、サービスレイヤーとコンテンツインジェストパイプラインの2つの主要なコンポーネントに分離できます。サービスレイヤーは、ドキュメントインジェストとユーザークエリのエントリポイントとして機能します。これは、Cloud Runを通じて公開され、Quarkusと他のサービス(Vertex AIモデル、Cloud Bigtable、Pub/Sub)にアクセスするためのクライアントライブラリを使用して実装された、単純なRESTリソースのセットです。コンテンツインジェストパイプラインには、次のコンポーネントが含まれます。
- ユーザーコンテンツを格納場所から取得するストリーミングパイプライン。
- このコンテンツから多次元ベクトル(テキスト埋め込み)のセットとして意味を抽出するプロセス。
- 知識コンテンツとユーザーの問い合わせ間のコンテキストマッチングを簡素化するストレージシステム(ベクトルデータベース)。
- 知識表現を実際のコンテンツにマッピングし、問い合わせの集約されたコンテキストを形成する別のストレージシステム。
- 集約されたコンテキストを理解し、プロンプトエンジニアリングを通じて有益な回答を提供できるモデル。
- HTTPおよびgRPCベースのサービス。
これらのコンポーネントを組み合わせることで、コンテンツ探索プラットフォームのための包括的でシンプルな実装が提供されます。
ワークフローアーキテクチャ
このセクションでは、さまざまなコンポーネントの相互作用方法について説明します。
コンポーネントの依存関係
次の図は、プラットフォームが統合するすべてのコンポーネントと、ソリューションのコンポーネントとGoogle Cloudサービス間のすべての依存関係を示しています。
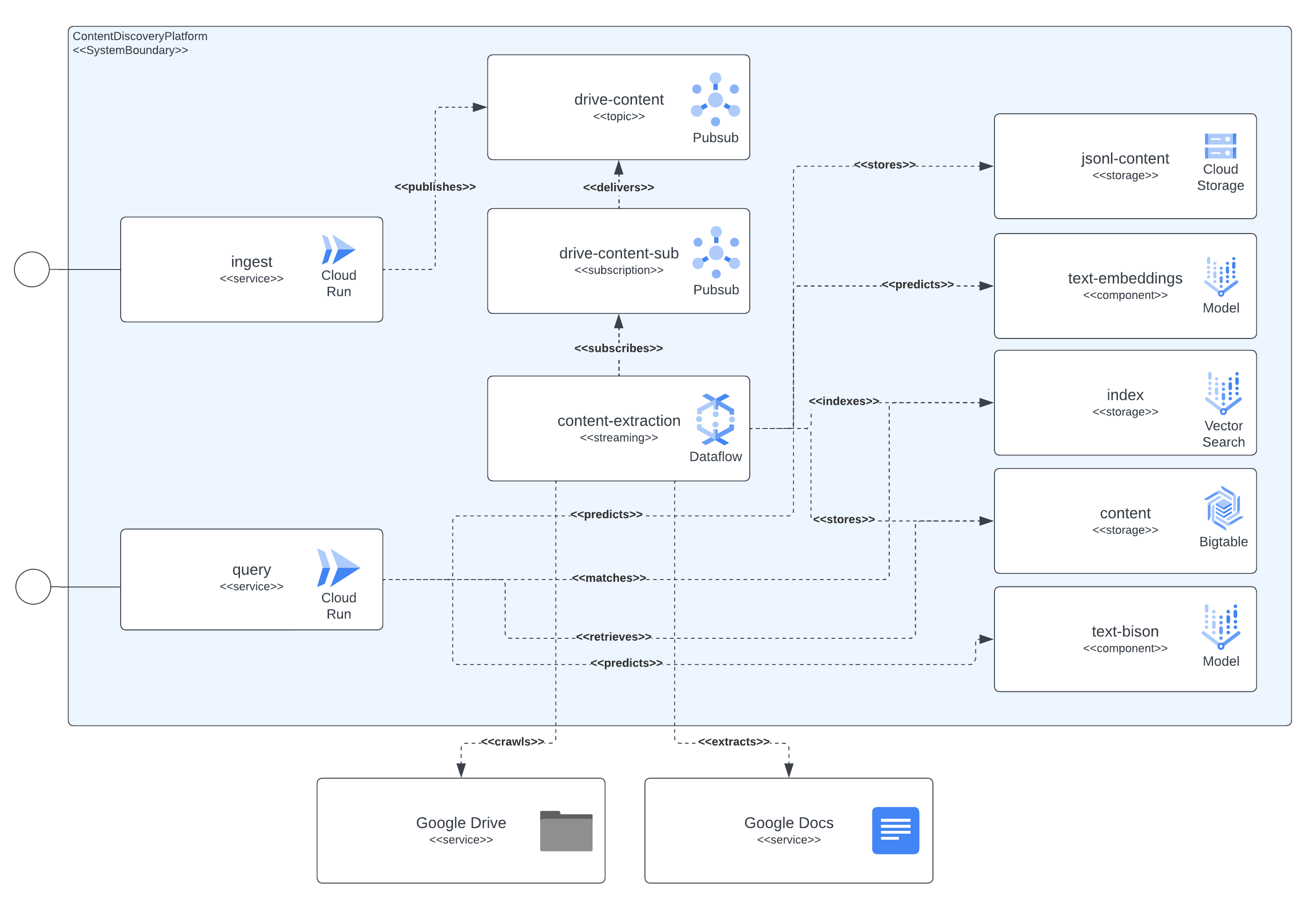
図に示されているように、コンテキスト抽出コンポーネントは、ドキュメントのコンテンツ、埋め込みモデルからのセマンティックな意味、および後で使用する永続ストレージシステムへの関連データ(チャンクテキストコンテンツ、チャンク埋め込み、JSON-Lコンテンツ)の取得を担当する中心的な側面です。Pub/Subリソースは、ストリーミングパイプラインと非同期処理をつなぎ、ユーザーのインジェスト要求、インジェストパイプラインからの潜在的なエラーからの再試行(ドキュメントがインジェストのために送信されたが権限がまだ付与されていない場合など、数分後に再試行がトリガーされる)、およびコンテンツ更新イベント(パイプラインは定期的にインジェストされたドキュメントをスキャンし、最新の版を確認し、コンテンツ更新をトリガーする必要があるかどうかを決定します)をキャプチャします。
コンテキスト抽出コンポーネントは、ドキュメントのコンテンツを取得し、チャンクに分割します。また、抽出されたコンテンツから、LLMのやり取りを使用して埋め込みを計算します。その後、後で使用する永続ストレージシステムに関連データ(チャンクテキストコンテンツ、チャンク埋め込み、JSON-Lコンテンツ)を保存します。Pub/Subリソースは、ストリーミングパイプラインと非同期処理を接続し、次のアクションをキャプチャします。
- ユーザーインジェスト要求
- インジェストパイプラインからのエラーからの再試行(ドキュメントがインジェストのために送信されたがアクセス許可がない場合など)
- コンテンツ更新イベント(パイプラインは定期的にインジェストされたドキュメントをスキャンし、最新の版を確認し、コンテンツ更新をトリガーする必要があるかどうかを決定します)
また、Cloud Runはサービスを公開し、多くのGoogle Cloudサービスとやり取りしてユーザーのクエリまたはインジェスト要求を解決する上で重要な役割を果たします。たとえば、クエリ要求を解決する際に、サービスは次のことを行います。
- 埋め込みモデルとやり取りすることにより、ユーザーのクエリから埋め込みの計算を要求します。
- クエリ埋め込み表現を使用して、Vertex AIベクトル検索(旧Matching Engine)から最近傍の一致を見つけます。
- それらの識別子を使用して、BigTableから一致するベクトルについてテキストコンテンツを取得し、LLMプロンプトのコンテキスト化を行います。
- 最後に、Vertex AI Chat-Bisonモデルに要求を作成し、システムがユーザーのクエリに配信する応答を生成します。
Google Cloud製品
このセクションでは、ソリューションで使用されるGoogle Cloud製品とサービス、およびそれらが果たす役割について説明します。
**Cloud Build:** サービスとパイプラインを含むすべてのコンテナイメージは、Cloud Buildを使用してソースコードから直接ビルドされます。Cloud Buildを使用すると、ソリューションのデプロイ中にコード配布が簡素化されます。
**Cloud Run:** ソリューションのサービスエントリポイントは、Cloud Runによってデプロイされ、自動的にスケーリングされます。
**Pub/Sub:** Pub/Subトピックとサブスクリプションは、Google Driveまたは自己完結型のコンテンツのすべてのインジェスト要求をキューに登録し、要求をパイプラインに配信します。
**Dataflow:** 多言語ストリーミングApache Beamパイプラインは、インジェスト要求を処理します。これらの要求は、Pub/Subサブスクリプションからパイプラインに送信されます。パイプラインは、Googleドキュメント、Google Drive URL、および自己完結型のバイナリエンコードテキストコンテンツからコンテンツを抽出し、コンテンツチャンクを生成します。これらのチャンクは、埋め込み表現のためにVertex AIの基本モデルの1つに送信されます。ドキュメントの埋め込みとチャンクは、インデックス作成と迅速なアクセスのため、Vertex AIベクトル検索とCloud Bigtableに送信されます。最後に、インジェストされたドキュメントは、Vertex AIモデルのファインチューニングに使用できるJSON-L形式でGoogle Cloud Storageに保存されます。Dataflowを使用してApache Beamストリーミングパイプラインを実行することにより、リソースをスケーリングするために必要なオペレーションを最小限に抑えることができます。インジェスト要求がバーストした場合、Dataflowはレイテンシを1分未満に維持できます。
**Vertex AI - ベクトル検索:** ベクトル検索は、高性能で低レイテンシのベクトルデータベースです。これらのベクトルデータベースは、ベクトル類似性検索または近似最近傍(ANN)サービスと呼ばれることがよくあります。インジェストされたすべてのドキュメントの埋め込みを意味表現として格納するために、ベクトル検索インデックスを使用します。これらの埋め込みは、チャンクとドキュメントIDによってインデックス付けされます。その後、これらの識別子を使用してユーザーのクエリにコンテキストを与え、BigTableに保存されているドキュメントのコンテンツマッピングから直接抽出された知識を提供することにより、LLMに行われた要求を強化することができます。
Cloud BigTable: このストレージシステムは、予測可能な規模で識別子による低レイテンシ検索を提供します。リクエスト解決の低レイテンシを考慮すると、ユーザークエリとプラットフォームコンポーネント間のオンライン交換に最適です。ドキュメントから抽出されたコンテンツを、チャンクとドキュメント識別子によってインデックス付けされているため、ここに格納します。ユーザーがクエリサービスにリクエストを送信するたびに、クエリテキストの埋め込みが解決され、既存のコンテキストと一致した後、ドキュメントとチャンクIDを使用して、使用中のLLMへの回答を要求するためのコンテキストとして使用されるドキュメントのコンテンツが取得されます。また、BigTableはユーザーとプラットフォーム間の会話のやり取りを追跡し、LLMに送信されるリクエストに含まれるコンテキスト(埋め込み、要約、チャットQ&A)をさらに充実させます。
Vertex AI - テキスト埋め込みモデル: テキスト埋め込み は、テキストの一部を凝縮したベクトル(数値)表現です。2つのテキストが意味的に類似している場合、対応する埋め込みは埋め込みベクトル空間で互いに近くに配置されます。詳細については、テキスト埋め込みの取得を参照してください。これらの埋め込みは、ドキュメントのコンテンツを処理する際のインジェストパイプラインと、ユーザーのクエリのセマンティクスをベクター検索でインデックス付けされた既存のコンテンツと照合するための入力として、クエリサービスによって直接使用されます。
Vertex AI - テキスト要約モデル: Text-bison は、テキストを理解し、要約し、生成するPaLM 2 LLMの名前です。Text-bisonが作成できるコンテンツの種類には、ドキュメントのサマリー、質問への回答、提供された入力コンテンツを分類するラベルなどがあります。このLLMを使用して、以前に保持された会話を要約し、ユーザーのクエリを充実させ、より良い埋め込みマッチングを実現しました。要約すると、ユーザーは質問のすべてのコンテキストを含める必要がなく、会話履歴から抽出および要約します。
Vertex AI - テキストチャットモデル: Chat-bison は、言語理解、言語生成、会話に優れたPaLM 2 LLMです。このチャットモデルは、自然な複数ターン会話を実施するように微調整されており、送受信を繰り返す必要があるコードに関するテキストタスクに最適です。このLLMを使用して、ソリューションのユーザーが行ったクエリに対する回答を提供し、両当事者間の会話履歴を含め、ソリューションに保存されているコンテンツを使用してモデルのコンテキストを充実させます。
抽出パイプライン
コンテンツ抽出パイプラインは、プラットフォームの中心です。コンテンツインジェストリクエストの処理、ドキュメントコンテンツの抽出、そのコンテンツからの埋め込みの計算を行い、最終的に高速アクセスに使用される特殊なストレージシステムにデータを格納します。
概要
前述のように、パイプラインはApache Beamフレームワークを使用して実装されており、GCPのDataflowサービスでストリーミング方式で実行されます。
Apache BeamとDataflowを使用することで、最小限のレイテンシ(数分未満の処理時間)、低い運用コスト(トラフィックの急増が発生した場合にパイプラインを手動でスケールアップまたはスケールダウンする必要がない、ワーカーのリサイクル、アップデートなど)、および高い可観測性(明確で豊富なパフォーマンスメトリクスが利用可能)を確保できます。
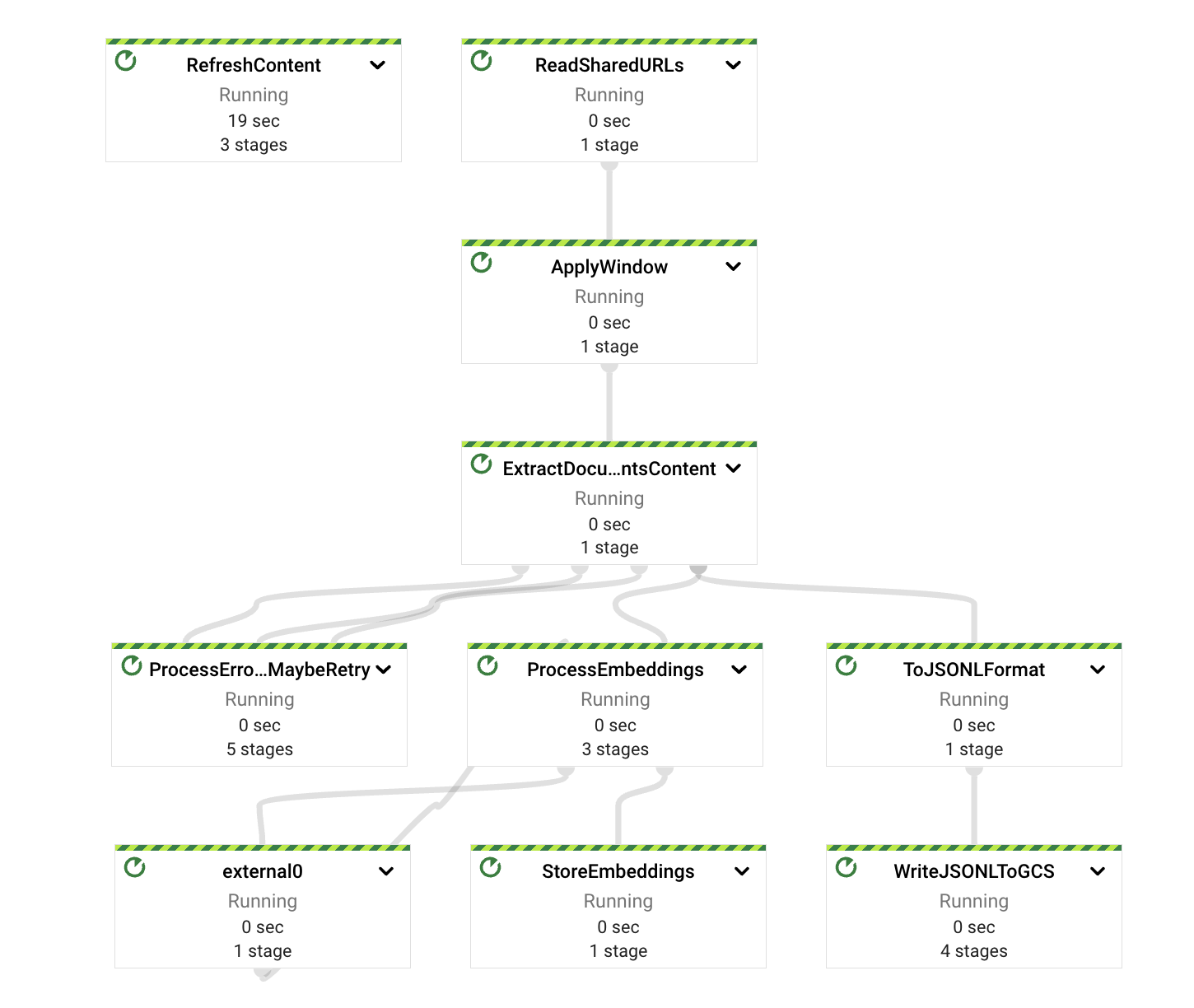
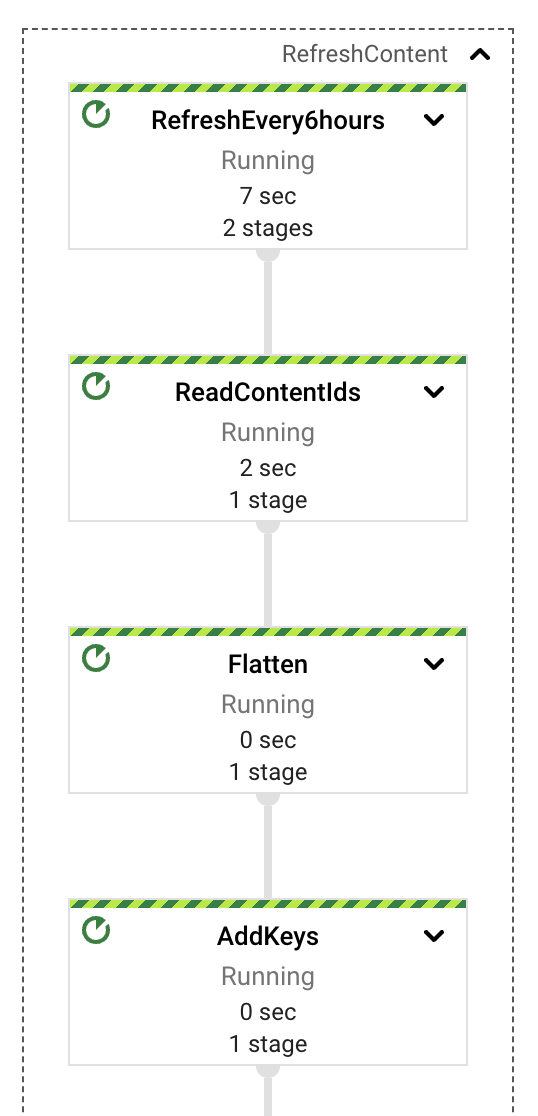
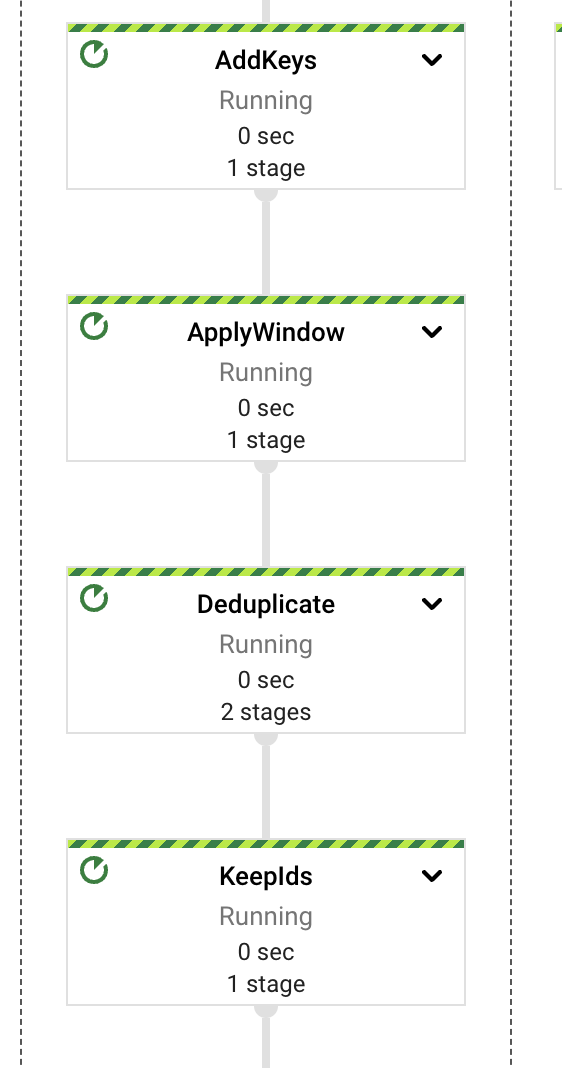
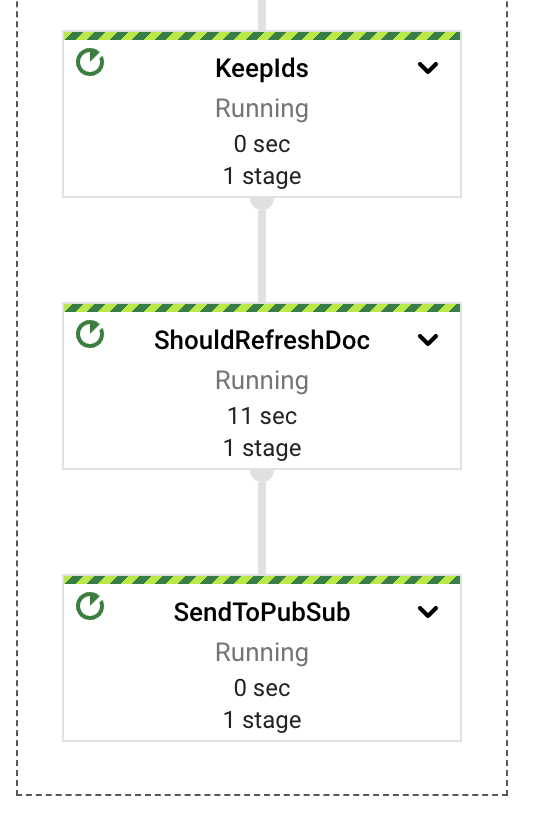
高いレベルでは、パイプラインは抽出、計算、エラー処理、およびストレージの責任を異なるコンポーネントまたはPTransformに分割します。図に示すように、メッセージはPubSubサブスクリプションから読み取られ、コンテンツ抽出の前にウィンドウ定義にすぐに含まれます。
これらの各PTransformは、実装の基礎となる段階に関する詳細を明らかにするために展開できます。次のセクションでそれぞれについて詳しく説明します。
パイプラインは多言語アプローチを使用して実装されており、主要なコンポーネントはJava言語(JDKバージョン17)で記述され、埋め込み計算に関連するコンポーネントは、Vertex AI APIクライアントがこの言語で使用できるため、Python(バージョン3.11)で実装されています。
コンテンツ抽出
コンテンツ抽出コンポーネントは、インジェストリクエストのペイロードを確認し、イベントのプロパティに基づいて、イベント自体からコンテンツを取得する必要があるか(自己完結型コンテンツ、テキストベースのドキュメントバイナリエンコード)、Googleドライブから取得する必要があるかを判断します。
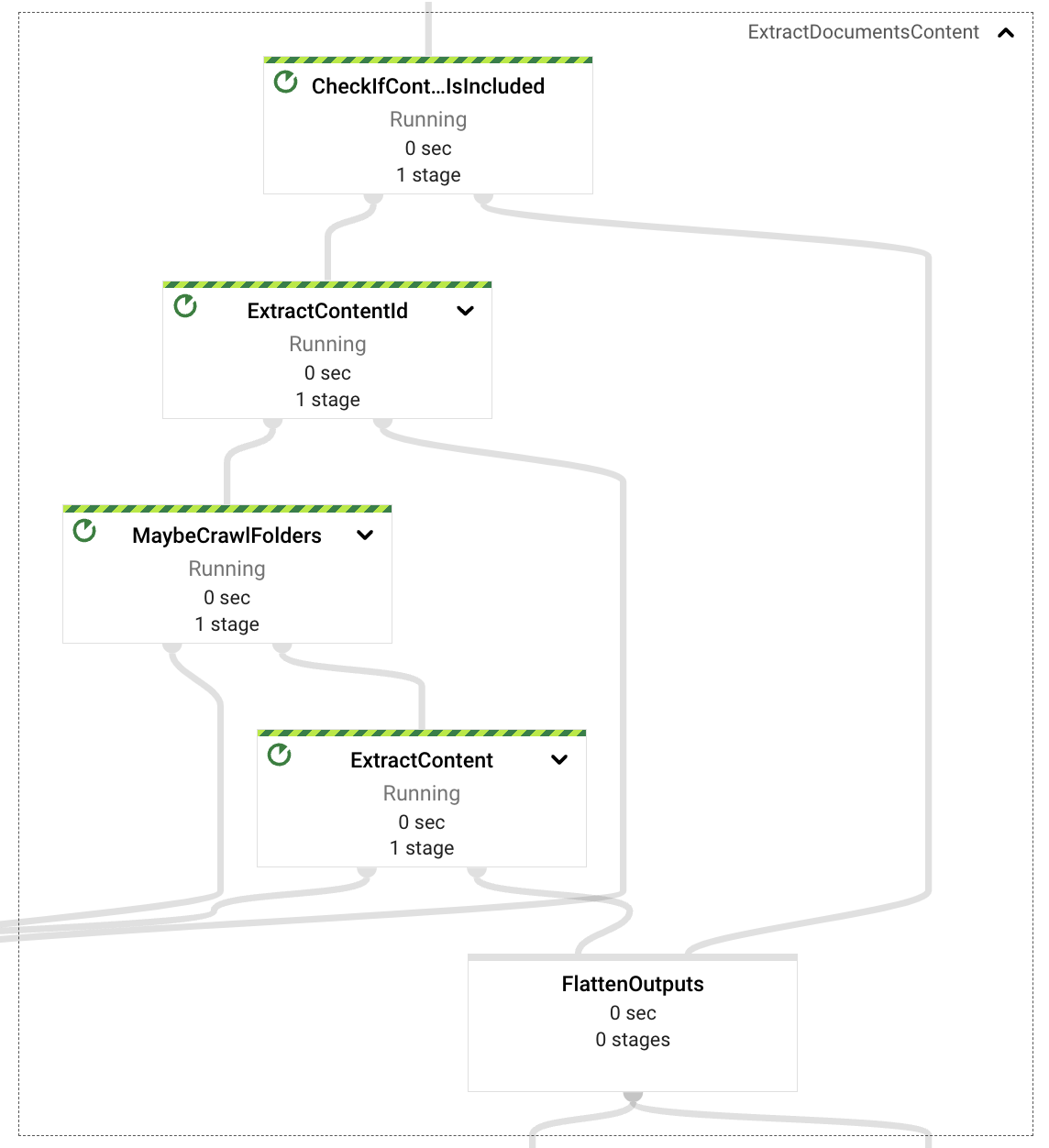
自己完結型のドキュメントの場合、パイプラインはドキュメントIDを抽出し、後の埋め込み処理のためにドキュメントを段落形式でフォーマットします。
Googleドライブからの取得が必要な場合、パイプラインは、イベントに提供されたURLがGoogleドライブのフォルダを参照しているか、単一のファイル形式(サポートされている形式はドキュメント、スプレッドシート、プレゼンテーション)を参照しているかを検査します。フォルダの場合、パイプラインはフォルダのコンテンツを再帰的にクロールし、サポートされている形式のすべてのファイルを抽出します。単一のドキュメントの場合は、その1つだけを返します。
最後に、インジェストリクエストから取得されたすべてのファイル参照を使用して、ファイルからテキストコンテンツが抽出されます(このPoCでは画像サポートは実装されていません)。そのコンテンツは、ドキュメントの識別子と段落としてのコンテンツを含む、埋め込み処理段階にも渡されます。
エラー処理
コンテンツ抽出プロセスのすべての段階で、複数のエラーが発生する可能性があります。不正なインジェストリクエスト、非準拠のURL、ドライブリソースへの権限の不足、ファイルデータ取得への権限の不足などです。
これらのすべての場合、専用のコンポーネントがこれらの潜在的なエラーをキャプチャし、エラーの性質に基づいて、イベントを再試行する必要があるか、後から検査するためにデッドレターGCSバケットに送信する必要があるかを決定します。
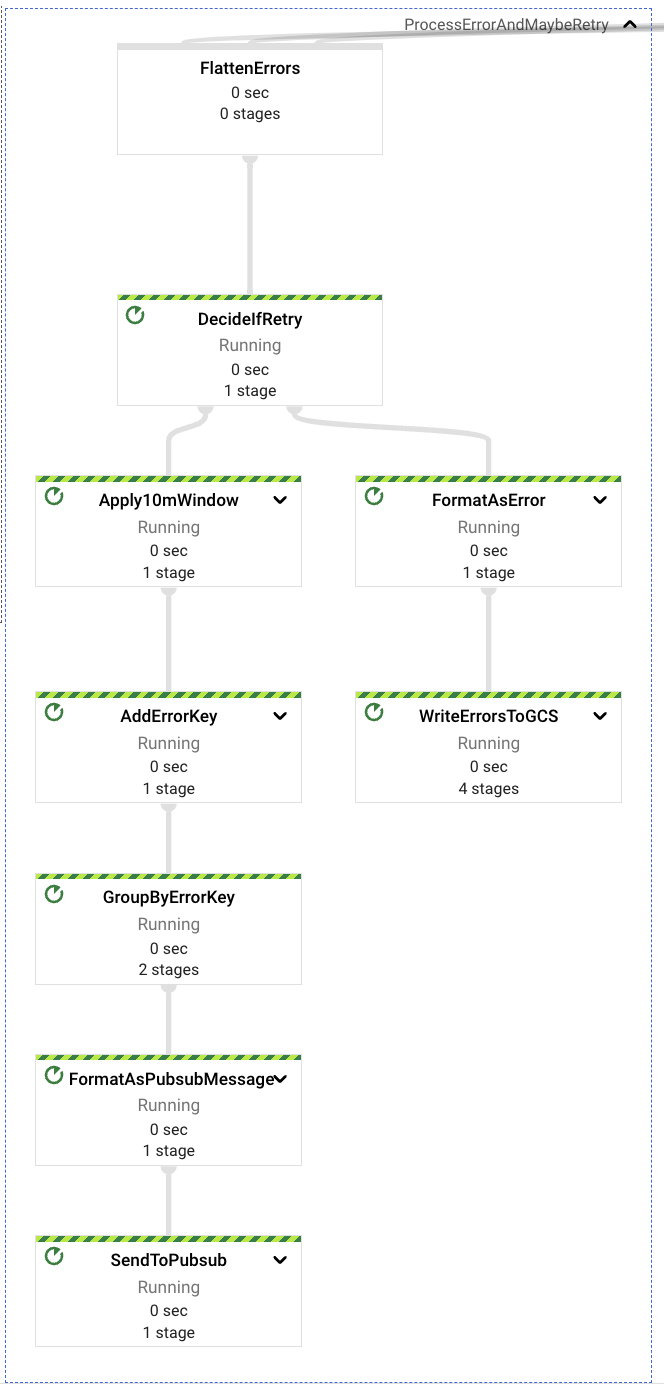
最終的なエラー、または再試行されないエラーは、不正なリクエスト形式(イベント自体またはプロパティのコンテンツ、不正なURLなど)に関連するエラーです。
再試行可能なエラーは、コンテンツアクセスと権限の不足に関連するエラーです。リクエストは、パイプラインを実行するサービスアカウントがインジェストリクエストに含まれるリソース(Googleドライブのフォルダまたはファイル)にアクセスするための適切な権限を提供する手動プロセスよりも速く解決された可能性があります。再試行可能なエラーを検出した場合、パイプラインは10分間再試行を保持してから、メッセージを上流のPubSubトピックに再送信します。各エラーは、デッドレターGCSバケットに送信される前に、最大5回再試行されます。
デッドレターの宛先に到達したイベントのすべてのケースでは、検査と再処理を手動プロセスで行う必要があります。
埋め込み処理
コンテンツがリクエストから抽出されたか、Googleドライブファイルからキャプチャされたら、パイプラインは埋め込み計算プロセスをトリガーします。前述のように、Vertex AI基礎モデルAPIとのインタラクションはPython言語で実装されています。このため、Pythonの世界に直接変換できるJava型で抽出されたコンテンツをフォーマットする必要があります。これらはキーバリュー(Pythonでは2要素のタプル)、文字列(両方の言語で使用可能)、反復可能オブジェクト(両方の言語で使用可能)です。カスタム転送タイプをサポートするために、両方の言語でコーダーを実装することもできましたが、明確さとシンプルさを優先して、それを行いませんでした。
コンテンツの埋め込みを計算する前に、reshuffleステップを導入して、下流の段階への出力を一貫性のあるものにし、エラーが発生した場合にコンテンツ抽出ステップが繰り返されないようにすることを決定しました。これにより、Googleドライブ関連APIの既存のアクセスクォータへの負担を避けることができます。
その後、パイプラインはコンテンツを構成可能なサイズとオーバーラップでチャンク化します。汎用的な効果的なデータ抽出には適切なパラメーターを見つけるのが難しいため、ドキュメントの結果の多様性を優先するために、小さなオーバーラップ係数を持つ小さなチャンクをデフォルト設定として使用することにしました(少なくとも、得られた経験的結果からそう見えます)。
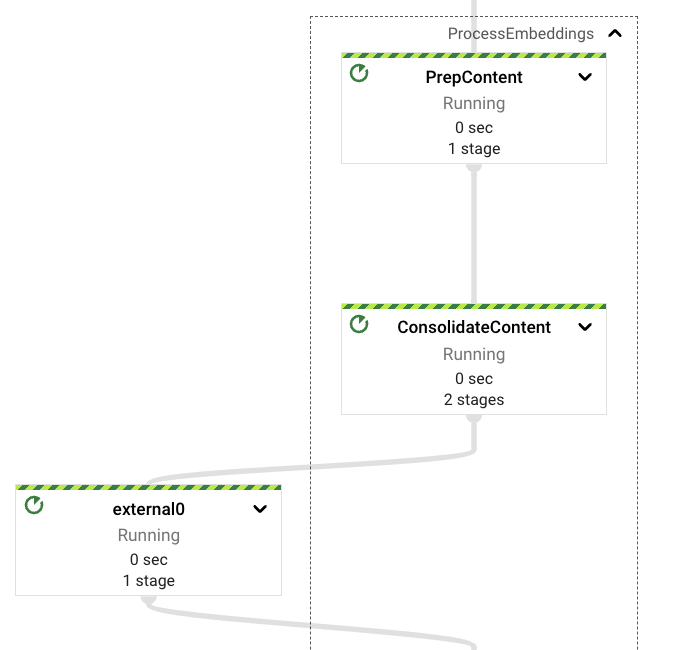
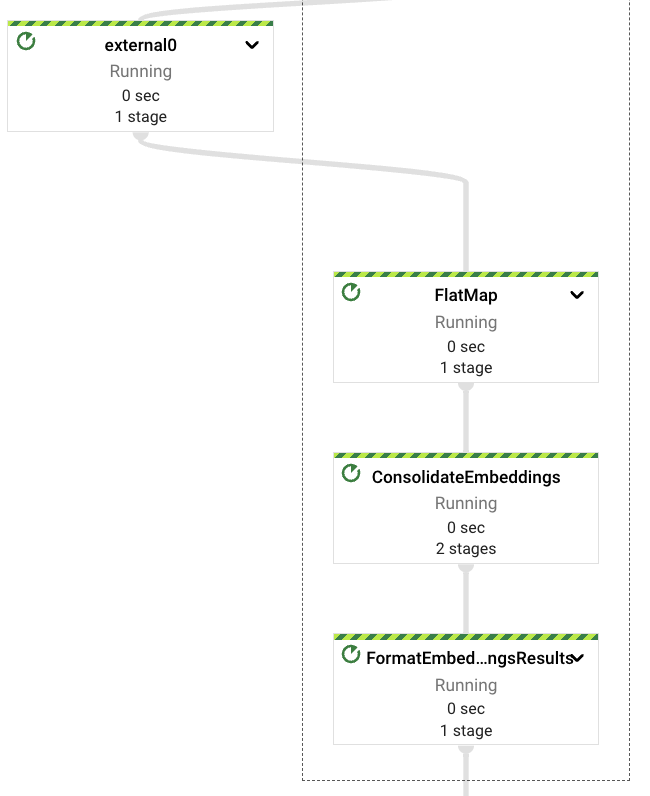
埋め込みベクトルが埋め込みVertex AI LLMから取得されたら、下流のエラーが発生した場合にこのステップが繰り返されないように、それらを再度統合します。
このパイプラインは、クライアントSDKを使用してVertex AIモデルと直接やり取りしていることに注意してください。Apache Beamは、RunInference PTransformを通じてこのインタラクションを既にサポートしています(例についてはこちらを参照)。
コンテンツストレージ
インジェストされたドキュメントから抽出されたコンテンツチャンクの埋め込みが計算されたら、ベクトルを検索可能なストレージに格納し、これらの埋め込みに関連するテキストコンテンツも格納する必要があります。クエリサービスから後でセマンティックマッチとして埋め込みベクトルを使用し、LLMコンテキストとしてこれらの埋め込みに対応するテキストコンテンツを使用して、応答の期待値を改善およびガイドします。
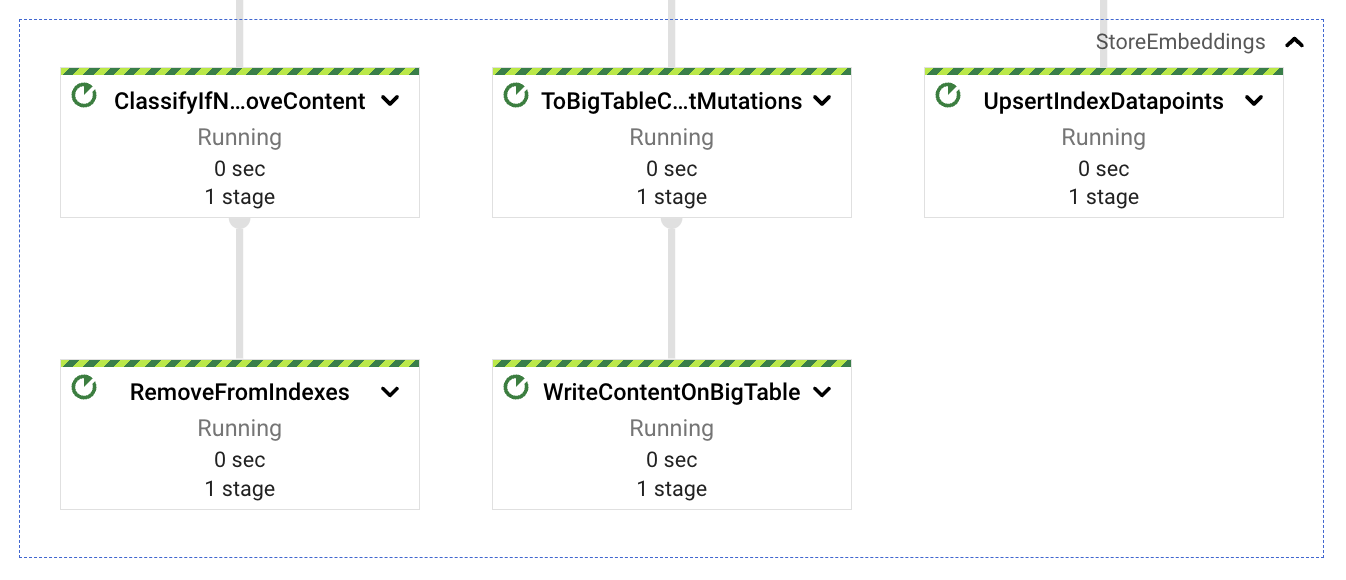
それを念頭に置いて、統合された埋め込みを3つのパスに分割します。1つはベクトルをVertex AIベクター検索に格納するパス(単純なREST呼び出しを使用)、もう1つはテキストコンテンツをBigTableに格納するパス(セマンティックマッチング後の低レイテンシ取得用)、最後の1つはコンテンツの更新または再インジェストの潜在的なクリーンアップとして機能するパスです(後述)。3つのパスは、インジェストされたドキュメント識別子をアクションの関連データとして使用しています。このキーは、ドキュメント名(利用可能な場合)、ドキュメント識別子、チャンクシーケンス番号で構成されます。チャンクに識別子を使用する理由は、後続の更新にあります。コンテンツの増加により、より多くのチャンクが生成され、すべてのチャンクをアップサートすることで、常に新しいデータが使用できるようになります。逆に、コンテンツの減少により、ドキュメントのコンテンツのチャンク数が少なくなり、この数の違いを使用して、残りの孤立したインデックス付きチャンク(最新のドキュメントバージョンに存在しなくなったコンテンツからのもの)を削除できます。
コンテンツ更新
最後のパイプラインコンポーネントは、少なくとも概念的には最もシンプルです。Googleドライブのドキュメントがインジェストされた後、外部ユーザーがそれらに更新を行う可能性があり、インデックス付けされたコンテンツが古くなります。同じストリーミングパイプライン内で、既にインジェストされたドキュメントのレビューを行い、必要なコンテンツ更新があるかどうかを確認する単純な定期プロセスを実装しました。GenerateSequence変換を使用して定期的なインパルス(デフォルトでは6時間ごと)を生成し、BigTableをスキャンしてインジェストされたすべてのドキュメント識別子を取得します。これらの識別子を使用して、各ドキュメントの最新の更新タイムスタンプをGoogleドライブでクエリし、そのマーカーを使用して更新が必要かどうかを決定できます。
ドキュメントのコンテンツを更新する必要がある場合、上流のPubSubトピックにインジェストリクエストを送信し、この新しいイベントに対してパイプラインを実行させることができます。埋め込みのアップサートと存在しなくなった埋め込みのクリーンアップを処理しているため、追加のほとんどを処理できるはずです(テキスト更新の場合、現時点では画像ベースのコンテンツは処理されていません)。
このタスクは、別個のジョブ、おそらくバッチ形式で定期的にスケジュールされるジョブとして実行できます。これにより、コストの削減、独立したエラー領域、より予測可能な自動スケーリング動作が実現します。ただし、このデモの目的では、単一のジョブの方が簡単です。
次に、このソリューションがデータ取り込みとコンテンツ探索のユースケースにおいて、外部クライアントとどのように連携するかについて説明します。
インタラクションデザイン
このソリューションは、プラットフォームへのデータ取り込みとクエリ操作をできるだけシンプルにすることを目指しています。また、データ取り込み部分では複数のサービスとの連携、リトライ、コンテンツの更新が必要となる可能性があるため、非同期で分離することにしました。これにより、外部ユーザーはリクエストの解決を待つ間、ブロックされることなく作業を続けられます。
インタラクションの例
プラットフォームがGCPプロジェクトにデプロイされた後、サービスとやり取りする簡単な方法は、Webクライアントを使用することです。curlが良い例です。また、エンドポイントは認証されているため、クライアントはアクセス許可を得るためにリクエストヘッダーに資格情報を含める必要があります。
コンテンツ取り込みのインタラクション例を以下に示します。
$ > curl -X POST -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-identity-token)" https://<service-address>/ingest/content/gdrive -d $'{"url":"https://drive.google.com/drive/folders/somefolderid"}' | jq .
# response from service
{
"status": "Ingestion trace id: <some identifier>"
}
この場合、取り込みリクエストが処理のためにPub/Subトピックに送信された後、サービスはトラッキング識別子を返します。これはPub/Subメッセージ識別子に対応しています。提供されたURLは、GoogleドキュメントまたはGoogleドライブフォルダーのいずれかになります。後者の場合、取り込みプロセスはフォルダーの内容を再帰的にクロールして、含まれるすべてのドキュメントとその内容を取得します。
次に、前の例と非常によく似たコンテンツクエリインタラクションの例を示します。
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications", "sessionId": ""}' \
| jq .
# response from service
{
"content": "VertexAI Foundation Models are a set of pre-trained models that can be used to accelerate the development of machine learning applications. They are available for a variety of tasks, including natural language processing, computer vision, and recommendation systems.\n\nVertexAI Foundation Models can be used to improve the performance of Generative AI applications by providing a starting point for model development. They can also be used to reduce the amount of time and effort required to train a model.\n\nIn addition, VertexAI Foundation Models can be used to improve the accuracy and robustness of Generative AI applications. This is because they are trained on large datasets and are subject to rigorous quality control.\n\nOverall, VertexAI Foundation Models can be a valuable resource for developers who are building Generative AI applications. They can help to accelerate the development process, reduce the cost of development, and improve the performance and accuracy of applications.",
"previousConversationSummary": "",
"sourceLinks": [
{
"link": "<possibly some ingested doc url/id>",
"distance": 0.7233397960662842
}
],
"citationMetadata": [
{
"citations": []
}
],
"safetyAttributes": [
{
"categories": [],
"scores": [],
"blocked": false
}
]
}
プラットフォームは、LLMからのテキスト応答でリクエストに応答し、応答の生成に使用されたコンテンツの分類、引用メタデータ、ソースリンク(利用可能な場合)に関する情報も含まれます(これは、プラットフォームによって以前に取り込まれたドキュメントのGoogleドキュメントリンクなどです)。
サービスとやり取りする場合、適切なクエリは一般的に良い結果を返します。クエリが明確であればあるほど、その意味を理解しやすくなり、より正確な情報がLLMに送信されて回答が取得されます。しかし、サービスとのやり取りのたびに、クエリのコンテキストのすべての詳細をフレーズに含める必要があるのは非常に面倒で困難です。そのため、プラットフォームは、ユーザーとプラットフォーム間の以前のやり取りをすべて保存するために使用されるセッション識別子を使用できます。これは、初期クエリの埋め込みのマッチングをより適切にコンテキスト化し、モデルリクエストにより簡潔なコンテキスト情報を提供するのに役立ちます。コンテキスト付きのやり取りの例を以下に示します。
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"summarize the benefits of using VertexAI foundational models for Generative AI applications?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "VertexAI Foundational Models are a suite of pre-trained models that can be used to accelerate the development of Generative AI applications. These models are available in a variety of languages and domains, and they can be used to generate text, images, audio, and other types of content.\n\nUsing VertexAI Foundational Models can help you to:\n\n* Reduce the time and effort required to develop Generative AI applications\n* Improve the accuracy and quality of your models\n* Access the latest research and development in Generative AI\n\nVertexAI Foundational Models are a powerful tool for developers who want to create innovative and engaging Generative AI applications.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"describe the available LLM models?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models suite includes a variety of LLM models, including:\n\n* Text-to-text LLMs: These models can generate text based on a given prompt. They can be used for tasks such as summarization, translation, and question answering.\n* Image-to-text LLMs: These models can generate text based on an image. They can be used for tasks such as image captioning and description generation.\n* Audio-to-text LLMs: These models can generate text based on an audio clip. They can be used for tasks such as speech recognition and transcription.\n\nThese models are available in a variety of languages, including English, Spanish, French, German, and Japanese. They can be used to create a wide range of Generative AI applications, such as chatbots, customer service applications, and creative writing tools.",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"do rate limit apply for those LLMs?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "Yes, there are rate limits for the VertexAI Foundational Models. The rate limits are based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models documentation](https://cloud.google.com/vertex-ai/docs/foundational-models#rate-limits).",
…
}
$ > curl -X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $(gcloud auth print-identity-token)" \
https://<service-address>/query/content \
-d $'{"text":"care to share the price?", "sessionId": "some-session-id"}' \
| jq .
# response from service
{
"content": "The VertexAI Foundational Models are priced based on the number of requests per second and the total number of requests per day. For more information, please see the [VertexAI Foundational Models pricing page](https://cloud.google.com/vertex-ai/pricing#foundational-models).",
…
}
使用方法のヒント:話題が突然変わる場合は、新しいセッション識別子を使用する方が良い場合があります。
デプロイ
プラットフォームソリューションの一部として、さまざまなコンポーネントのデプロイを支援する一連のスクリプトがあります。`start.sh`を実行し、適切なパラメーター(GCPプロジェクト、Terraformステートバケット、プラットフォームインスタンスの名前)を設定すると、スクリプトはコードのビルド、必要なコンテナ(サービスエンドポイントコンテナとDataflow Pythonカスタムコンテナ)のデプロイ、Terraformを使用したすべてのGCPリソースのデプロイ、そして最後にパイプラインのデプロイを行います。スタートアップスクリプトに追加のパラメーターを渡すことで、パイプラインの実行を変更することもできます。たとえば、`start.sh
また、特定のコンポーネントのデプロイにのみ集中したい場合は、それらの特定のタスクを支援する他のスクリプトが含まれています(ソリューションのビルド、インフラストラクチャのデプロイ、パイプラインのデプロイ、サービスのデプロイなど)。
ソリューションに関する注意事項
このソリューションは、学習目的の例として設計されています。抽出パイプラインの多くの構成値とセキュリティ制限は、例としてのみ提供されています。このソリューションは、取り込まれたコンテンツの既存のアクセス制御リスト(ACL)を伝播しません。その結果、サービスエンドポイントにアクセスできるすべてのユーザーは、元のドキュメントからの取り込まれたコンテンツのサマリーにアクセスできます。
ソースコードに関する注意事項
コンテンツ探索プラットフォームのソースコードは、Githubで入手できます。これは、任意のGoogle Cloudプロジェクトで実行できます。リポジトリには、統合サービス、多言語対応の取り込みパイプライン、Terraformによるデプロイ自動化のソースコードが含まれています。この例をデプロイする場合は、必要なすべてのリソースの作成と構成に最大90分かかります。READMEファイルには、デプロイの前提条件とRESTインタラクションの例に関する追加のドキュメントが含まれています。