



ブログ
2024/06/20
Flinkランナーを使用してKubernetesにPythonパイプラインをデプロイする
Flinkランナーを使用してKubernetesにPythonパイプラインをデプロイする
Apache Flink Kubernetes Operatorは、Apache Flinkアプリケーションのデプロイメントライフサイクル全体を管理するコントロールプレーンとして機能します。このオペレーターを使用すると、Apache Beamパイプラインのデプロイと管理を簡素化できます。
この記事では、Apache BeamパイプラインをPython SDKを使用して開発し、Apache Flinkランナーを使用してApache Flinkクラスタにデプロイします。最初に、パイプラインがデータソースとシンクにKafkaトピックを使用するため、minikubeクラスタにApache Kafkaクラスタをデプロイします。次に、パイプラインをPythonパッケージとして開発し、そのパッケージをカスタムDockerイメージに追加して、Pythonユーザーコードを外部で実行できるようにします。デプロイのために、Flink Kubernetes Operatorを使用してFlinkセッションクラスタを作成し、Kubernetesジョブを使用してパイプラインをデプロイします。最後に、Pythonプロデューサーアプリケーションを使用して入力Kafkaトピックにメッセージを送信することにより、アプリケーションの出力を確認します。
Python BeamパイプラインをFlinkで実行するためのリソース
Apache BeamパイプラインをPython SDKを使用して開発し、Apache Flinkランナーを使用してApache Flinkクラスタにデプロイします。FlinkクラスタはFlink Kubernetes Operatorによって作成されますが、パイプラインを*Flinkランナー*で実行するには、**ジョブサービス**と**SDKハーネス**の2つのコンポーネントが必要です。大まかに言うと、ジョブサービスはPythonパイプラインに関する詳細をFlinkランナーが理解できる形式に変換します。SDKハーネスはPythonユーザーコードを実行します。Python SDKは、これらのコンポーネントを管理するための便利なラッパーを提供しており、たとえば、 `--runner = FlinkRunner`のようにパイプラインオプションで*FlinkRunner*を指定することで使用できます。 *ジョブサービス*は自動的に管理されます。簡単にするために、独自の*SDKハーネス*をサイドカーコンテナとして使用します。また、パイプラインはデータソースとシンクにApache Kafkaトピックを使用し、Kafka Connector I / OはJavaで開発されているため、**Java IO Expansion Service**も必要です。簡単に言うと、拡張サービスはJava SDKのデータをシリアライズするために使用されます。
Kafkaクラスタのセットアップ
Apache Kafkaクラスタは、minikubeクラスタ上のStrimzi Operatorを使用してデプロイされます。Strimziバージョン0.39.0とKubernetesバージョン1.25.3をインストールします。minikube CLIとDockerがインストールされたら、Kubernetesバージョンを指定することでminikubeクラスタを作成できます。この記事のソースコードは、GitHubリポジトリにあります。
minikube start --cpus='max' --memory=20480 \
--addons=metrics-server --kubernetes-version=v1.25.3Strimziオペレーターのデプロイ
GitHubリポジトリには、Strimziオペレーター、Kafkaクラスタ、およびKafka管理アプリケーションをデプロイするために使用できるマニフェストファイルが保持されています。異なるバージョンのオペレーターをダウンロードするには、バージョンを指定して関連するマニフェストファイルをダウンロードします。デフォルトでは、マニフェストファイルはリソースが *myproject*名前空間にデプロイされると想定しています。ただし、*default*名前空間にデプロイするため、リソースの名前空間を変更する必要があります。sedを使用してリソースの名前空間を変更します。
オペレーターをデプロイするには、 `kubectl create`コマンドを使用します。
## Download and deploy the Strimzi operator.
STRIMZI_VERSION="0.39.0"
## Optional: If downloading a different version, include this step.
DOWNLOAD_URL=https://github.com/strimzi/strimzi-kafka-operator/releases/download/$STRIMZI_VERSION/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
curl -L -o kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml \
${DOWNLOAD_URL}
# Update the namespace from myproject to default.
sed -i 's/namespace: .*/namespace: default/' kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Deploy the Strimzi cluster operator.
kubectl create -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yamlStrimzi OperatorがKubernetes デプロイメントとして実行されていることを確認します。
kubectl get deploy,rs,po
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/strimzi-cluster-operator 1/1 1 1 2m50s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/strimzi-cluster-operator-8d6d4795c 1 1 1 2m50s
# NAME READY STATUS RESTARTS AGE
# pod/strimzi-cluster-operator-8d6d4795c-94t8c 1/1 Running 0 2m49sKafkaクラスタのデプロイ
単一のブローカーとZookeeperノードを持つKafkaクラスタをデプロイします。ポート9092と29092にそれぞれ内部リスナーと外部リスナーがあります。外部リスナーは、minikubeクラスタの外部からKafkaクラスタにアクセスするために使用されます。また、クラスタはトピックの自動作成を許可するように構成されており( `auto.create.topics.enable:"true"`)、デフォルトのパーティション数は3に設定されています( `num.partitions:3`)。
# kafka/manifests/kafka-cluster.yaml
apiVersion: kafka.strimzi.io/v1beta2
kind: Kafka
metadata:
name: demo-cluster
spec:
kafka:
version: 3.5.2
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
listeners:
- name: plain
port: 9092
type: internal
tls: false
- name: external
port: 29092
type: nodeport
tls: false
storage:
type: jbod
volumes:
- id: 0
type: persistent-claim
size: 20Gi
deleteClaim: true
config:
offsets.topic.replication.factor: 1
transaction.state.log.replication.factor: 1
transaction.state.log.min.isr: 1
default.replication.factor: 1
min.insync.replicas: 1
inter.broker.protocol.version: "3.5"
auto.create.topics.enable: "true"
num.partitions: 3
zookeeper:
replicas: 1
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
storage:
type: persistent-claim
size: 10Gi
deleteClaim: true
`kubectl create`コマンドを使用してKafkaクラスタをデプロイします。
kubectl create -f kafka/manifests/kafka-cluster.yamlKafkaノードとZookeeperノードは、 *StrimziPodSet*カスタムリソースによって管理されます。また、複数のKubernetes サービスも作成します。このシリーズでは、次のサービスを使用します
- Kubernetesクラスタ内での通信
- `demo-cluster-kafka-bootstrap`-クライアントと管理アプリからKafkaブローカーにアクセスするため
- `demo-cluster-zookeeper-client`-管理アプリからZookeeperノードにアクセスするため
- ホストからの通信
- `demo-cluster-kafka-external-bootstrap`-プロデューサーアプリからKafkaブローカーにアクセスするため
kubectl get po,strimzipodsets.core.strimzi.io,svc -l app.kubernetes.io/instance=demo-cluster
# NAME READY STATUS RESTARTS AGE
# pod/demo-cluster-kafka-0 1/1 Running 0 115s
# pod/demo-cluster-zookeeper-0 1/1 Running 0 2m20s
# NAME PODS READY PODS CURRENT PODS AGE
# strimzipodset.core.strimzi.io/demo-cluster-kafka 1 1 1 115s
# strimzipodset.core.strimzi.io/demo-cluster-zookeeper 1 1 1 2m20s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/demo-cluster-kafka-bootstrap ClusterIP 10.101.175.64 <none> 9091/TCP,9092/TCP 115s
# service/demo-cluster-kafka-brokers ClusterIP None <none> 9090/TCP,9091/TCP,8443/TCP,9092/TCP 115s
# service/demo-cluster-kafka-external-0 NodePort 10.106.155.20 <none> 29092:32475/TCP 115s
# service/demo-cluster-kafka-external-bootstrap NodePort 10.111.244.128 <none> 29092:32674/TCP 115s
# service/demo-cluster-zookeeper-client ClusterIP 10.100.215.29 <none> 2181/TCP 2m20s
# service/demo-cluster-zookeeper-nodes ClusterIP None <none> 2181/TCP,2888/TCP,3888/TCP 2m20sKafka UIのデプロイ
UI for Apache Kafka( `kafka-ui`)は、無料のオープンソースKafka管理アプリケーションです。Kubernetesデプロイメントとしてデプロイされます。デプロイメントは単一のインスタンスを持つように構成され、Kafkaクラスタのアクセス詳細は環境変数として指定されます。
# kafka/manifests/kafka-ui.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
selector:
app: kafka-ui
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: kafka-ui
name: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
containers:
- image: provectuslabs/kafka-ui:v0.7.1
name: kafka-ui-container
ports:
- containerPort: 8080
env:
- name: KAFKA_CLUSTERS_0_NAME
value: demo-cluster
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: demo-cluster-kafka-bootstrap:9092
- name: KAFKA_CLUSTERS_0_ZOOKEEPER
value: demo-cluster-zookeeper-client:2181
resources:
requests:
memory: 256Mi
cpu: 250m
limits:
memory: 512Mi
cpu: 500m
`kubectl create`コマンドを使用して、Kafka管理アプリケーション( `kafka-ui`)をデプロイします。
kubectl create -f kafka/manifests/kafka-ui.yaml
kubectl get all -l app=kafka-ui
# NAME READY STATUS RESTARTS AGE
# pod/kafka-ui-65dbbc98dc-zl5gv 1/1 Running 0 35s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/kafka-ui ClusterIP 10.109.14.33 <none> 8080/TCP 36s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/kafka-ui 1/1 1 1 35s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/kafka-ui-65dbbc98dc 1 1 1 35s`kubectl port-forward`を使用して、ポート8080でminikubeクラスタで実行されている `kafka-ui`サーバーに接続します。
kubectl port-forward svc/kafka-ui 8080
ストリーム処理アプリケーションの開発
Apache BeamパイプラインをPythonパッケージとして開発し、カスタムDockerイメージに追加します。これは、Pythonユーザーコード(*SDKハーネス*)を実行するために使用されます。また、Apache BeamのJava SDKを公式のFlinkベースイメージに追加する別のカスタムDockerイメージも構築します。このイメージは、Flinkクラスタをデプロイし、*Kafka Connector I / O*のJavaユーザーコードを実行するために使用されます。
Beamパイプラインコード
アプリケーションは最初に、入力Kafkaトピックからテキストメッセージを読み取ります。次に、メッセージを分割することにより単語を抽出します( `ReadWordsFromKafka`)。次に、要素(単語)が5秒の固定時間ウィンドウに追加され、平均の長さが計算されます( `CalculateAvgWordLen`)。最後に、ウィンドウの開始と終了のタイムスタンプを含め、更新された要素を出力Kafkaトピックに送信します( `WriteWordLenToKafka`)。
カスタム* Java IO Expansion Service *( `get_expansion_service`)を作成し、Kafka Connector I / Oの `ReadFromKafka`および `WriteToKafka`変換に追加します。Kafka I / Oは、そのサービスを作成するための関数を備えていますが、私には機能しませんでした(または、まだその使用方法を理解していません)。代わりに、JanLukavskýによるApache Beamを使用したビッグデータパイプラインの構築に示されているように、カスタムサービスを作成しました。拡張サービスJarファイル( `beam-sdks-java-io-expansion-service.jar`)は、パイプラインを実行するKubernetes *ジョブ*に存在する必要があります。Java SDK( `/ opt / apache / beam / boot`)はランナーワーカーに存在する必要があります。
# beam/word_len/word_len.py
import json
import argparse
import re
import logging
import typing
import apache_beam as beam
from apache_beam import pvalue
from apache_beam.io import kafka
from apache_beam.transforms.window import FixedWindows
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import SetupOptions
from apache_beam.transforms.external import JavaJarExpansionService
def get_expansion_service(
jar="/opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar", args=None
):
if args == None:
args = [
"--defaultEnvironmentType=PROCESS",
'--defaultEnvironmentConfig={"command": "/opt/apache/beam/boot"}',
"--experiments=use_deprecated_read",
]
return JavaJarExpansionService(jar, ["{{PORT}}"] + args)
class WordAccum(typing.NamedTuple):
length: int
count: int
beam.coders.registry.register_coder(WordAccum, beam.coders.RowCoder)
def decode_message(kafka_kv: tuple, verbose: bool = False):
if verbose:
print(kafka_kv)
return kafka_kv[1].decode("utf-8")
def tokenize(element: str):
return re.findall(r"[A-Za-z\']+", element)
def create_message(element: typing.Tuple[str, str, float]):
msg = json.dumps(dict(zip(["window_start", "window_end", "avg_len"], element)))
print(msg)
return "".encode("utf-8"), msg.encode("utf-8")
class AverageFn(beam.CombineFn):
def create_accumulator(self):
return WordAccum(length=0, count=0)
def add_input(self, mutable_accumulator: WordAccum, element: str):
length, count = tuple(mutable_accumulator)
return WordAccum(length=length + len(element), count=count + 1)
def merge_accumulators(self, accumulators: typing.List[WordAccum]):
lengths, counts = zip(*accumulators)
return WordAccum(length=sum(lengths), count=sum(counts))
def extract_output(self, accumulator: WordAccum):
length, count = tuple(accumulator)
return length / count if count else float("NaN")
def get_accumulator_coder(self):
return beam.coders.registry.get_coder(WordAccum)
class AddWindowTS(beam.DoFn):
def process(self, avg_len: float, win_param=beam.DoFn.WindowParam):
yield (
win_param.start.to_rfc3339(),
win_param.end.to_rfc3339(),
avg_len,
)
class ReadWordsFromKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topics: typing.List[str],
group_id: str,
verbose: bool = False,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topics = topics
self.group_id = group_id
self.verbose = verbose
self.expansion_service = expansion_service
def expand(self, input: pvalue.PBegin):
return (
input
| "ReadFromKafka"
>> kafka.ReadFromKafka(
consumer_config={
"bootstrap.servers": self.boostrap_servers,
"auto.offset.reset": "latest",
# "enable.auto.commit": "true",
"group.id": self.group_id,
},
topics=self.topics,
timestamp_policy=kafka.ReadFromKafka.create_time_policy,
commit_offset_in_finalize=True,
expansion_service=self.expansion_service,
)
| "DecodeMessage" >> beam.Map(decode_message)
| "Tokenize" >> beam.FlatMap(tokenize)
)
class CalculateAvgWordLen(beam.PTransform):
def expand(self, input: pvalue.PCollection):
return (
input
| "Windowing" >> beam.WindowInto(FixedWindows(size=5))
| "GetAvgWordLength" >> beam.CombineGlobally(AverageFn()).without_defaults()
)
class WriteWordLenToKafka(beam.PTransform):
def __init__(
self,
bootstrap_servers: str,
topic: str,
expansion_service: typing.Any = None,
label: str | None = None,
) -> None:
super().__init__(label)
self.boostrap_servers = bootstrap_servers
self.topic = topic
self.expansion_service = expansion_service
def expand(self, input: pvalue.PCollection):
return (
input
| "AddWindowTS" >> beam.ParDo(AddWindowTS())
| "CreateMessages"
>> beam.Map(create_message).with_output_types(typing.Tuple[bytes, bytes])
| "WriteToKafka"
>> kafka.WriteToKafka(
producer_config={"bootstrap.servers": self.boostrap_servers},
topic=self.topic,
expansion_service=self.expansion_service,
)
)
def run(argv=None, save_main_session=True):
parser = argparse.ArgumentParser(description="Beam pipeline arguments")
parser.add_argument(
"--deploy",
dest="deploy",
action="store_true",
default="Flag to indicate whether to deploy to a cluster",
)
parser.add_argument(
"--bootstrap_servers",
dest="bootstrap",
default="host.docker.internal:29092",
help="Kafka bootstrap server addresses",
)
parser.add_argument(
"--input_topic",
dest="input",
default="input-topic",
help="Kafka input topic name",
)
parser.add_argument(
"--output_topic",
dest="output",
default="output-topic-beam",
help="Kafka output topic name",
)
parser.add_argument(
"--group_id",
dest="group",
default="beam-word-len",
help="Kafka output group ID",
)
known_args, pipeline_args = parser.parse_known_args(argv)
print(known_args)
print(pipeline_args)
# We use the save_main_session option because one or more DoFn elements in this
# workflow rely on global context. That is, a module imported at the module level.
pipeline_options = PipelineOptions(pipeline_args)
pipeline_options.view_as(SetupOptions).save_main_session = save_main_session
expansion_service = None
if known_args.deploy is True:
expansion_service = get_expansion_service()
with beam.Pipeline(options=pipeline_options) as p:
(
p
| "ReadWordsFromKafka"
>> ReadWordsFromKafka(
bootstrap_servers=known_args.bootstrap,
topics=[known_args.input],
group_id=known_args.group,
expansion_service=expansion_service,
)
| "CalculateAvgWordLen" >> CalculateAvgWordLen()
| "WriteWordLenToKafka"
>> WriteWordLenToKafka(
bootstrap_servers=known_args.bootstrap,
topic=known_args.output,
expansion_service=expansion_service,
)
)
logging.getLogger().setLevel(logging.DEBUG)
logging.info("Building pipeline ...")
if __name__ == "__main__":
run()
パイプラインスクリプトは、 `word_len`という名前のフォルダーにあるPythonパッケージに追加されます。 `python -m ...`のようにモジュールとして実行されるため、 `run`という名前の単純なモジュールが作成されます。パイプラインをスクリプトとして実行したときにエラーが発生しました。このパッケージ化方法は、デモンストレーションのみを目的としています。推奨されるパイプラインのパッケージ化方法については、Pythonパイプラインの依存関係の管理を参照してください。
# beam/word_len/run.py
from . import *
run()
全体として、パイプラインパッケージは次の構造を使用します。
tree beam/word_len
beam/word_len
├── __init__.py
├── run.py
└── word_len.pyDockerイメージの構築
前述のように、カスタムDockerイメージ( *beam-python-example:1.16*)を構築し、それを使用してFlinkクラスタをデプロイし、Kafka Connector I / OのJavaユーザーコードを実行します。
# beam/Dockerfile
FROM flink:1.16
COPY --from=apache/beam_java11_sdk:2.56.0 /opt/apache/beam/ /opt/apache/beam/
また、Pythonユーザーコード(*SDKハーネス*)を実行するために、カスタムDockerイメージ( *beam-python-harness:2.56.0*)も構築します。Python SDK Dockerイメージから、最初にJava Development Kit(JDK)をインストールし、* Java IO Expansion Service * Jarファイルをダウンロードします。次に、Beamパイプラインパッケージが `/ app`フォルダーにコピーされます。アプリフォルダーは `PYTHONPATH`環境変数に追加され、パッケージを検索可能にします。
# beam/Dockerfile-python-harness
FROM apache/beam_python3.10_sdk:2.56.0
ARG BEAM_VERSION
ENV BEAM_VERSION=${BEAM_VERSION:-2.56.0}
ENV REPO_BASE_URL=https://repo1.maven.org/maven2/org/apache/beam
RUN apt-get update && apt-get install -y default-jdk
RUN mkdir -p /opt/apache/beam/jars \
&& wget ${REPO_BASE_URL}/beam-sdks-java-io-expansion-service/${BEAM_VERSION}/beam-sdks-java-io-expansion-service-${BEAM_VERSION}.jar \
--progress=bar:force:noscroll -O /opt/apache/beam/jars/beam-sdks-java-io-expansion-service.jar
COPY word_len /app/word_len
COPY word_count /app/word_count
ENV PYTHONPATH="$PYTHONPATH:/app"
カスタムイメージはminikubeクラスタでアクセスできる必要があるため、ターミナルの `docker-cli`をminikubeのDockerエンジンに向けます。次に、 `docker build`コマンドを使用してイメージをビルドできます。
eval $(minikube docker-env)
docker build -t beam-python-example:1.16 beam/
docker build -t beam-python-harness:2.56.0 -f beam/Dockerfile-python-harness beam/ストリーム処理アプリケーションのデプロイ
Beamパイプラインは、Flink Kubernetes OperatorによってデプロイされたFlinkセッションクラスタで実行されます。アプリケーションデプロイメントモード(BeamパイプラインがFlinkジョブとしてデプロイされる)は、ジョブ送信タイムアウトエラーまたはジョブアーティファクトのアップロードの失敗が原因で機能しないようです(または、まだその方法を理解していません)。パイプラインがデプロイされた後、入力Kafkaトピックにテキストメッセージを送信することにより、アプリケーションの出力を確認します。
Flink Kubernetes Operatorのデプロイ
最初に、webhookコンポーネントを追加できるようにするために、minikubeクラスタに証明書マネージャーをインストールします。次に、Helmチャートを使用してオペレーターをインストールします。バージョン1.8.0がこの投稿にインストールされています。
kubectl create -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
helm repo add flink-operator-repo https://downloads.apache.org/flink/flink-kubernetes-operator-1.8.0/
helm install flink-kubernetes-operator flink-operator-repo/flink-kubernetes-operator
# NAME: flink-kubernetes-operator
# LAST DEPLOYED: Mon Jun 03 21:37:45 2024
# NAMESPACE: default
# STATUS: deployed
# REVISION: 1
# TEST SUITE: None
helm list
# NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
# flink-kubernetes-operator default 1 2024-06-03 21:37:45.579302452 +1000 AEST deployed flink-kubernetes-operator-1.8.0 1.8.0Beamパイプラインのデプロイ
まず、Flinkセッションクラスタを作成します。マニフェストファイルで、Dockerイメージ、Flinkバージョン、クラスタ構成、Podテンプレートなどの共通プロパティを設定します。これらのプロパティは、Flinkジョブマネージャーとタスクマネージャーに適用されます。さらに、レプリカとリソースを指定します。タスクマネージャーにサイドカーコンテナを追加します。このSDKハーネスコンテナは、Pythonユーザーコードを実行するように構成されています。以下のジョブ構成を参照してください。
# beam/word_len_cluster.yml
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: word-len-cluster
spec:
image: beam-python-example:1.16
imagePullPolicy: Never
flinkVersion: v1_16
flinkConfiguration:
taskmanager.numberOfTaskSlots: "10"
serviceAccount: flink
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /opt/flink/log
name: flink-logs
volumes:
- name: flink-logs
emptyDir: {}
jobManager:
resource:
memory: "2048Mi"
cpu: 2
taskManager:
replicas: 1
resource:
memory: "2048Mi"
cpu: 2
podTemplate:
spec:
containers:
- name: python-harness
image: beam-python-harness:2.56.0
args: ["-worker_pool"]
ports:
- containerPort: 50000
name: harness-port
パイプラインはKubernetesジョブを使用してデプロイされ、カスタムのSDKハーネスイメージを使用してパイプラインがモジュールとして実行されます。最初の2つの引数はアプリケーション固有です。残りの引数はパイプラインオプション用です。パイプライン引数の詳細については、パイプラインオプションのソースとFlink Runnerドキュメントを参照してください。サイドカーコンテナでPythonユーザーコードを実行するために、環境タイプをEXTERNALに、環境設定をlocalhost:50000に設定します。
# beam/word_len_job.yml
apiVersion: batch/v1
kind: Job
metadata:
name: word-len-job
spec:
template:
metadata:
labels:
app: word-len-job
spec:
containers:
- name: beam-word-len-job
image: beam-python-harness:2.56.0
command: ["python"]
args:
- "-m"
- "word_len.run"
- "--deploy"
- "--bootstrap_servers=demo-cluster-kafka-bootstrap:9092"
- "--runner=FlinkRunner"
- "--flink_master=word-len-cluster-rest:8081"
- "--job_name=beam-word-len"
- "--streaming"
- "--parallelism=3"
- "--flink_submit_uber_jar"
- "--environment_type=EXTERNAL"
- "--environment_config=localhost:50000"
- "--checkpointing_interval=10000"
restartPolicy: Never
kubectl createコマンドを使用して、セッションクラスタとジョブをデプロイします。セッションクラスタは、FlinkDeploymentカスタムリソースによって作成され、ジョブマネージャーのデプロイメント、タスクマネージャーポッド、および関連するサービスを管理します。ジョブのポッドのログを確認すると、以下のタスクが実行されていることがわかります。
- Jarファイルをダウンロードした後、ジョブサービスを開始します。
- パイプラインアーティファクトをアップロードします。
- パイプラインをFlinkジョブとして送信します。
- ジョブのステータスを継続的に監視します。
kubectl create -f beam/word_len_cluster.yml
# flinkdeployment.flink.apache.org/word-len-cluster created
kubectl create -f beam/word_len_job.yml
# job.batch/word-len-job created
kubectl logs word-len-job-p5rph -f
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# INFO:root:Building pipeline ...
# INFO:apache_beam.runners.portability.flink_runner:Adding HTTP protocol scheme to flink_master parameter: http://word-len-cluster-rest:8081
# WARNING:apache_beam.options.pipeline_options:Unknown pipeline options received: --checkpointing_interval=10000. Ignore if flags are used for internal purposes.
# DEBUG:apache_beam.runners.portability.abstract_job_service:Got Prepare request.
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/config HTTP/1.1" 200 240
# INFO:apache_beam.utils.subprocess_server:Downloading job server jar from https://repo.maven.apache.org/maven2/org/apache/beam/beam-runners-flink-1.16-job-server/2.56.0/beam-runners-flink-1.16-job-server-2.56.0.jar
# INFO:apache_beam.runners.portability.abstract_job_service:Artifact server started on port 43287
# DEBUG:apache_beam.runners.portability.abstract_job_service:Prepared job 'job' as 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# INFO:apache_beam.runners.portability.abstract_job_service:Running job 'job-edc1c2f1-80ef-48b7-af14-7e6fc86f338a'
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/upload HTTP/1.1" 200 148
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "POST /v1/jars/e1984c45-d8bc-4aa1-9b66-369a23826921_beam.jar/run HTTP/1.1" 200 44
# INFO:apache_beam.runners.portability.flink_uber_jar_job_server:Started Flink job as a403cb2f92fecee65b8fd7cc8ac6e68a
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to STOPPED
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# INFO:apache_beam.runners.portability.portable_runner:Job state changed to RUNNING
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): word-len-cluster-rest:8081
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# DEBUG:urllib3.connectionpool:http://word-len-cluster-rest:8081 "GET /v1/jobs/a403cb2f92fecee65b8fd7cc8ac6e68a/execution-result HTTP/1.1" 200 31
# ...デプロイメントが完了すると、以下のFlinkセッションクラスタとジョブ関連のリソースが表示されます。
kubectl get all -l app=word-len-cluster
# NAME READY STATUS RESTARTS AGE
# pod/word-len-cluster-7c98f6f868-d4hbx 1/1 Running 0 5m32s
# pod/word-len-cluster-taskmanager-1-1 2/2 Running 0 4m3s
# NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
# service/word-len-cluster ClusterIP None <none> 6123/TCP,6124/TCP 5m32s
# service/word-len-cluster-rest ClusterIP 10.104.23.28 <none> 8081/TCP 5m32s
# NAME READY UP-TO-DATE AVAILABLE AGE
# deployment.apps/word-len-cluster 1/1 1 1 5m32s
# NAME DESIRED CURRENT READY AGE
# replicaset.apps/word-len-cluster-7c98f6f868 1 1 1 5m32s
kubectl get all -l app=word-len-job
# NAME READY STATUS RESTARTS AGE
# pod/word-len-job-24r6q 1/1 Running 0 5m24s
# NAME COMPLETIONS DURATION AGE
# job.batch/word-len-job 0/1 5m24s 5m24sポート8081でkubectl port-forwardコマンドを使用して、Flink Web UIにアクセスできます。ジョブグラフには2つのタスクが表示されます。最初のタスクは、単語要素を固定時間ウィンドウに追加します。2番目のタスクは、平均単語長のレコードを出力トピックに送信します。
kubectl port-forward svc/flink-word-len-rest 8081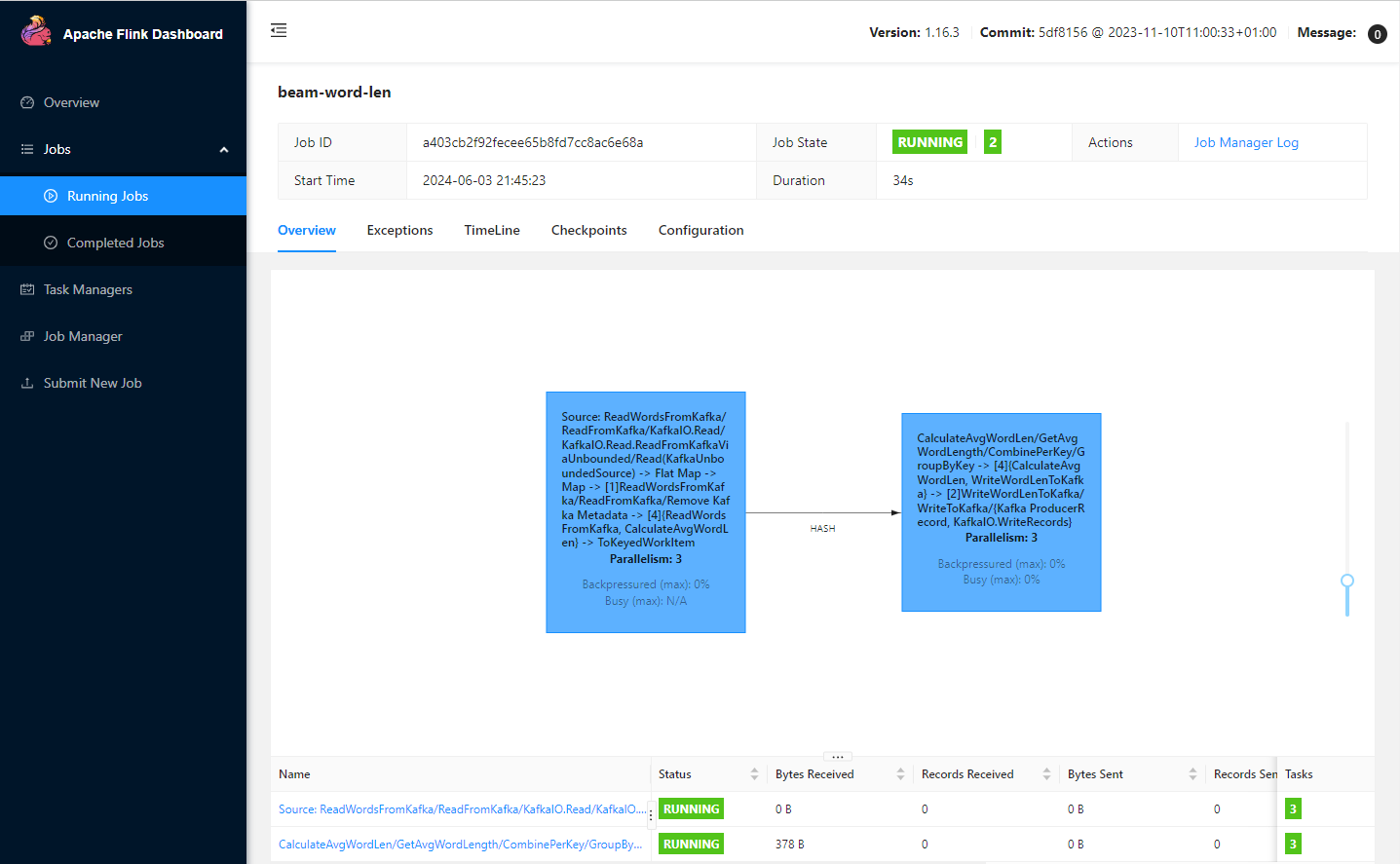
Kafka I/Oは、トピックが存在しない場合は自動的に作成します。入力トピックはkafka-uiに作成されていることがわかります。
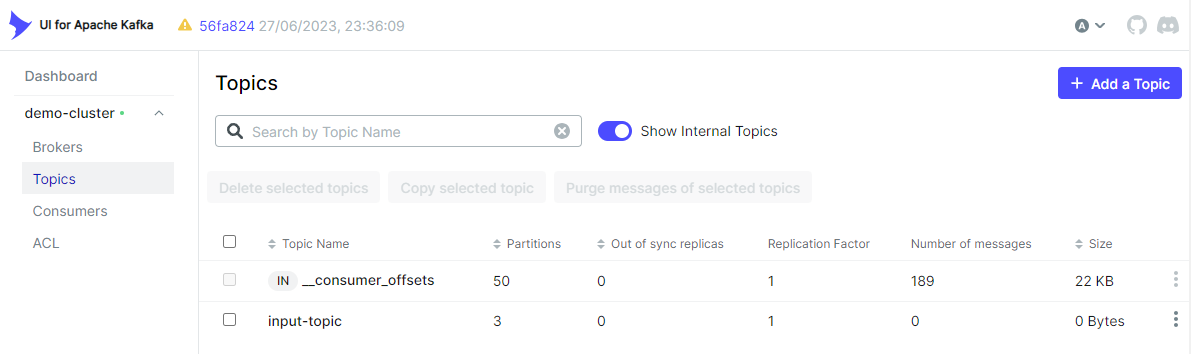
Kafkaプロデューサー
アプリケーションの出力を確認するために、シンプルなPython Kafkaプロデューサーが作成されます。デフォルトでは、プロデューサーアプリはFakerパッケージからのランダムなテキストを1秒ごとにKafkaの入力トピックに送信します。
# kafka/client/producer.py
import os
import time
from faker import Faker
from kafka import KafkaProducer
class TextProducer:
def __init__(self, bootstrap_servers: list, topic_name: str) -> None:
self.bootstrap_servers = bootstrap_servers
self.topic_name = topic_name
self.kafka_producer = self.create_producer()
def create_producer(self):
"""
Returns a KafkaProducer instance
"""
return KafkaProducer(
bootstrap_servers=self.bootstrap_servers,
value_serializer=lambda v: v.encode("utf-8"),
)
def send_to_kafka(self, text: str, timestamp_ms: int = None):
"""
Sends text to a Kafka topic.
"""
try:
args = {"topic": self.topic_name, "value": text}
if timestamp_ms is not None:
args = {**args, **{"timestamp_ms": timestamp_ms}}
self.kafka_producer.send(**args)
self.kafka_producer.flush()
except Exception as e:
raise RuntimeError("fails to send a message") from e
if __name__ == "__main__":
producer = TextProducer(
os.getenv("BOOTSTRAP_SERVERS", "localhost:29092"),
os.getenv("TOPIC_NAME", "input-topic"),
)
fake = Faker()
num_events = 0
while True:
num_events += 1
text = fake.text()
producer.send_to_kafka(text)
if num_events % 5 == 0:
print(f"<<<<<{num_events} text sent... current>>>>\n{text}")
time.sleep(int(os.getenv("DELAY_SECONDS", "1")))
kubectl port-forwardコマンドを使用して、Kafkaブートストラップサーバーをポート29092で公開します。Pythonスクリプトを実行して、プロデューサーアプリを起動します。
kubectl port-forward svc/demo-cluster-kafka-external-bootstrap 29092
python kafka/client/producer.py出力トピック(output-topic-beam)がkafka-uiに作成されていることがわかります。
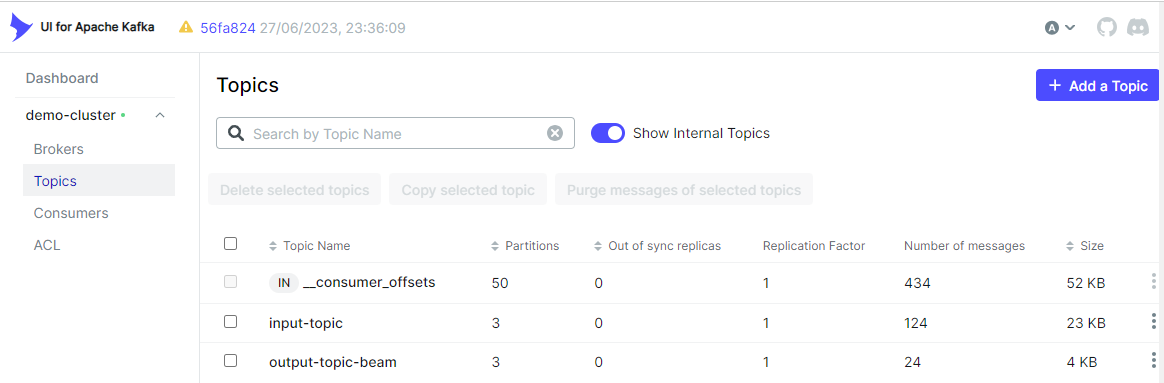
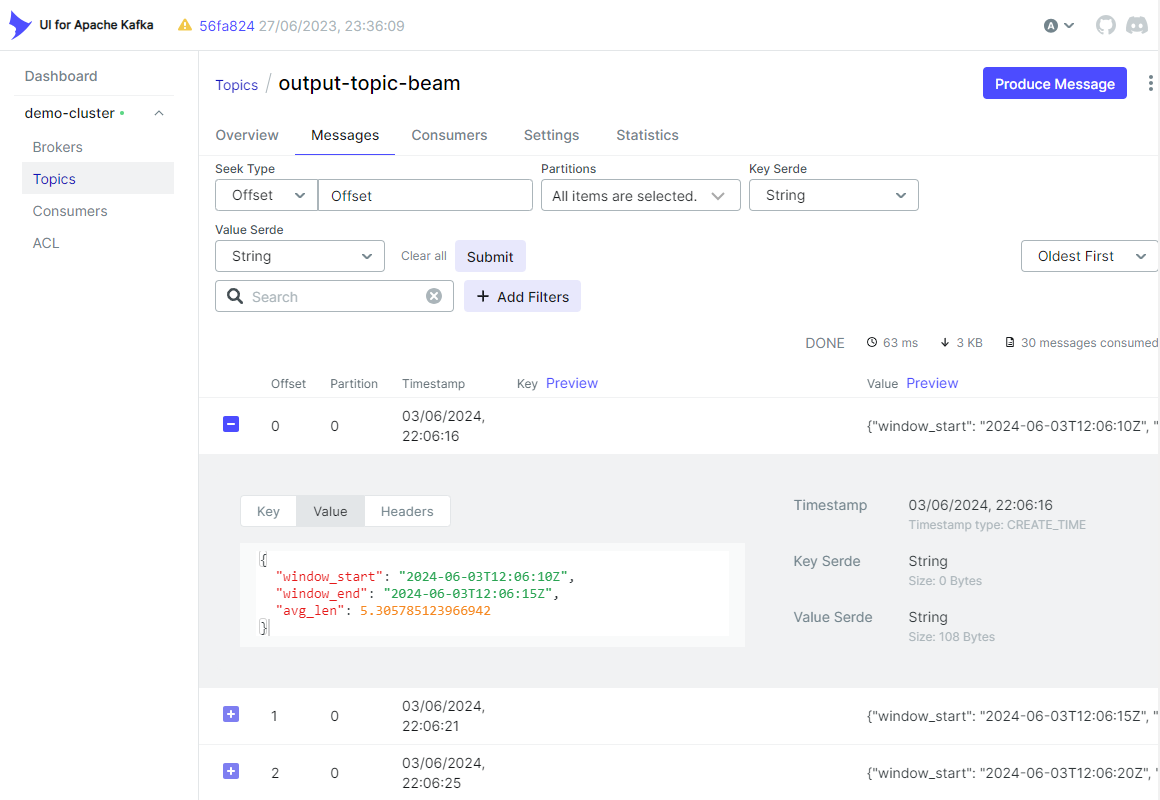
また、**トピック**タブで、出力メッセージが期待どおりに作成されていることを確認できます。
リソースの削除
以下の手順を使用して、Kubernetesリソースとminikubeクラスタを削除します。
## Delete the Flink Operator and related resources.
kubectl delete -f beam/word_len_cluster.yml
kubectl delete -f beam/word_len_job.yml
helm uninstall flink-kubernetes-operator
helm repo remove flink-operator-repo
kubectl delete -f https://github.com/jetstack/cert-manager/releases/download/v1.8.2/cert-manager.yaml
## Delete the Kafka cluster and related resources.
STRIMZI_VERSION="0.39.0"
kubectl delete -f kafka/manifests/kafka-cluster.yaml
kubectl delete -f kafka/manifests/kafka-ui.yaml
kubectl delete -f kafka/manifests/strimzi-cluster-operator-$STRIMZI_VERSION.yaml
## Delete the minikube.
minikube delete