



ブログ
2022/04/28
ノートブックで Beam SQL を実行する
はじめに
Beam SQL を使用すると、Beam ユーザーは SQL ステートメントで PCollection をクエリできます。Interactive Beam は、Apache Beam と Jupyter Notebooks (以前は IPython Notebooks として知られていました) の統合を提供し、パイプラインのプロトタイピングとデータ探索をより迅速かつ容易にします。ドキュメントに従って、独自のノートブック ユーザー インターフェイス (たとえば、JupyterLab または従来の Jupyter Notebooks) を独自のデバイスにセットアップできます。あるいは、すべてを自動的に行うホスト ソリューションを選択することもできます。自由に好みのノートブック ユーザー インターフェイスを選択できます。簡単にするために、この記事ではノートブック環境のセットアップについては説明せず、クラウド ホスト型の JupyterLab 環境を提供する Apache Beam Notebooks を使用します。これにより、Beam ユーザーはパイプラインを反復的に開発し、パイプライン グラフを検査し、読み取り、評価、印刷のループ (REPL) ワークフローで個々の PCollection を解析できます。
この記事では、ノートブック マジック である beam_sql を使用して、ノートブックで Beam SQL を実行し、結果を検査する方法について説明します。
この記事の最後には、Dataflow で 1 回限りのジョブとして実行するなど、本番環境で beam_sql マジックを使用する方法も説明します。これはオプションです。これらの手順に従うには、必要な API が有効になっている Google Cloud Platform プロジェクトが必要です。また、Google Cloud Storage バケットを作成する (または既存のバケットを使用する)、公開されている Google Cloud BigQuery データセットをクエリする、Dataflow ジョブを実行するための十分な権限が必要です。
クラウド ホスト型のノートブック ソリューションを使用する場合は、Google Cloud プロジェクトを準備したら、Apache Beam Notebooks インスタンスを作成し、JupyterLab Web インターフェイスを開く必要があります。次の手順に従ってください: https://cloud.google.com/dataflow/docs/guides/interactive-pipeline-development#launching_an_notebooks_instance
環境の理解
ランディング ページ
独自のノートブック ユーザー インターフェイスを起動した後: たとえば、Apche Beam Notebooks を使用している場合は、[OPEN JUPYTERLAB] リンクをクリックすると、ノートブック環境のデフォルトのランチャー ページに移動します。
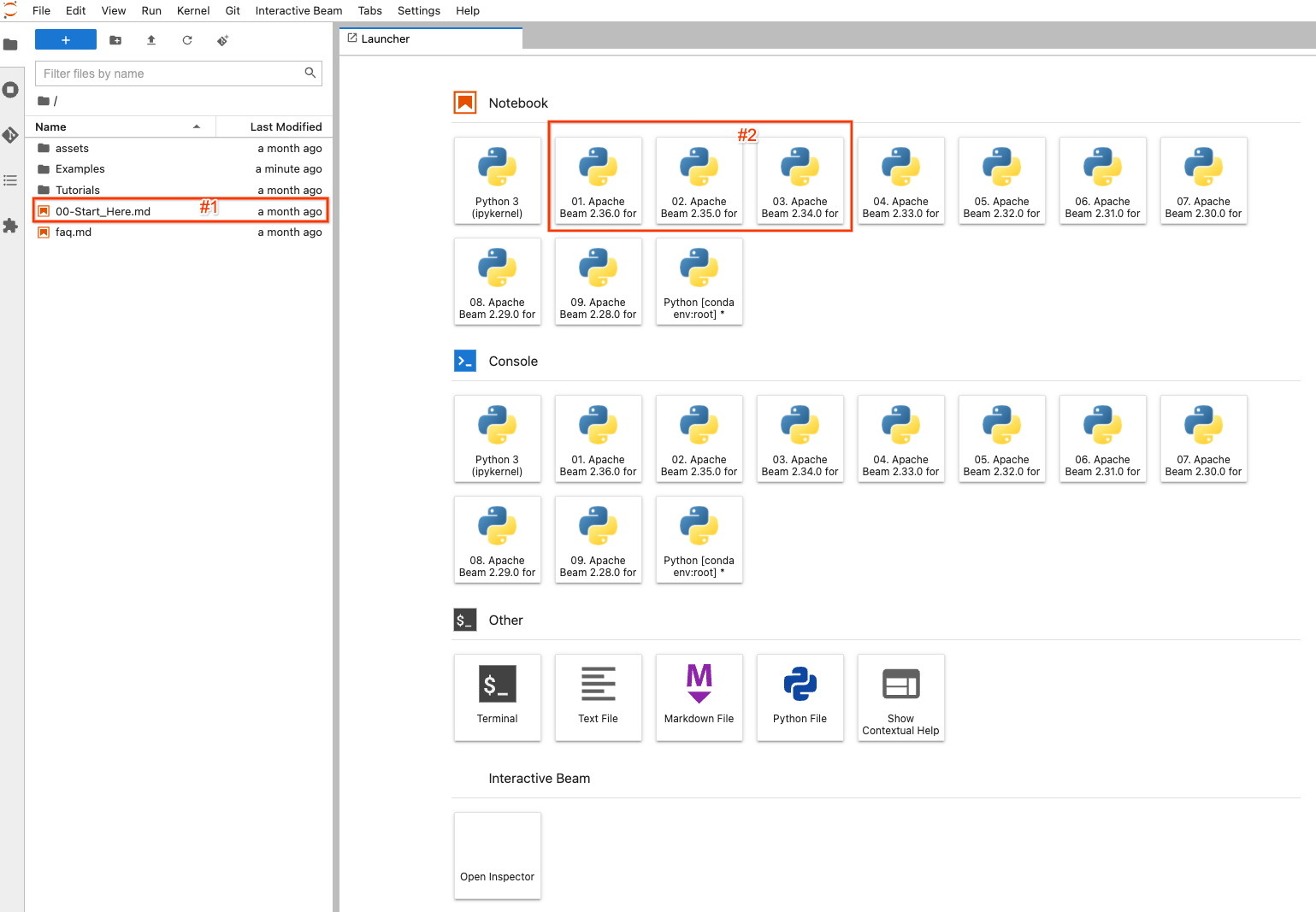
左側には、ノートブック インスタンスの例、チュートリアル、アセットを表示するためのファイル エクスプローラーがあります。ファイルを簡単に移動するには、00-Start_Here.md (#1 のスクリーンショット) ファイルをダブルクリックして、ファイルに関する詳細情報を表示します。
右側には、JupyterLab のデフォルトのランチャー ページが表示されます。完全に新しいノートブック ファイルを作成して開き、選択したバージョンの Apache Beam でコードを作成するには、Apache Beam >=2.34.0 がインストールされている (#2) 項目のいずれかをクリックします (beam_sql が 2.34.0 で導入されたため)。
ノートブックの作成/オープン
たとえば、Apache Beam 2.36.0 のイメージ ボタンをクリックすると、Untitled.ipynb ファイルが作成されて開きます。
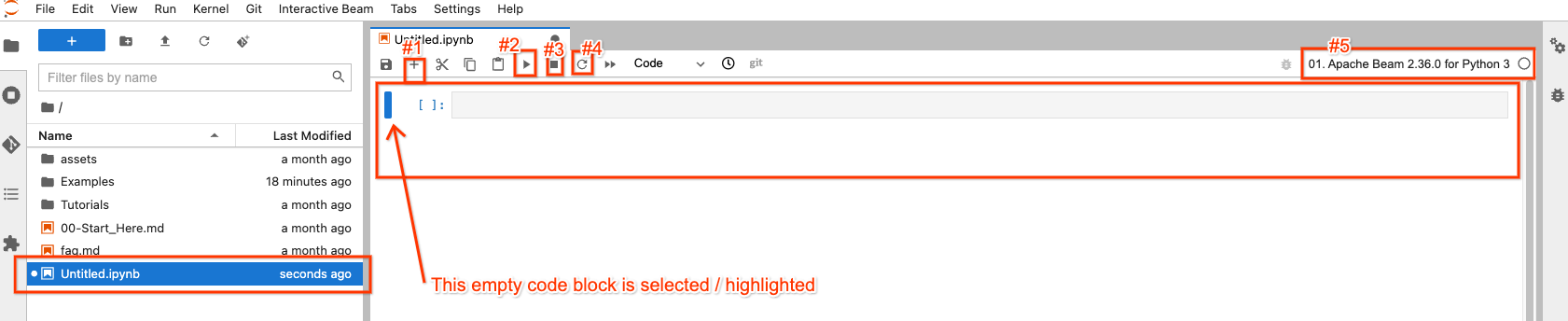
ファイル エクスプローラーでは、新しいノートブック ファイルが Untitled.ipynb として作成されています。
右側の開いているノートブックには、頻繁に操作する可能性のある 4 つのボタンが上部にあります
- #1: 選択/強調表示されたコード ブロックの後に空のコード ブロックを挿入します
- #2: 選択/強調表示されたブロック内のコードを実行します
- #3: コードの実行が停止した場合にコードの実行を中断します
- #4: 「カーネルを再起動する」: コードの実行からすべての状態をクリアし、最初からやり直します
必要に応じて別の Apache Beam バージョンを選択するためのボタンが右上 (#5) にあり、固定されていません。
ファイル エクスプローラーからファイルをダブルクリックして、新しいファイルを作成せずに開くことができます。
Beam SQL
beam_sql マジック
beam_sql は、IPython の カスタム マジック です。マジックに慣れていない場合は、組み込みの例 をいくつか紹介します。リモート クラスター/サービスで本番環境にする前に、SQL を使用して Beam パイプラインをプロトタイピングする際に、既知/テスト データ ソースに対してクエリをローカルで検証するのに便利な方法です。
Apache Beam Notebooks 環境には、beam_sql マジックと基本的な apache-beam モジュールがプリロードされているため、追加のインポートなしで直接使用できます。また、他の場所で独自のノートブックを設定した場合は、%load_ext apache_beam.runners.interactive.sql.beam_sql_magics と apache-beam モジュールを使用してマジックを明示的にロードすることもできます。
次のように入力できます
%beam_sql -h
次に、コードを実行してマジックの使用方法を学びます
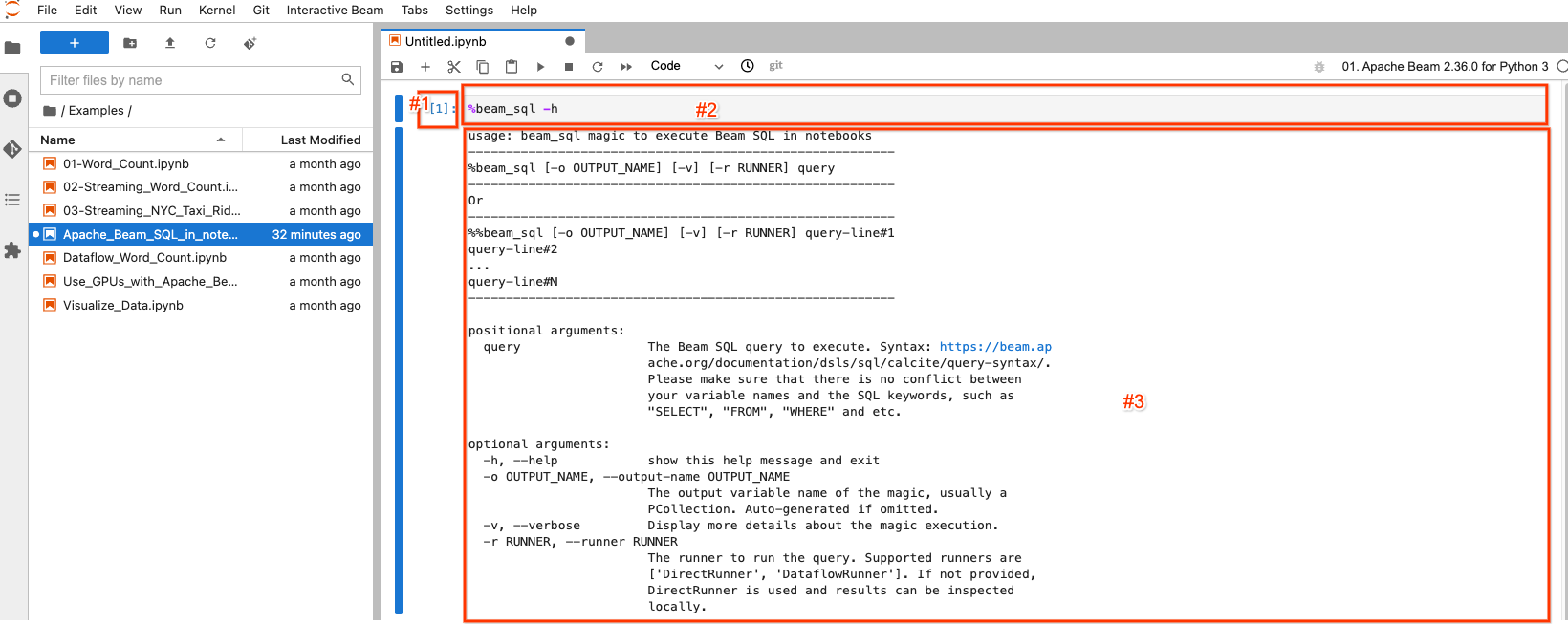
選択/強調表示されたブロックは、ノートブック セルと呼ばれます。主に 3 つのコンポーネントがあります
- #1: 実行カウント。
[1]は、このブロックが最初に実行されたコードであることを示します。同じコードを再実行した場合でも、実行するコードごとに 1 ずつ増加します。[ ]は、このブロックが実行されていないことを示します。 - #2: セル入力: コードが実行されます。
- #3: セル出力: コード実行の出力。ここでは、
beam_sqlマジックのヘルプ ドキュメントが含まれています。
PCollection の作成
PCollection を作成する際の Beam SQL には、3 つのシナリオがあります
- Beam SQL を使用して、定数値から PCollection を作成する
%%beam_sql -o pcoll
SELECT CAST(1 AS INT) AS id, CAST('foo' AS VARCHAR) AS str, CAST(3.14 AS DOUBLE) AS flt

beam_sql マジックは、BeamSchema_...(id: int32, str: str, flt: float64) のような element_type を持つ pcoll という名前の PCollection を作成して出力します。
注: Beam パイプラインを明示的に作成したわけではありません。beam_sql マジックは常に暗黙的にパイプラインを作成して SQL クエリを実行するため、PCollection を取得します。各フィールドの型情報を持つ要素を保持するために、Beam は作成された PCollection の element_type として スキーマ を自動的に作成します。スキーマ対応の PCollection については後で詳しく説明します。
- Beam SQL を使用して PCollection をクエリする
前の SQL の出力 (または通常の Beam PTransforms によって生成されたスキーマ対応の PCollection) を入力として使用して、別の SQL を連鎖させて新しい PCollection を作成できます。
注: 出力 PCollection に名前を付ける場合は、別の PCollection を上書きしないように、ノートブック内で一意であることを確認してください。
%%beam_sql -o id_pcoll
SELECT id FROM pcoll

- Beam SQL を使用して複数の PCollection を結合する
1 つのクエリから複数の PCollection をクエリできます。
%%beam_sql -o str_with_same_id
SELECT id, str FROM pcoll JOIN id_pcoll USING (id)

これで、beam_sql マジックを使用して PCollection を作成し、その結果を検査する方法を学びました。
ヒント: ノートブック セルの出力を誤って削除した場合でも、ib.show(pcoll_name) または ib.collect(pcoll_name) を呼び出すことで、PCollection の内容をいつでも確認できます。ここで ib は 「Interactive Beam」 を表します (詳細はこちら)。
スキーマ対応 PCollection
beam_sql マジックは、SQL と非 SQL の Beam ステートメントをシームレスに組み合わせてパイプラインを構築し、Dataflow で実行する柔軟性を提供します。ただし、Beam SQL でクエリされる各 PCollection には、スキーマ が必要です。beam_sql マジックの場合、スキーマが必要な場合は typing.NamedTuple を使用することをお勧めします。以下の例を参照して、スキーマ対応の PCollection の詳細を確認できます。
セットアップ
この例のセットアップでは、次のことを行います
- 組み込みの
%pipマジックを使用して PyPI パッケージnamesをインストールします。モジュールを使用して、生のデータ入力としていくつかのランダムな英語の名前を生成します。 - 2 つの属性を持つ
NamedTupleでスキーマを定義します:id- 個人の一意の数値識別子;name- 個人の文字列名。 - Apache Beam のノートブック関連機能を利用するために
InteractiveRunnerを使用してパイプラインを定義します。
%pip install names
import names
from typing import NamedTuple
class Person(NamedTuple):
id: int
name: str
p = beam.Pipeline(InteractiveRunner())
コード実行の目に見える出力はありません。
SQL を使用せずにスキーマ対応の PCollection を作成する
persons = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(10)]))
ib.show(persons)

persons_2 = (p
| beam.Create([Person(id=x, name=names.get_full_name()) for x in range(5, 15)]))
ib.show(persons_2)

これで、両方とも Person クラスで定義された同じスキーマを持つ 2 つの PCollection ができました
personsには、0 から 9 の範囲の ID を持つ 10 人の 10 件のレコードが含まれています。persons_2には、5 から 14 の範囲の ID を持つ 10 人の 10 件のレコードが含まれています。
スキーマ対応 PCollection のエンコードとデコード
この例では、この記事の説明に従って作成した最初の pcoll からもう 1 つのデータが必要です。
元の pcoll を使用できます。オプションで、スキーマ対応の PCollection でコーダーを明示的に使用したい場合は、Text I/O をミックスに追加できます。pcoll の内容をテキスト ファイルに書き込み、そのスキーマ情報を保持し、ファイルの内容を pcoll_in_file という新しいスキーマ対応の PCollection に読み込み直し、新しい PCollection を使用して persons と persons_2 を結合し、3 つすべてに共通の ID を持つ名前を見つけます。
pcoll をファイルにエンコードするには、次を実行します
coder=beam.coders.registry.get_coder(pcoll.element_type)
pcoll | beam.io.textio.WriteToText('/tmp/pcoll', coder=coder)
pcoll.pipeline.run().wait_until_finish()
!cat /tmp/pcoll*

上記のコード実行では、PCollection pcoll (基本的には {id: 1, str: foo, flt: 3.14}) を、Beam によって割り当てられたコーダーを使用してテキスト ファイルに書き込みます。ご覧のとおり、ファイルの内容はバイナリの人間が読めない形式で記録されていますが、これは正常です。
ファイルの内容を新しい PCollection にデコードするには、次を実行します
pcoll_in_file = p | beam.io.ReadFromText(
'/tmp/pcoll*', coder=coder).with_output_types(
pcoll.element_type)
ib.show(pcoll_in_file)

注: エンコードとデコード中に同じコーダーを使用する必要があり、さらに with_output_types() を介して新しい PCollection にスキーマを明示的に割り当てることもできます。
テキスト ファイルからエンコードされたバイナリの内容を読み取り、正しいコーダーでデコードすると、pcoll の内容が pcoll_in_file に復元されます。この手法を使用して、独自のパイプライン (ノートブック セッションまたはパイプラインだけでなく) で作業する共同作業者と、任意の Beam I/O (必ずしもテキスト ファイルである必要はありません) を介してデータを保存および共有できます。
beam_sql マジックのスキーマ
beam_sql マジックは、NamedTuple スキーマの RowCoder を自動的に登録するため、コーダーを気にすることなく、クエリ用のデータの準備に集中するだけで済みます。beam_sql マジックが内部で実行する処理の詳細については、-v オプションを使用できます。
例えば、以下のクエリでpersonsの中からid < 5のすべての要素を検索し、出力をpersons_id_lt_5に割り当てることができます。
%%beam_sql -o persons_id_lt_5 -v
SELECT * FROM persons WHERE id < 5
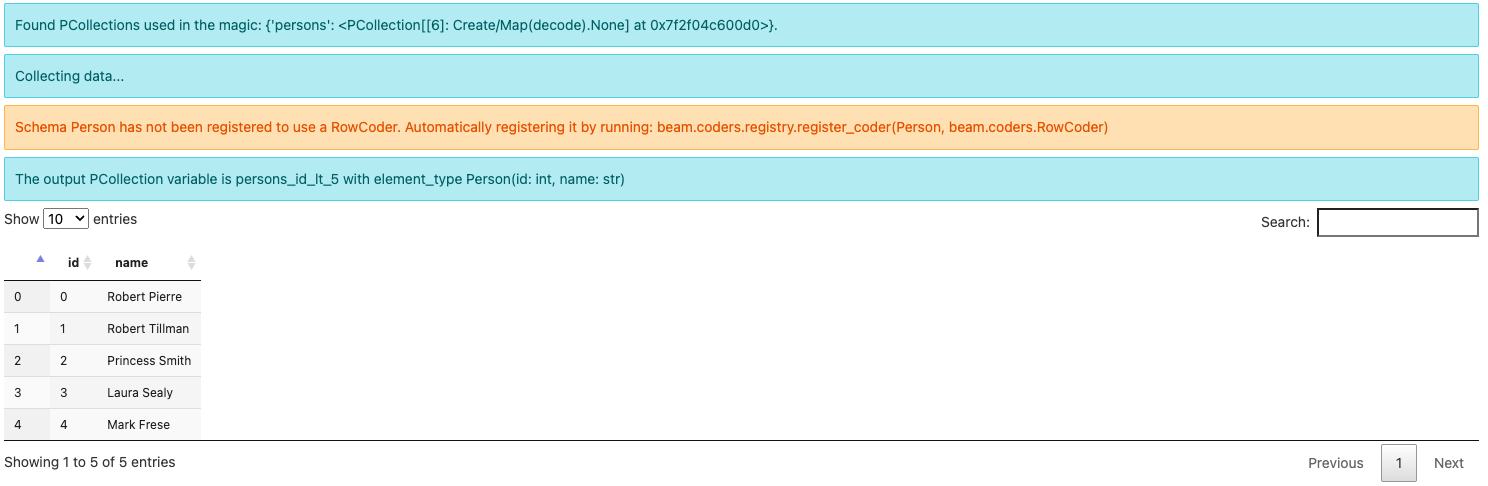
このクエリを実行するのが初めての場合、以下のような警告メッセージが表示されるかもしれません。
スキーマPersonはRowCoderを使用するために登録されていません。beam.coders.registry.register_coder(Person, beam.coders.RowCoder)を実行して自動的に登録します。
beam_sqlマジックは、定義して使用する各スキーマに対してRowCoderを登録するのに役立ちます。また、明示的に同じコードを実行することもできます。
注意:出力要素の型は、既知の型Person(id: int, name: str)の単一のPCollectionからすべてのフィールドを選択したため、BeamSchema_…ではなくPerson(id: int, name: str)になります。
別の例として、同じIDを持つpersonsとpersons_2からすべての名前をクエリして、出力をpersons_with_common_idに割り当てることができます。
%%beam_sql -o persons_with_common_id -v
SELECT * FROM persons JOIN persons_2 USING (id)
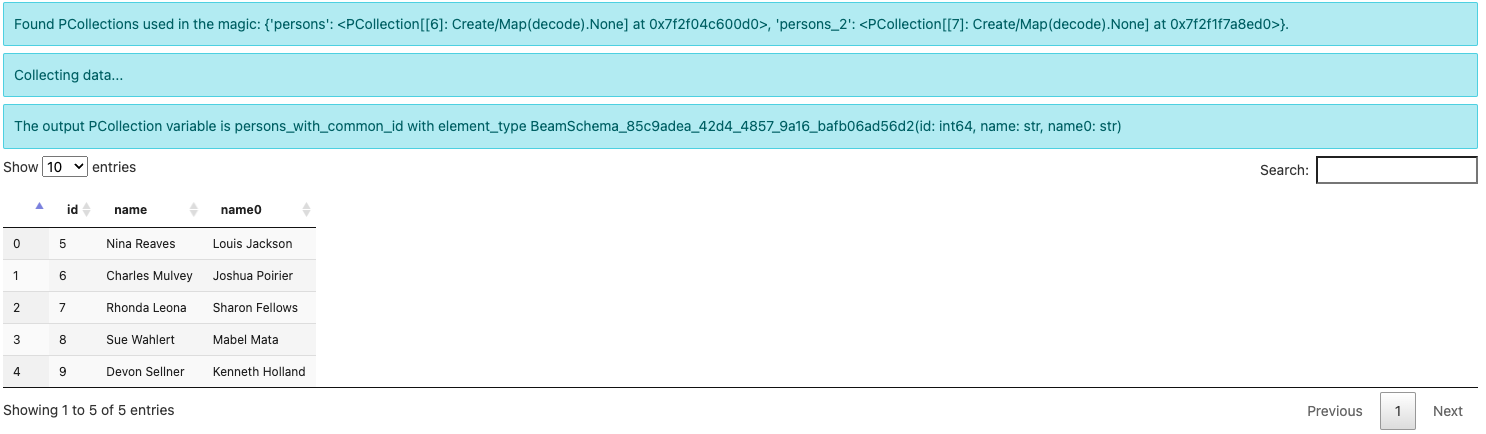
出力要素の型は、現在BeamSchema_...(id: int64, name: str, name0: str)です。これは、両方のPCollectionから列を選択したため、結果を保持するための既知のスキーマがないためです。Beamは自動的にスキーマを作成し、競合するフィールドnameを区別するために、片方に0を接尾辞として付加します。
PersonはすでにRowCoderで以前に登録されているため、-vオプションを使用しても登録に関する警告は表示されなくなります。
さらに、pcoll_in_file、persons、persons_2と結合することができます。
%%beam_sql -o entry_with_common_id
SELECT pcoll_in_file.id, persons.name AS name_1, persons_2.name AS name_2
FROM pcoll_in_file JOIN persons ON pcoll_in_file.id = persons.id
JOIN persons_2 ON pcoll_in_file.id = persons_2.id

生成されたスキーマは、SQLで実行した列の名前変更を反映しています。
例
COVID Tracking Projectが提供するデータを使用して、特定の日で最も多くのCOVID陽性症例がある米国の州を特定する例を見ていきましょう。
データを取得する
import json
import requests
# The covidtracking project has stopped collecting new data, current data ends on 2021-03-07
json_current='https://api.covidtracking.com/v1/states/current.json'
def get_json_data(url):
with requests.Session() as session:
data = json.loads(session.get(url).text)
return data
current_data = get_json_data(json_current)
current_data[0]

データは2021-03-07の日付です。米国におけるさまざまな州のCOVID症例に関する多くの詳細が含まれています。current_data[0]はデータポイントの1つにすぎません。
データのほとんどの列を削除できます。たとえば、「date」、「state」、「positive」、「negative」に焦点を当て、スキーマUsCovidDataを定義します。
from typing import Optional
class UsCovidData(NamedTuple):
partition_date: str # Remember to str(e['date']).
state: str
positive: int
negative: Optional[int]
注意:
dateは(Calcite)SQLのキーワードであるため、partition_dateなどの別のフィールド名を使用してください。- データからの
dateはstr型ではなく、int型です。str()を使用してデータを変換するか、date: intを使用するようにしてください。 negativeには欠損値があり、デフォルトはNoneです。したがって、negative: intの代わりにnegative: Optional[int]にする必要があります。または、スキーマを使用するときにNoneを0に変換できます。
次に、JSONデータをスキーマを使用してPCollectionに解析します。
p_sql = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_sql
| 'Create PCollection from json' >> beam.Create(current_data)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
positive=e['positive'],
negative=e['negative'])).with_output_types(UsCovidData))
ib.show(covid_data)

クエリ
「現在の日」(2021-03-07)に最大の陽性数を特定できます。
%%beam_sql -o max_positive
SELECT partition_date, MAX(positive) AS positive
FROM covid_data
GROUP BY partition_date

ただし、これは陽性数にすぎません。この最大数を持つ州や、その州の陰性症例数を観察することはできません。
結果を充実させるには、このデータを解析した元のデータセットに結合する必要があります。
%%beam_sql -o entry_with_max_positive
SELECT covid_data.partition_date, covid_data.state, covid_data.positive, {fn IFNULL(covid_data.negative, 0)} AS negative
FROM covid_data JOIN max_positive
USING (partition_date, positive)

これで、2021-03-07の最大陽性症例数を持つデータのすべての列を確認できます。注意:元のデータのnegative列の欠損値を処理するには、{fn IFNULL(covid_data.negative, 0)}を使用してnull値を0に設定できます。
スケールアップする準備ができたら、SQLをSqlTransformを使用したパイプラインに変換し、FlinkやSparkのような分散ランナーでパイプラインを実行できます。この投稿では、beam_sqlマジックを使用してノートブックからDataflowでワンショットジョブを起動することで、これを示します。
Dataflowで実行する
JSONから米国のCOVIDデータを解析して、毎日最も多くの陽性症例を持つ州の陽性/陰性/州情報を検索するパイプラインができたので、過去の毎日のすべてのデータに適用してDataflowで実行できます。
使用する新しいデータソースは、USAFacts US Coronavirus Databaseの公開データセットで、米国のCOVID症例の過去の毎日の要約がすべて含まれています。
データのスキーマは、COVID Tracking Project Webサイトが提供するデータと非常に似ています。クエリするフィールドは、date、state、confirmed_cases、deathsです。
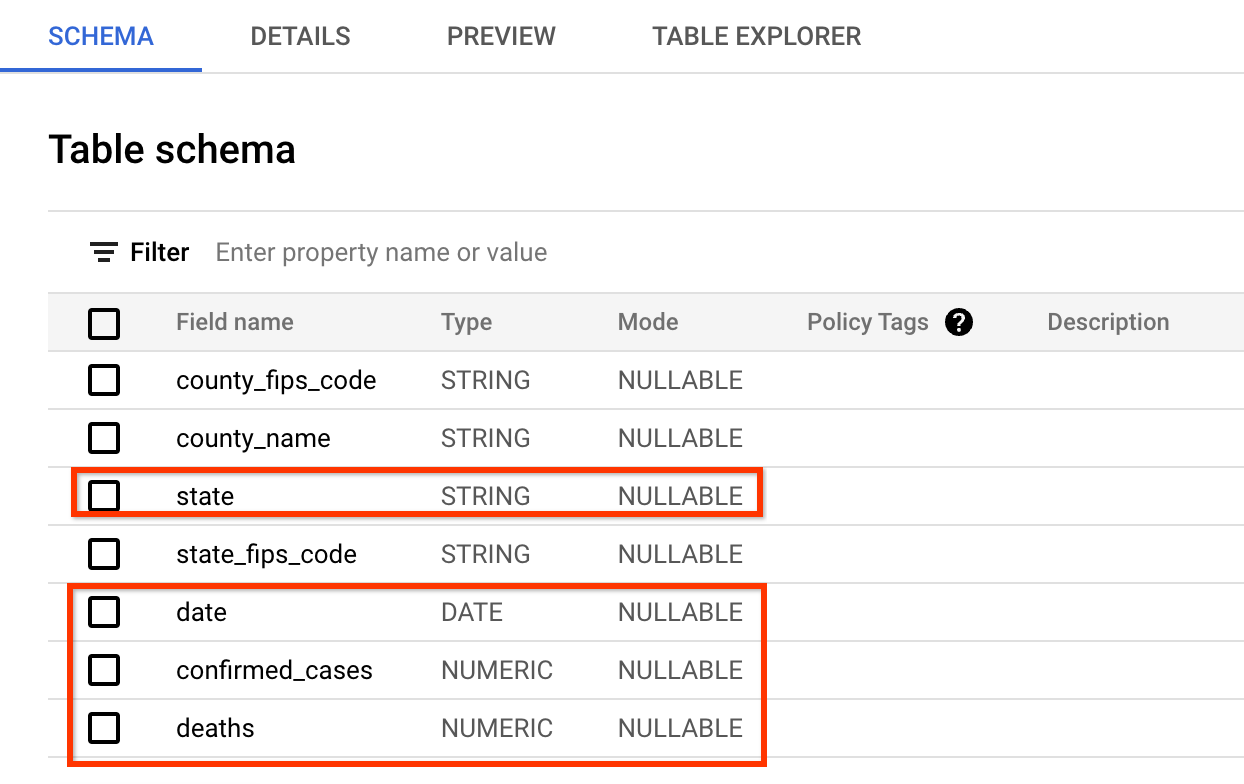
データのプレビューは次のようになります(BigQueryでの検査をスキップして、スクリーンショットを確認してください)。
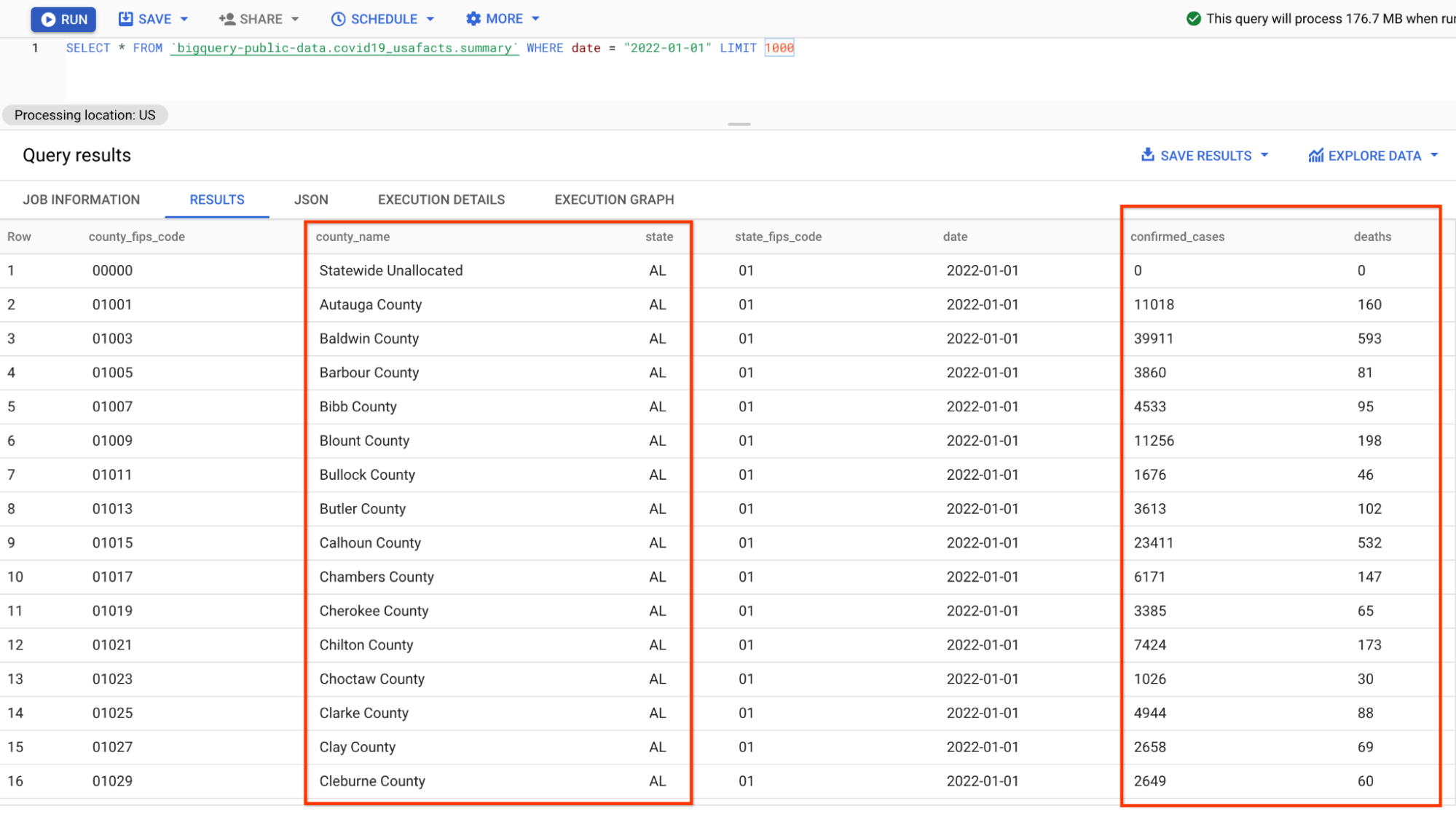
データの形式は、以前のパイプラインで解析したJSONデータとわずかに異なります。これは、数値が州ではなく郡でグループ化されているため、SQLでいくつかの追加の集計を行う必要があります。
新しい実行が必要な場合は、上部のメニューの「カーネルを再起動」ボタンをクリックしてください。
完全なコードは以下のとおりです。元のパイプラインとクエリの上にあります。
- ソースを単日のデータからより完全な履歴データに変更します。
- 新しいデータセットに対応するようにI/Oとスキーマを変更します。
- 新しいデータセットの形式に対応するために、より多くの集計を含めるようにSQLを変更します。
スキーマ付きでデータを準備する
from typing import NamedTuple
from typing import Optional
# Public BQ dataset.
table = 'bigquery-public-data:covid19_usafacts.summary'
# Replace with your project.
project = 'YOUR-PROJECT-NAME-HERE'
# Replace with your GCS bucket.
gcs_location = 'gs://YOUR_GCS_BUCKET_HERE'
class UsCovidData(NamedTuple):
partition_date: str
state: str
confirmed_cases: Optional[int]
deaths: Optional[int]
p_on_dataflow = beam.Pipeline(runner=InteractiveRunner())
covid_data = (p_on_dataflow
| 'Read dataset' >> beam.io.ReadFromBigQuery(
project=project, table=table, gcs_location=gcs_location)
| 'Parse' >> beam.Map(
lambda e: UsCovidData(
partition_date=str(e['date']),
state=e['state'],
confirmed_cases=int(e['confirmed_cases']),
deaths=int(e['deaths']))).with_output_types(UsCovidData))
Dataflowで実行する
DataflowでSQLを実行するには、オプション-r DataflowRunnerを追加するだけです。
%%beam_sql -o data_by_state -r DataflowRunner
SELECT partition_date, state, SUM(confirmed_cases) as confirmed_cases, SUM(deaths) as deaths
FROM covid_data
GROUP BY partition_date, state
以前のbeam_sqlマジックの実行とは異なり、結果はすぐには表示されません。代わりに、以下のようなフォームがノートブックセルの出力に印刷されます。

beam_sqlマジックは、プロジェクトIDと推奨されるクラウドリージョンを最善を尽くして推測しようとします。Dataflowジョブを送信するために必要な追加情報(DataflowジョブをステージングするためのGCSバケットや、ジョブに必要な追加のPython依存関係など)も入力する必要があります。
今のところ、セルの出力のフォームは無視してください。1)各日の最大確認症例数を検索する、2)最大症例データを完全なdata_by_stateと結合する、という2つのSQLがまだ必要です。beam_sqlマジックを使用すると、SQLをチェーンできるため、以下を実行してさらに2つチェーンします。
%%beam_sql -o max_cases -r DataflowRunner
SELECT partition_date, MAX(confirmed_cases) as confirmed_cases
FROM data_by_state
GROUP BY partition_date
そして
%%beam_sql -o data_with_max_cases -r DataflowRunner
SELECT data_by_state.partition_date, data_by_state.state, data_by_state.confirmed_cases, data_by_state.deaths
FROM data_by_state JOIN max_cases
USING (partition_date, confirmed_cases)
デフォルトでは、Dataflowでbeam_sqlを実行する場合、出力PCollectionはGCS上のテキストファイルに書き込まれます。「書き込み」はbeam_sqlによって自動的に提供され、主にこのワンショットDataflowジョブの出力データを検査するためのものです。軽量で、今後の開発のために要素をエンコードしません。出力を保存して他のユーザーと共有するには、さらにBeam I/Oを追加できます。
たとえば、上記のスキーマ対応PCollectionの例で説明した手法を使用して、要素をテキストファイルに適切にエンコードできます。
from apache_beam.options.pipeline_options import GoogleCloudOptions
coder = beam.coders.registry.get_coder(data_with_max_cases.element_type)
max_data_file = gcs_location + '/encoded_max_data'
data_with_max_cases | beam.io.textio.WriteToText(max_data_file, coder=coder)
さらに、独自のプロジェクトに新しいBQデータセットを作成して、処理されたデータを保存できます。
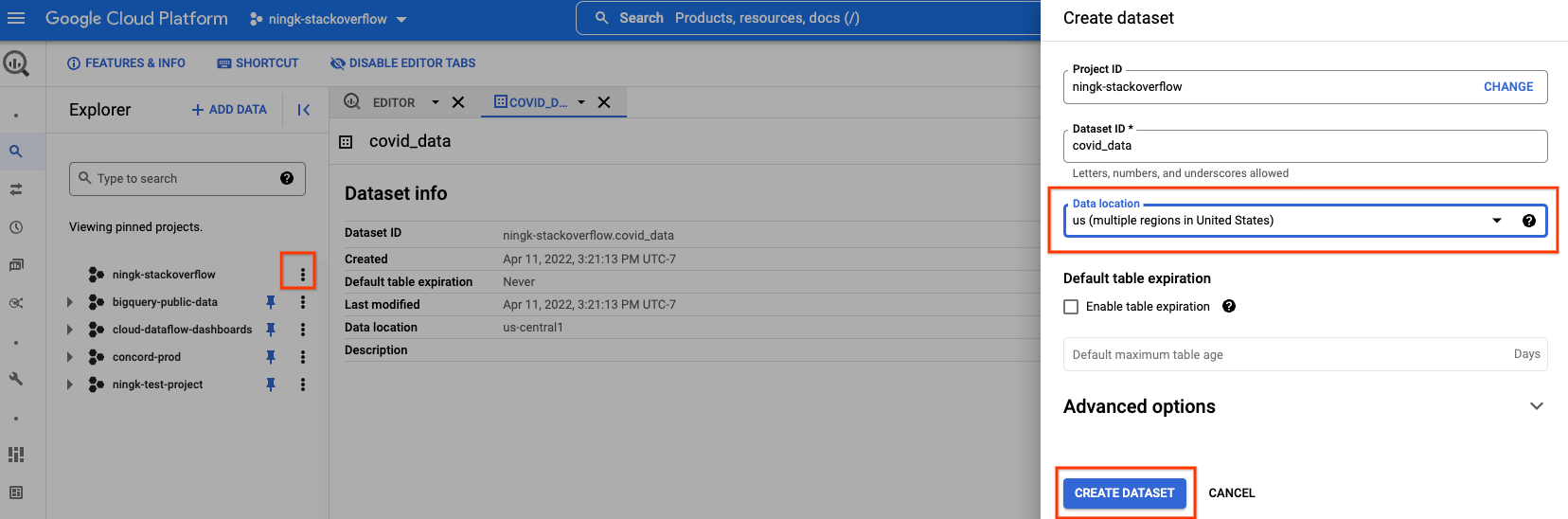
読み取る公開BigQueryデータと同じデータロケーション(この場合は「米国(米国内の複数の地域)」)を選択する必要があります。
空のデータセットの作成が完了したら、以下を実行できます。
output_table=f'{project}:covid_data.max_analysis'
bq_schema = {
'fields': [
{'name': 'partition_date', 'type': 'STRING'},
{'name': 'state', 'type': 'STRING'},
{'name': 'confirmed_cases', 'type': 'INTEGER'},
{'name': 'deaths', 'type': 'INTEGER'}]}
(data_with_max_cases
| 'To json-like' >> beam.Map(lambda x: {
'partition_date': x.partition_date,
'state': x.state,
'confirmed_cases': x.confirmed_cases,
'deaths': x.deaths})
| beam.io.WriteToBigQuery(
table=output_table,
schema=bq_schema,
method='STREAMING_INSERTS',
custom_gcs_temp_location=gcs_location))
前のSQLセル出力のフォームに戻り、Dataflowでパイプラインを実行するために必要な情報を入力します。入力例は次のようになります。
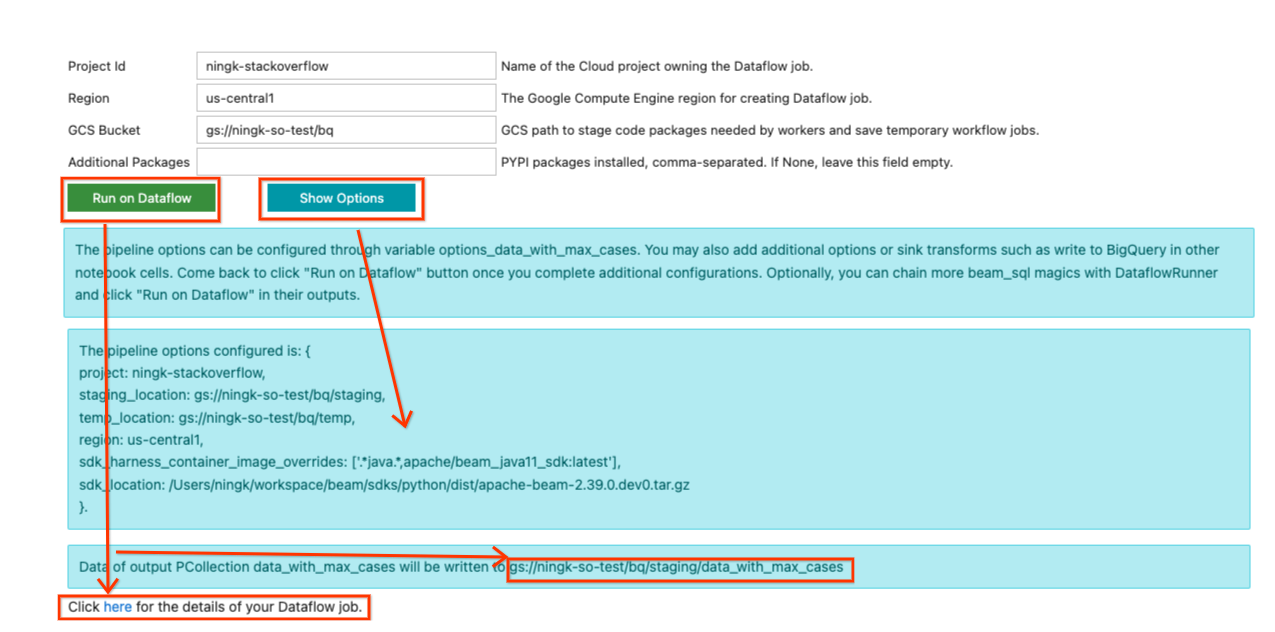
このパイプラインは追加のPython依存関係を使用しないため、「追加パッケージ」は空のままです。namesというパッケージをインストールした前の例では、Dataflowでそのパイプラインを実行するには、このフィールドにnamesを入力する必要があります。
入力の更新が完了したら、「オプションを表示」ボタンをクリックして、入力に基づいて構成されたパイプラインオプションを表示できます。変数options_[YOUR_OUTPUT_PCOLL_NAME]が生成され、フォームが実行に十分でない場合は、さらにパイプラインオプションを追加できます。
Dataflowジョブを送信する準備ができたら、「Dataflowで実行」ボタンをクリックします。デフォルトの出力が書き込まれる場所が表示され、しばらくすると、次の行が表示されます。
Dataflowジョブの詳細については、こちらをクリックしてください。
ハイパーリンクをクリックすると、Dataflowジョブページに移動できます。(オプションで、フォームを無視して、パイプラインを拡張するための開発を続行できます。パイプラインの状態に満足したら、フォームに戻ってジョブをDataflowに送信できます。)
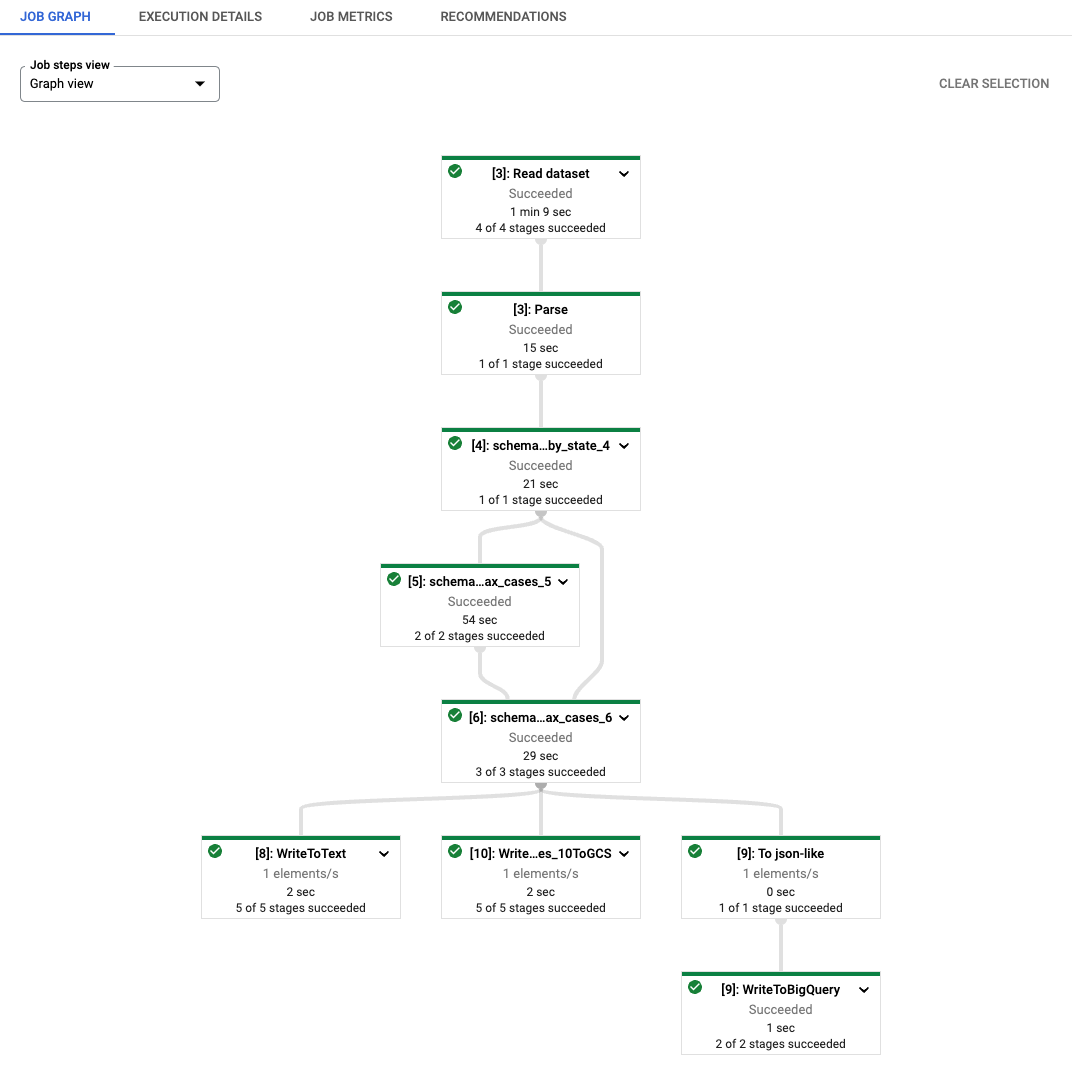
ご覧のとおり、生成されたDataflowジョブの各変換名は、文字列[number]: で始まるプレフィックスが付いています。これは、Beamでは各変換に異なる名前が必要なため、ノートブックで再実行されたコードを区別するためです。内部的には、beam_sqlマジックもスキーマ情報をDataflowにステージングするため、schema_loaded_beam_sql_…という名前の変換が表示される場合があります。これは、ノートブックで定義されたNamedTupleが__main__スコープにある可能性が高く、Dataflowはそれらをまったく認識していないためです。ユーザーの介入を最小限に抑え、メインセッション全体をピクルス化することを回避するため(また、ピクルス化できない属性が含まれている場合はメインセッションをピクルス化することは不可能です)、beam_sqlマジックはスキーマをシリアル化し、Dataflowにステージングしてから、ジョブ実行のために逆シリアル化/ロードすることにより、ステージングプロセスを最適化します。
ジョブが成功すると、出力PCollectionの結果は、I/O変換によって指示された場所に書き込まれます。注意:Dataflowでbeam_sqlを実行すると、ワンショットジョブが生成され、インタラクティブではありません。
デフォルトの出力場所からのデータの簡単な検査
!gsutil cat 'gs://ningk-so-test/bq/staging/data_with_max_cases*'

WriteToTextによって書き込まれたエンコードされたバイナリデータを含むテキストファイル
!gsutil cat 'gs://ningk-so-test/bq/encoded_max_data*'

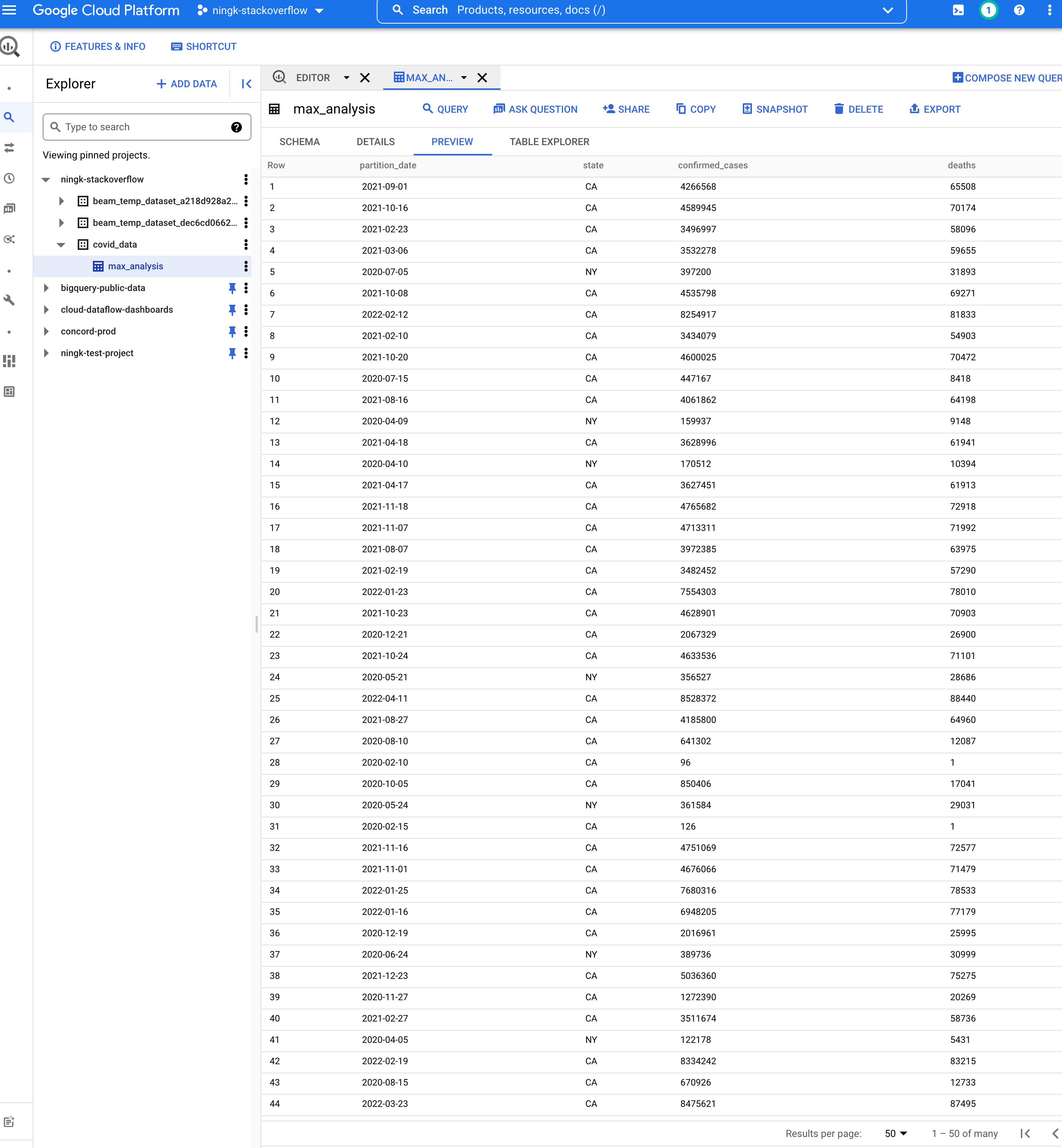
WriteToBigQueryによって作成されたテーブルYOUR-PROJECT:covid_data.max_analysis
beam_sqlマジックで他のOSSランナーで直接実行する
このブログが投稿された日には、beam_sqlマジックはDirectRunner(インタラクティブ)とDataflowRunner(ワンショット)のみをサポートしています。これは、ipywidgetsによって実装されたインタラクティブな入力ウィジェットを備えたSqlTransformの単純なラッパーです。手順に従って、独自のランナーサポートまたはユーティリティを実装できます。
さらに、他のOSSランナーのサポートはWIPです。たとえば、beam_sqlマジックでFlinkRunnerを使用するサポートなどです。
結論
beam_sqlマジックとApache Beam Notebooksの組み合わせは、最小限のセットアップでBeam SQLを学習し、Beam SQLをプロトタイピングや本番化(たとえば、Dataflowへの)Beamパイプラインに組み込むのに便利なツールです。
Beam SQL構文の詳細については、Beam Calcite SQLの互換性とApache Calcite SQLの構文を参照してください。