



ブログ
2018/01/09
Apache Beam:2017年を振り返る
2017年1月10日、Apache BeamはトップレベルのApacheソフトウェア財団プロジェクトに昇格しました。これは、プロジェクトの価値とコミュニティの正当性を検証し、普及の拡大を告げる重要なマイルストーンでした。昨年、Apache Beamは驚異的な成長軌道をたどり、コミュニティと機能セットが大幅に成長しました。注目すべき成果の一部をご紹介します。
ユースケース
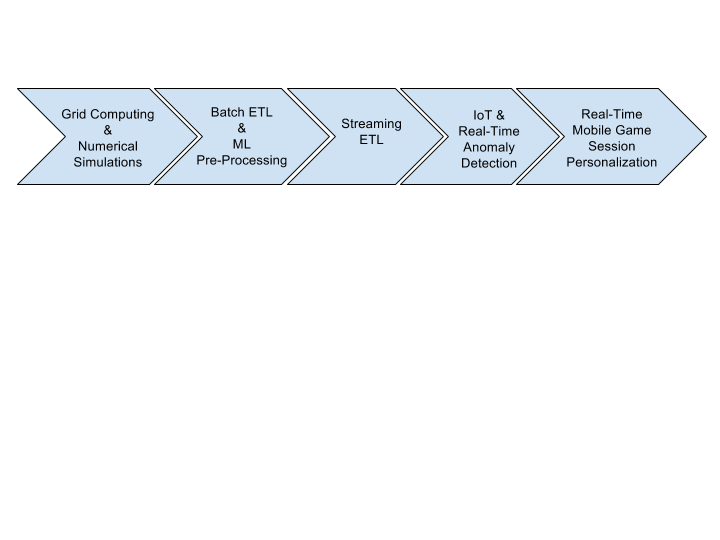
まず、2017年にBeamがどのように使用されたかを見てみましょう。Apache Beamはバッチ処理とストリーム処理のための統合フレームワークであり、非常に幅広いユースケースを可能にします。Beamの汎用性を示すユースケースをいくつかご紹介します。
コミュニティの成長
2017年、Apache Beamには世界中の多くの異なる組織から174人のコントリビューターがいました。Apacheプロジェクトとして、18人のPMCメンバーと31人のコミッターを擁していることを誇りに思います。コミュニティは2017年に7つのリリースを行い、それぞれが豊富な新機能と修正を提供しました。
Apache Beamコミュニティの成長と、移植性という中核的な価値提案の妥当性を示す最も明白で encouraging な兆候は、重要な新しいランナー(つまり実行エンジン)の追加です。私たちは2017年にApache Flink、Apache Spark 1.x、Google Cloud Dataflow、Apache Apex、そしてApache Gearpumpと共にスタートしました。2017年には、以下の新しいランナーと更新されたランナーが開発されました。
- Apache Spark 2.xアップデート
- IBM Streamsランナー
- MapReduceランナー
- JStormランナー
ランナーに加えて、Beamは新しいIOコネクタを追加しました。注目すべきものとしては、Cassandra、MQTT、AMQP、HBase/HCatalog、JDBC、Solr、Tika、Redis、Elasticsearchコネクタなどがあります。BeamのIOコネクタは、基盤となる実行エンジンでネイティブにサポートされていない場合でも、データソース/シンクからの読み取りまたは書き込みを可能にします。Beamは完全にプラグイン可能なファイルシステムサポートも提供しており、HDFS、S3、Azure Storage、Google Storageへのサポートとカバレッジの拡張を可能にします。Beamのユースケースを拡張するために、新しいIOコネクタとファイルシステムを追加し続けています。
オープンソースコミュニティの成熟度を特に示す兆候は、複数の他のオープンソースコミュニティと協力して、相互に最先端技術を向上させることができることです。過去数か月間、Beam、Calcite、Flinkのコミュニティは協力して、堅牢なストリーミングSQLの仕様を定義しました。4つ以上の組織のエンジニアが貢献しています。私たちと同じように、ストリーミングSQLの状態を改善するという見通しに興奮しているなら、ぜひご参加ください!
SQLに加えて、新しいXMLおよびJSONベースの宣言型DSLもPoCにあります。
継続的な革新
イノベーションは、あらゆるオープンソースプロジェクトの成功にとって重要であり、Beamは革新的な新しいアイデアをオープンソースコミュニティにもたらしてきた豊かな歴史を持っています。Apache Beamは、ビッグデータ処理の世界にいくつかの重要な概念を初めて導入しました。
- ユーザーが複数の異なるSDK / APIを学習することなくビッグデータジョブを作成できる、バッチ処理とストリーム処理の統合SDK。
- クロスエンジン移植性:オープンソースエンジンが時代遅れになり、新しいエンジンに取って代わられたときに、今日作成されたワークロードを書き直す必要がないという自信を企業に与えます。
- 無限の順序付けられていないデータについて推論し、ストリーミングジョブから一貫性のある正しい出力を得るために不可欠なセマンティクス。
2017年には、イノベーションのペースが続きました。以下の機能が導入されました。
- クロス言語移植性フレームワーク、およびGo SDKがそれで開発されました。
- 動的に分割可能なIO(SplittableDoFn)
- PCollectionでのスキーマのサポートにより、ランナーの機能を拡張できます。
- 機械学習などの新しいユースケースと新しいデータ形式に対応する拡張機能。
改善が必要な領域
プロジェクトの回顧的な見方は、改善が必要な領域を正直に評価しなければ不完全です。2つの側面が際立っています。
- ランナーがそれぞれの強みを紹介できるよう支援する。結局のところ、移植性は均質性を意味するものではありません。ランナーによって得意な分野が異なり、それぞれの強みを際立たせるために、より良い仕事をする必要があります。
- 前のポイントに基づいて、顧客がランナーを選択したり、あるランナーから別のランナーに移行したりする際に、より多くの情報に基づいた意思決定を行えるよう支援する。
2018年には、上記の側面を改善するための積極的な対策を講じることを目指しています。
プロジェクトとそのコミュニティの精神
今日のバッチ処理とストリームビッグデータ処理の世界は、バベルの塔の寓話を彷彿とさせます。異なるコミュニティが異なる言語を話していたため、進歩が遅くなりました。同様に、今日では複数の異なるビッグデータSDK / APIがあり、それぞれが同様の概念を記述するための独自の用語を持っています。副作用はユーザーの混乱と採用の遅延です。
Apache Beamプロジェクトは、業界標準のポータブルSDKを提供することを目指しており、
- 安定したイノベーションを提供することでユーザーに利益をもたらします。SDKとエンジンの分離により、ランナー間の健全な競争が可能になり、ユーザーが常に新しいSDK / APIを学習したり、新しいイノベーションの恩恵を受けるためにワークロードを書き直したりする必要がなくなります。
- すべての人にとってパイを大きくすることでビッグデータエンジンに利益をもたらします。ユーザーがビッグデータワークロードの作成、保守、アップグレード、移行を容易にすることで、本番環境でのビッグデータ展開の数が大幅に増加します。