



ブログ
2022/04/22
Google Cloud Dataflow を使用した Apache Hop のビジュアルパイプラインの実行
はじめに
Apache Hop (https://hop.apache.org/) は、Apache Beam を使用してデータパイプラインを作成するためのビジュアル開発環境です。Hop パイプラインは、Spark、Flink、または Google Cloud Dataflow で実行できます。
この記事では、Hop のインストール方法と、Dataflow を使用してクラウドでサンプルパイプラインを実行する方法について説明します。この記事の手順に従うには、Google Cloud Platform にプロジェクトがあり、Google Cloud Storage バケットを作成(または既存のものを使用)し、Dataflow ジョブを実行するのに十分な権限を持っている必要があります。
Google Cloud プロジェクトの準備ができたら、Dataflow パイプラインをトリガーするためにGoogle Cloud SDK をインストールする必要があります。
また、Google Cloud SDK を使用してアカウントとプロジェクトを使用するように構成することを忘れないでください。
セットアップとローカルでの実行
Apache Hop はローカルアプリケーションとして実行するか、Docker コンテナからHop Web バージョンを使用できます。この記事に記載されている手順はローカルアプリケーションで機能します。これは、Hop がコンテナで実行されている場合、Cloud Dataflow の認証が異なるためです。残りの手順はすべて有効です。Hop の UI は、ローカルアプリとして実行する場合でも、Web バージョンで実行する場合でもまったく同じです。
次に、これらの手順に従って Apache Hop をダウンロードしてインストールします。
この記事では、2022 年 3 月 7 日にリリースされた apache-hop-client パッケージ、バージョン 1.2.0 のバイナリを使用しました。
Hop をインストールしたら、開始する準備ができました。
Zip ファイルには、いくつかのサンプルプロジェクトと、Dataflow およびその他のランナーのパイプライン実行構成が含まれているディレクトリ config が含まれています。
この例では、config/projects/samples/beam/pipelines/input-process-output.hpl にあるパイプラインを使用します。
Apache Hop を開くことから始めましょう。クライアントを解凍したディレクトリで、次を実行します。
./hop/hop-gui.sh
(Windows の場合は ./hop/hop-gui.bat)。
Hop に入ったら、パイプラインを開きましょう。
最初に、プロジェクト default からプロジェクト samples に切り替えます。ウィンドウの左上隅にある projects ボックスを見つけて、プロジェクト samples を選択します。
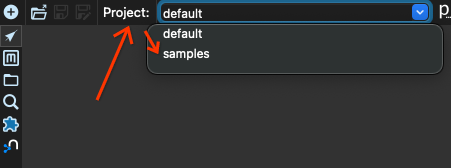
次に、開くボタンをクリックします。
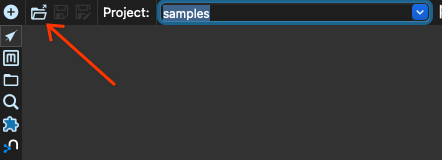
beam/pipelines サブディレクトリにあるパイプライン input-process-output.hpl を選択します。
Hop のメインウィンドウに次のようなグラフが表示されます。
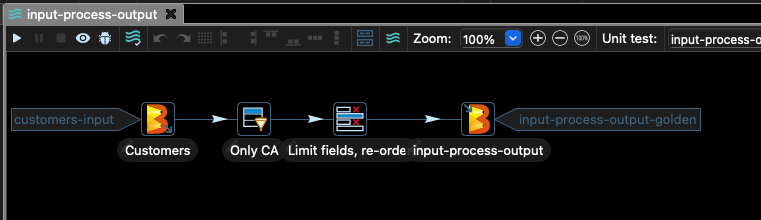
このパイプラインは、CSV ファイルから顧客データを取得し、列 stateCode が CA に等しいレコード以外のすべてをフィルタリングします。
次に、ファイルの列の一部のみを選択し、結果を Google Cloud Storage に書き込みます。
Dataflow に送信する前に、パイプラインをローカルでテストすることをお勧めします。Apache Hop では、各変換の出力をプレビューできます。入力 Customers を見てみましょう。
Customers 入力変換をクリックし、変換を選択した後に開くダイアログボックスで「出力のプレビュー」をクリックします。
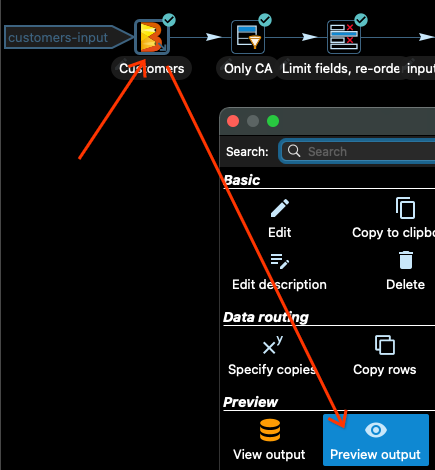
次に、「クイック起動」オプションを選択すると、入力データの一部が表示されます。

データの確認が完了したら、「停止」をクリックします。
Only CA 変換の直後にこのプロセスを繰り返すと、すべての行の stateCode 列が CA に等しくなっていることがわかります。
次の変換では、入力データの一部の列のみを選択し、列を並べ替えます。見てみましょう。変換をクリックし、「出力のプレビュー」をクリックします。
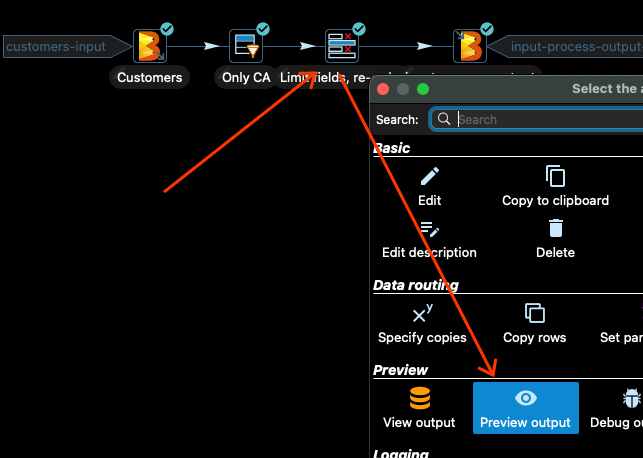
次に、再度「_クイック起動_」をクリックすると、次のような出力が表示されます。
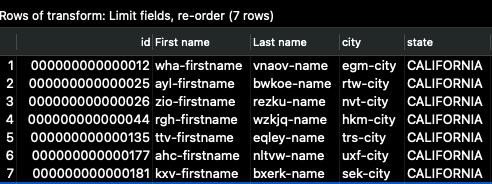
列 id が最初になり、入力列のサブセットのみが表示されます。これは、パイプラインが完全な出力を書き込み終えた後のデータの表示です。
Beam Direct Runner の使用
パイプラインを実行しましょう。パイプラインを実行するには、ランナー構成を指定する必要があります。これは、Apache Hop の Metadata ツールを使用して行います。
samples プロジェクトには、すでにいくつかの構成が作成されています。

local 構成は、Hop を使用してパイプラインを実行するために使用される構成です。たとえば、これは、異なるステップの出力のプレビューを調べたときに使用した構成です。
Direct 構成は、Apache Beam のダイレクトランナーを使用します。どのような構成であるか調べてみましょう。「パイプライン実行構成」には、「メイン」と「変数」の 2 つのタブがあります。
ダイレクトランナーの場合、「メイン」タブには次のオプションがあります。

ワーカー設定の数を CPU の数に合わせて変更したり、パイプラインが多くのリソースを消費しないように 1 つに制限したりすることもできます。
「変数」タブには、パイプライン自体の構成パラメータ(ランナー用ではありません)があります。\
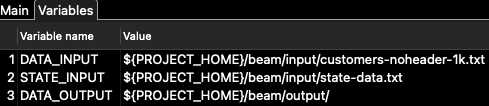
このパイプラインでは、DATA_INPUT と DATA_OUTPUT 変数のみが使用されます。STATE_INPUT は別の例で使用されます。
パイプラインの入力ノードと出力ノードにある Beam 変換に移動すると、これらの変数がそこでどのように使用されているかがわかります。

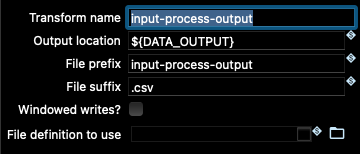
これらの変数は、サンプルプロジェクトフォルダ内のデータの場所を指すように正しく設定されているため、Beam Direct Runner を使用してパイプラインを実行してみましょう。
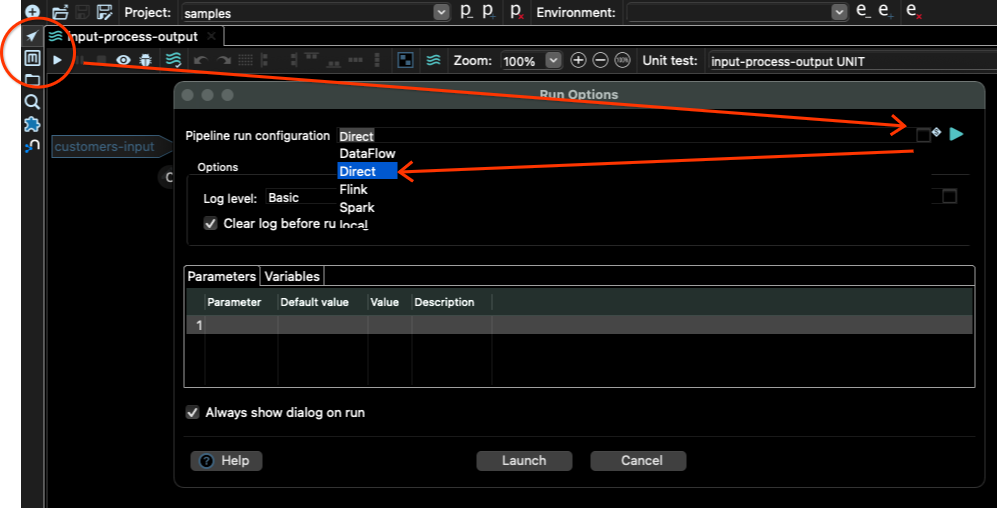
そのためには、パイプラインビュー(Metadata ツールのすぐ上にある矢印ボタン)に戻り、実行ボタン(ツールバーの小さな「再生」ボタン)をクリックする必要があります。次に、「ダイレクト」パイプライン実行構成を選択し、「起動」ボタンをクリックします。
ジョブが完了したかどうかをどのように確認するのでしょうか?メインウィンドウの下部にあるログで確認できます。次のようなものが表示されます。
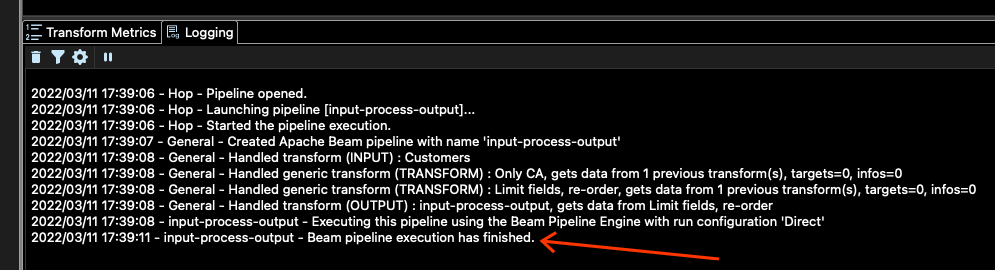
DATA_OUTPUT で設定された場所(この場合は config/projects/samples/beam/output)に移動すると、そこにいくつかの出力ファイルが表示されるはずです。私の場合は、次のファイルが表示されます。

ファイルの数は、実行構成で設定したワーカーの数によって異なります。
素晴らしい。パイプラインはローカルで動作します。クラウドで実行する時が来ました!
Dataflow を使用したクラウド規模での実行
Dataflow パイプライン実行構成を見てみましょう。メタデータツールに移動し、「パイプライン実行構成」に移動して、「Dataflow」を選択します。
ここにも「メイン」タブと「変数」タブがあります。両方でいくつかの値を変更する必要があります。まず、「変数」から始めましょう。「変数」タブをクリックすると、次の値が表示されます。

これらは、サンプルプロジェクトの作成者に属する Google Cloud Storage (GCS) の場所です。これらを独自の GCS バケットを指すように変更する必要があります。
Google Cloud でのプロジェクト設定
ただし、そのためにはバケットを作成する必要があります。次の手順では、gcloud (Google Cloud SDK) を構成済みであり、認証を管理していることを確認する必要があります。
再確認するには、コマンド gcloud config list を実行し、アカウントとプロジェクトが正しく表示されるかどうかを確認します。表示されている場合は、もう一度確認して gcloud auth login を実行します。これにより、認証プロセスを実行するために Web ブラウザでタブが開きます。完了すると、SDK を使用してプロジェクトと対話できます。
この例では、GCP のリージョン europe-west1 を使用します。そこにリージョナルバケットを作成しましょう。私の場合は、バケット名に ihr-apache-hop-blog という名前を使用しています。バケットに別の名前を選択してください!
gsutil mb -c regional -l europe-west1 gs://ihr-apache-hop-blog
次に、サンプルデータを GCS バケットにアップロードして、Dataflow でパイプラインがどのように実行されるかをテストしましょう。すべての hop ファイルがある同じディレクトリ(hop-gui.sh があるディレクトリと同じ)に移動し、データを GCS にコピーしましょう。
gsutil cp config/projects/samples/beam/input/customers-noheader-1k.txt gs://ihr-apache-hop-blog/data/
パスの最後のスラッシュ / に注意してください。これは、すべての内容を含む data という名前のディレクトリを作成することを示します。
データを正しくアップロードしたことを確認するために、その場所の内容を確認します。
gsutil ls gs://ihr-apache-hop-blog/data/
その場所にファイル customer-noheader-1k.txt が表示されるはずです。
続行する前に、Dataflow がプロジェクトで有効になっており、Hop で使用できるサービスアカウントが準備できていることを確認してください。Dataflow のドキュメントにある「始める前に 」セクションにある手順を確認して、Dataflow の API を有効にする方法を確認してください。
次に、Hop が Dataflow にアクセスするために必要な資格情報を使用できることを確認する必要があります。Hop のドキュメントには、サービスアカウントを作成し、そのサービスアカウントのキーをエクスポートし、GOOGLE_APPLICATION_CREDENTIALS 環境変数を設定することが推奨されています。これは、上記のリンクに記載されている方法でもあります。
サービスアカウントのキーのエクスポートは潜在的に危険であるため、Google Cloud SDK を利用して別の方法を使用します。次のコマンドを実行します。
gcloud auth application-default login
これにより、Webブラウザで認証の確認を求めるタブが開きます。確認が完了すると、システム内のGoogle Cloud Platformにアクセスする必要があるアプリケーションは、そのアクセスにこれらの認証情報を使用します。
また、Dataflowジョブ用に特定の権限を持つサービスアカウントを作成する必要があります。次のコマンドでサービスアカウントを作成します。
gcloud iam service-accounts create dataflow-hop-sa
次に、このサービスアカウントにDataflowの権限を付与します。
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/dataflow.worker"
さらに、Google Cloud Storageの追加の権限も付与する必要があります。
gcloud projects add-iam-policy-binding ihr-hop-playground \
--member="serviceAccount:dataflow-hop-sa@ihr-hop-playground.iam.gserviceaccount.com"\
--role="roles/storage.admin"
必ずプロジェクトID ihr-hop-playground を自分のプロジェクトIDに変更してください。
次に、ユーザーにそのサービスアカウントを偽装する権限を付与しましょう。そのためには、プロジェクトのGoogle Cloud Consoleのサービスアカウントに移動し、作成したばかりのサービスアカウントをクリックします。
[権限]タブをクリックし、次に[アクセス権を付与]ボタンをクリックします。
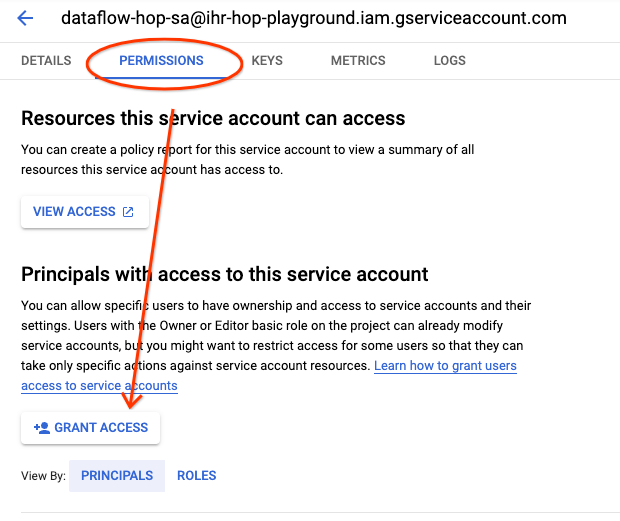
ユーザーにロール[サービスアカウント ユーザー]を付与します。
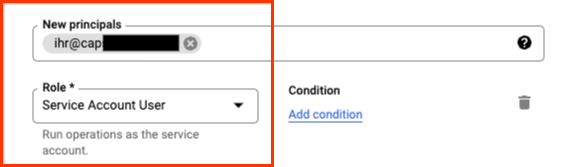
これで、そのサービスアカウントとユーザーでDataflowを実行できるようになりました。
パイプライン実行構成の更新
Dataflowでパイプラインを実行する前に、パイプラインコードのJARパッケージを生成する必要があります。そのためには、メニューバーの[ツール]メニューに移動し、[Hopのfat jarを生成]オプションを選択します。ダイアログで[OK]をクリックし、JARの保存場所とファイル名を選択して、[保存]をクリックします。
ファイルの生成には数分かかります。

Dataflowでパイプラインを実行する準備ができました。ほとんどの場合ですが。:)
パイプラインエディターに移動し、再生ボタンをクリックして、パイプライン実行構成として[DataFlow]を選択し、右側の再生ボタンをクリックします。
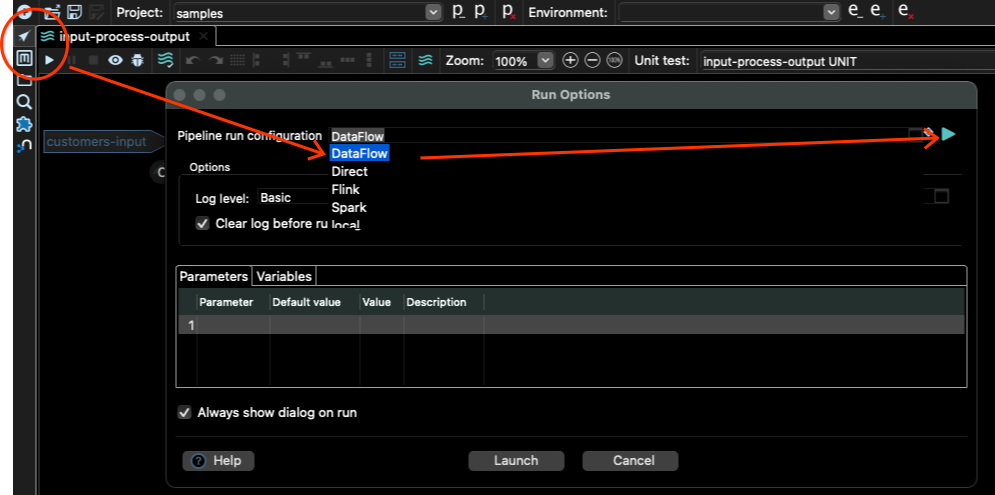
Dataflowパイプライン実行構成が開き、入力変数やその他のDataflowの設定を変更できます。
[変数]タブをクリックし、DATA_INPUTとDATA_OUTPUT変数のみを変更します。
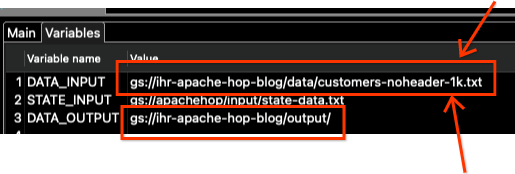
ファイル名も変更する必要があることに注意してください。
次に、[メイン]タブに移動します。変更する必要があるその他のオプションがいくつかあるためです。次の点を更新する必要があります。
- プロジェクトID
- サービスアカウント
- ステージング場所
- リージョン
- 一時的な場所
- Fat jarファイルの場所
プロジェクトIDには、(gcloud config listを実行したときに表示される)自分のプロジェクトIDを設定します。
サービスアカウントには、作成したサービスアカウントのアドレスを使用します。忘れてしまった場合は、Google Cloud Consoleのサービスアカウントで確認できます。
ステージング場所と一時的な場所には、作成したばかりの同じバケットを使用します。パス内のバケットアドレスを変更し、構成に既に設定されている「binaries」と「tmp」の場所はそのままにします。
リージョンについては、この例ではeurope-west1を使用しています。
また、ネットワーク構成によっては、「パブリックIPを使用しますか?」のチェックボックスをオンにするか、オフのままにして、プロジェクトのeurope-west1のリージョンサブネットワークでGoogle Private Accessを有効にすることができます(詳細については、プライベートGoogleアクセスを構成する | VPCを参照してください)。この例では、簡単にするためにチェックボックスをオンにします。
Fat jarの場所については、右側の[参照]ボタンを使用し、上記で生成したJARを探します。要約すると、私の[メイン]オプションは次のようになります(プロジェクトIDと場所は異なります)。
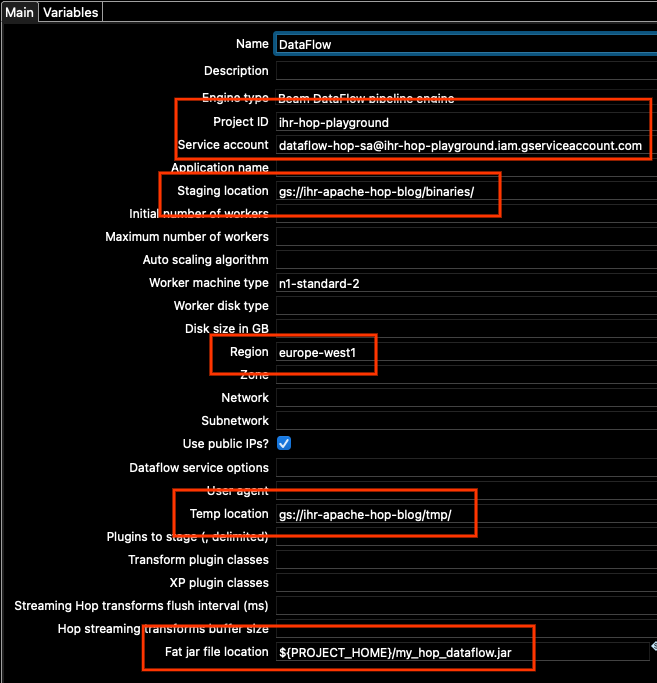
もちろん、プロジェクトに必要な特定の設定に応じて、他のオプションを変更することもできます。
準備ができたら、[OK]ボタンをクリックし、次に[起動]をクリックして、パイプラインをトリガーします。
ログウィンドウに、次のような行が表示されるはずです。

Dataflowでジョブを確認する
すべてがうまくいっていれば、https://console.cloud.google.com/dataflow/jobsでジョブが実行されているのが表示されるはずです。
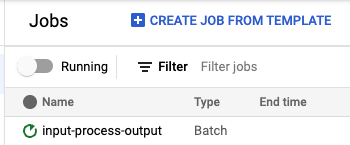
何らかの理由でジョブが失敗した場合は、失敗したジョブのページを開き、下部の[ログ]を確認し、エラーアイコンをクリックして、パイプラインが失敗した理由を見つけてください。通常は、構成で間違ったオプションを設定したことが原因です。
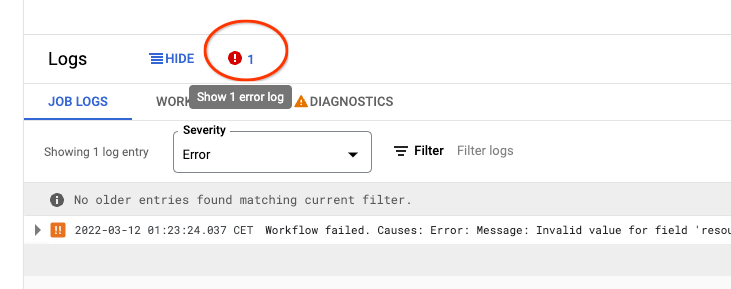
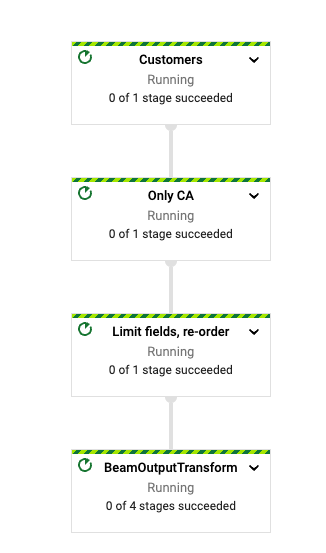
パイプラインの実行が開始されると、ジョブページにパイプラインのグラフが表示されるはずです。
ジョブが完了すると、出力場所にファイルが作成されるはずです。gsutilで確認できます。
% gsutil ls gs://ihr-apache-hop-blog/output
gs://ihr-apache-hop-blog/output/input-process-output-00000-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00001-of-00003.csv
gs://ihr-apache-hop-blog/output/input-process-output-00002-of-00003.csv
私の場合、ジョブによって3つのファイルが生成されましたが、実際の数は実行ごとに異なります。
これらのファイルの最初の行を見てみましょう。
gsutil cat "gs://ihr-apache-hop-blog/output/*csv"| head
12,wha-firstname,vnaov-name,egm-city,CALIFORNIA
25,ayl-firstname,bwkoe-name,rtw-city,CALIFORNIA
26,zio-firstname,rezku-name,nvt-city,CALIFORNIA
44,rgh-firstname,wzkjq-name,hkm-city,CALIFORNIA
135,ttv-firstname,eqley-name,trs-city,CALIFORNIA
177,ahc-firstname,nltvw-name,uxf-city,CALIFORNIA
181,kxv-firstname,bxerk-name,sek-city,CALIFORNIA
272,wpy-firstname,qxjcn-name,rew-city,CALIFORNIA
304,skq-firstname,cqapx-name,akw-city,CALIFORNIA
308,sfu-firstname,ibfdt-name,kqf-city,CALIFORNIA
すべての行にカリフォルニア州が州として含まれており、出力には選択した列のみが含まれ、ユーザーIDが最初の列であることがわかります。データが処理される順序は実行ごとに異なるため、実際に出力される結果は異なる場合があります。
このジョブは小さなデータサンプルで実行しましたが、任意の大きな入力CSVで同じジョブを実行することもできました。Dataflowはデータを並列化してチャンク単位で処理します。
結論
Apache Hopは、Beamパイプライン用の視覚的な開発環境であり、パイプラインをローカルで実行したり、データの検査、デバッグ、単体テストなどの多くの機能を使用したりできます。ローカルで実行したパイプラインに満足したら、Dataflowを使用するために必要なパラメータを設定するだけで、同じ視覚的なパイプラインをクラウドにデプロイできます。
Apache Hopの詳細については、Hopの作者によるBeam Summitでの講演を見逃さずに、入門ガイドをチェックしてください。