



ブログ
2024/02/05
舞台裏:高トラフィックのストリーミング環境における Apache Beam のための自動スケーラーの構築
Apache Beamジョブのための自動スケーラーの設計入門
BeamとFlinkを使用したスケーラブルで自己管理型のストリーミングインフラストラクチャの構築に関するブログシリーズの第3回目にして最終回へようこそ。前回の投稿では、4万件を超えるストリーミングジョブを管理し、1秒あたり1,000万件以上のイベントを処理する能力を強調し、ストリーミングプラットフォームの規模について詳しく説明しました。この驚異的な規模が、今日私たちが取り組む課題、つまり動的なストリーミング環境における複雑なリソース割り当てのタスクの舞台となります。
このブログ記事では、Talat Uyarer (アーキテクト / シニアプリンシパルエンジニア) と Rishabh Kedia (プリンシパルエンジニア) が、私たちの自動スケーラーの詳細について説明します。ストリーミングシステムが変動するワークロードで溢れかえっている状況を想像してみてください。私たちのケースは、グローバルに分散したファイアウォールを備えた顧客が、1日のさまざまな時間にログを生成するため、独自の課題を抱えています。これにより、ワークロードは時間によって変動するだけでなく、設定の変更やPANWの新しいサイバーセキュリティソリューションの追加により、時間の経過とともにエスカレートします。さらに、コードベースのアップデートでは、すべてのストリーミングジョブにわたって変更をロールアウトする必要があり、システムが未処理のデータを処理する際に一時的な需要の急増につながります。
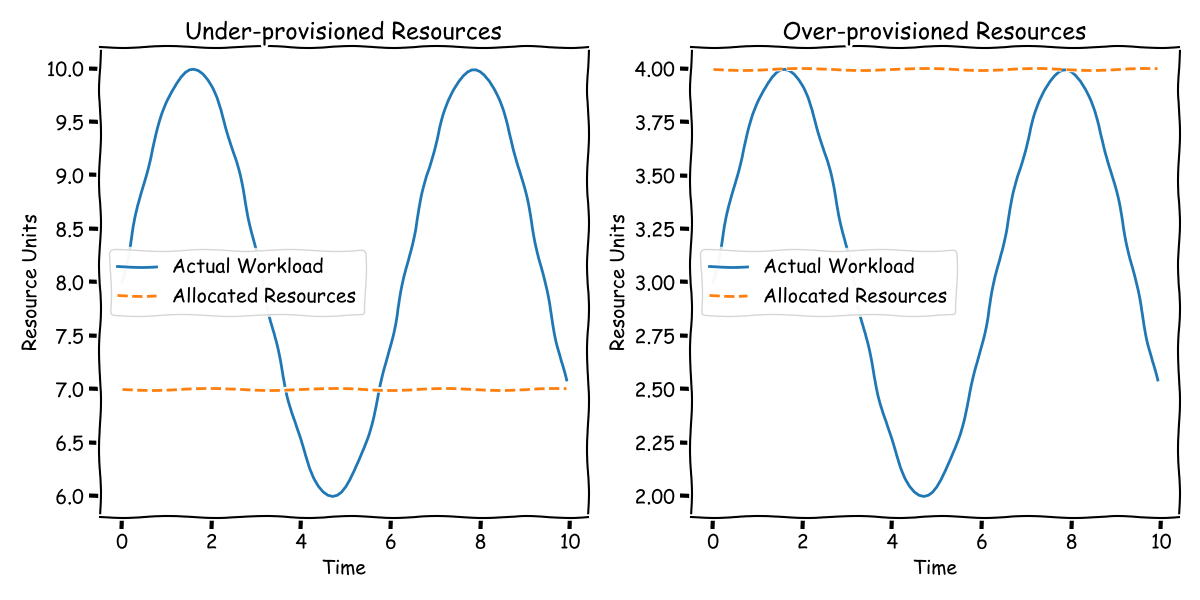
従来、この需要の増減を管理するには、手動で非効率なアプローチが必要でした。ピーク時の負荷に対応するためにリソースを過剰にプロビジョニングすると、オフピーク時にリソースが必然的に浪費されることになります。逆に、よりコストを意識した戦略では、ピーク時に遅延を受け入れ、後で追いつくことを期待する可能性があります。ただし、どちらの方法も、常に監視と手動調整が必要であり、決して理想的な状況ではありません。
Webフロントエンドの自動スケーリングが当たり前になっている現代において、ストリーミングインフラストラクチャにも同じレベルの効率性と自動化をもたらすことを目指しています。私たちの目標は、ストリーミング運用のワークロードの需要を動的に追跡し、調整できるシステムを開発することです。このブログ記事では、私たちの革新的なソリューションである、Apache Beamジョブ専用に設計された自動スケーラーをご紹介します。
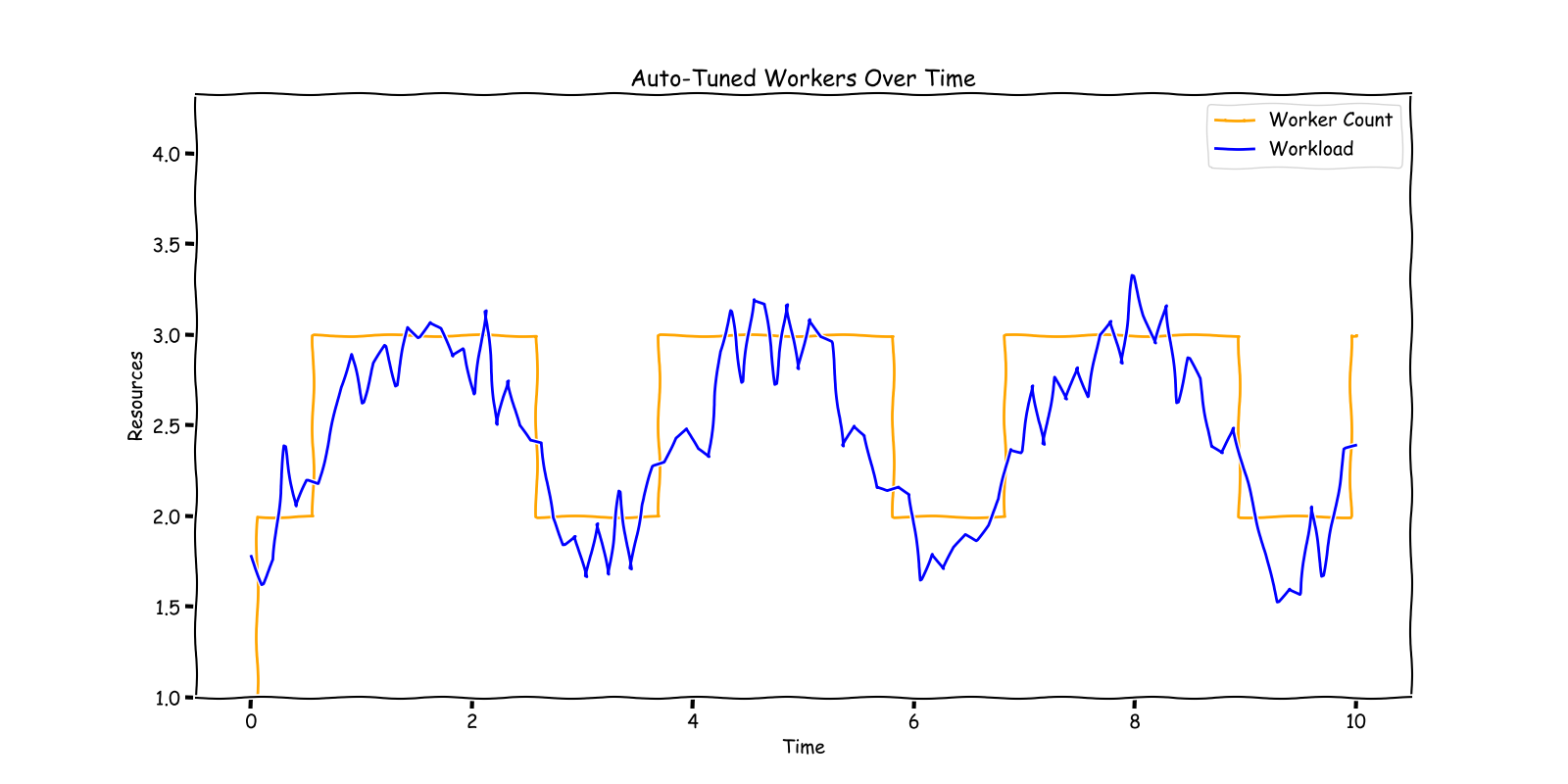
明確にするために、この文脈で「リソース」と言う場合、ストリーミングパイプラインを処理するFlinkタスクマネージャーまたはKubernetesポッドの数を意味します。これらのタスクマネージャーはCPUだけではなく、RAM、ネットワーク、ディスクI/O、その他の計算リソースも含まれます。
ただし、私たちのソリューションは、特定の仮定に基づいています。主に、大量のデータ量を処理する運用を対象としています。ワークロードに必要なタスクマネージャーが2つだけの場合、このシステムは最適ではない可能性があります。私たちの場合、10,000以上のワークロードがあり、それぞれワークロードが異なります。手動でのチューニングは選択肢ではありませんでした。また、データが均等に分散され、タスクマネージャーを追加することでスループットが向上することも前提としています。この前提は、効果的な水平スケーリングにとって非常に重要です。これらの前提に課題をもたらす可能性のある現実的な複雑さはありますが、この議論の範囲では、これらの条件が当てはまるシナリオに焦点を当てます。
効率性、適応性、そしてストリーミングインフラストラクチャの世界にインテリジェンスをもたらすように調整されたソリューションである、私たちの自動スケーラーの設計と機能について詳しく掘り下げていくので、ぜひご参加ください。
自動スケーリングのための適切なシグナルの特定
Flink上のApache Beamジョブのようなシステムを管理する場合、ワークロードとリソースの関係を理解するのに役立つ重要なシグナルを特定することが重要です。これらのシグナルは、私たちが遅れているか、リソースを浪費しているかを示す導きの光です。これらのシグナルを正確に特定することで、効果的なスケーリングポリシーを策定し、リアルタイムで変更を実装できます。100個から200個のタスクマネージャーに拡張する必要がある場合を想像してみてください。どのようにスムーズに移行するのでしょうか。そこでこれらのシグナルが登場します。
忘れないでください、私たちはあらゆるワークロードとパイプラインに適用できる普遍的なソリューションを目指しています。特定の問題は独自のシグナルから恩恵を受ける可能性がありますが、ここでの私たちの焦点は、すべてに対応できるアプローチを作成することです。
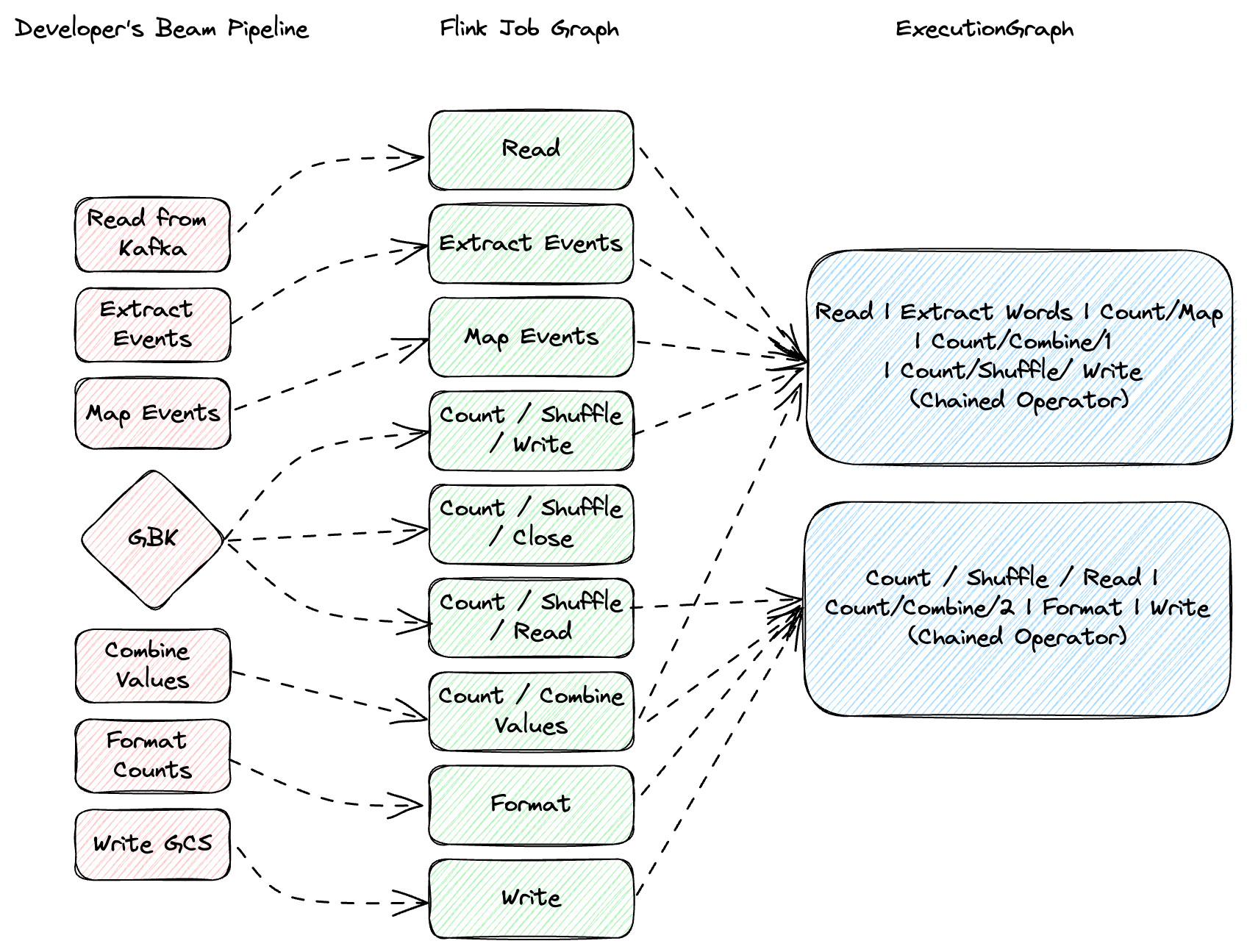
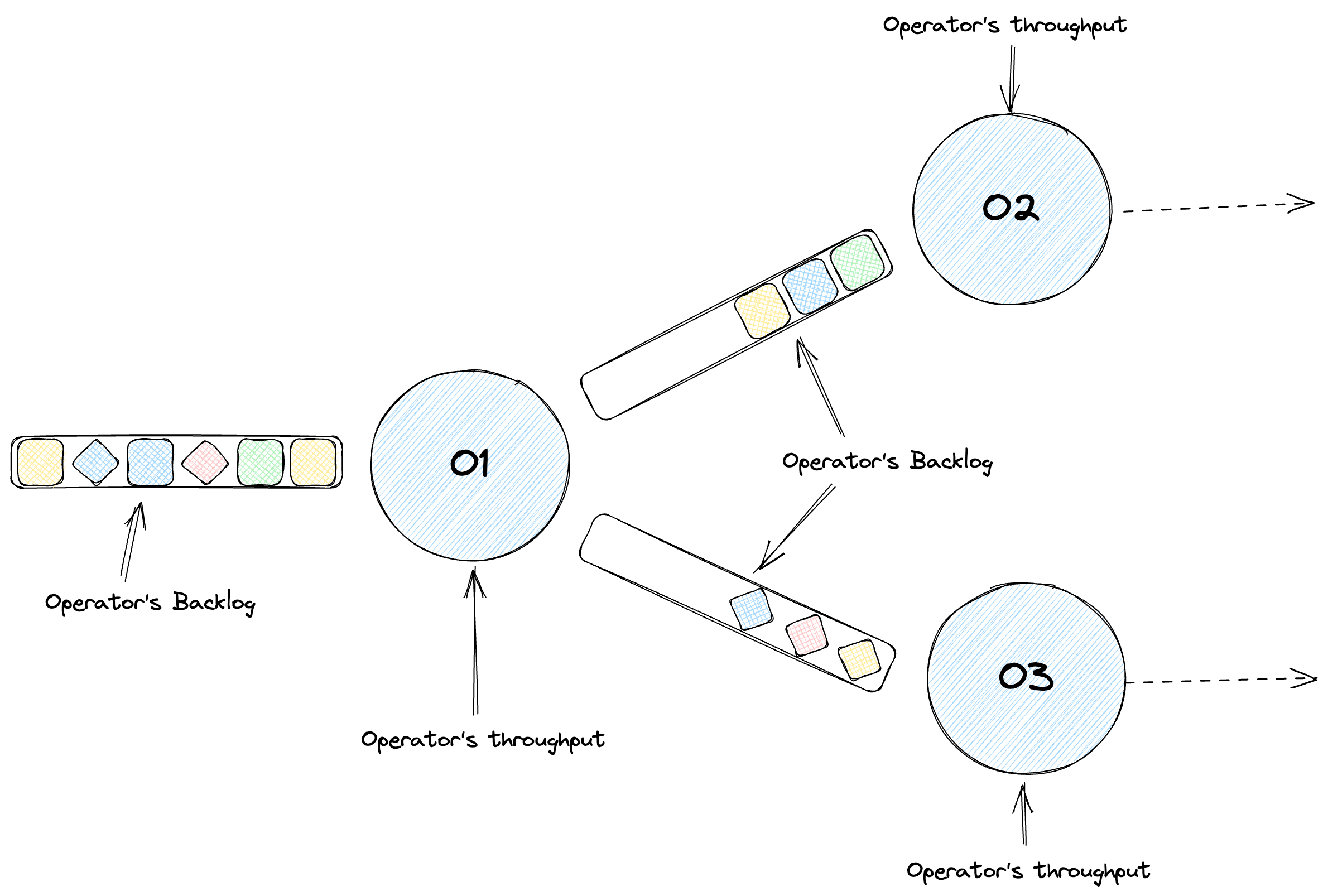
Flinkでは、タスクが基本的な実行単位を形成し、マップ、フィルター、リデュースなど、1つ以上の演算子で構成されます。Flinkは、可能な場合にこれらの演算子を単一のタスクにチェーン化することでパフォーマンスを最適化し、スレッドコンテキストの切り替えやネットワークI/Oなどのオーバーヘッドを最小限に抑えます。最適化されたパイプラインは、コードに基づいて要素を処理するステージの有向非巡回グラフになります。ステージを物理マシンと混同しないでください。これらは別々の概念です。私たちのジョブでは、Apache Beamのbacklog_bytesとbacklog_elementsメトリクスを使用して、バックログ情報を測定します。
アップスケーリングシグナル
バックログの増加
実際的な例を見てみましょう。Kafkaから読み取るパイプラインを考えてみましょう。ここでは、異なる演算子がデータの解析、フォーマット、および累積を処理します。ここでの重要なメトリックはスループットです。つまり、各演算子が時間経過とともに処理するデータ量です。しかし、スループットだけでは十分ではありません。各演算子のキューサイズまたはバックログを調べる必要があります。バックログが増加している場合は、遅れていることを示します。これをバックログの増加として測定します。つまり、時間経過に伴うバックログサイズの最初の導関数であり、処理の赤字を強調します。
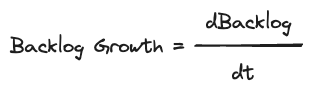
バックログ時間
これにより、バックログ時間に至ります。これは、バックログサイズとスループットを比較した派生メトリックです。新しいデータが到着しないと仮定した場合に、現在のバックログをクリアするのにかかる時間の尺度です。これにより、特定のサイズのバックログが、特定の処理ニーズとしきい値に基づいて、許容可能か問題があるかを判断するのに役立ちます。
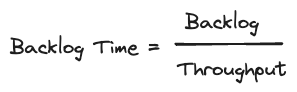
ダウンスケーリング:少ない方が良い場合
CPU使用率
ダウンスケーリングの重要なシグナルはCPU使用率です。CPU使用率が低い場合は、必要以上のリソースを使用していることを示唆しています。これを監視することで、パフォーマンスを損なうことなく効率的にスケールダウンできます。
シグナルの概要
まとめると、効果的な自動スケーリングのために特定したシグナルは次のとおりです。
- スループット:パフォーマンスのベースライン。
- バックログの増加:受信データに追いついているかどうかを示します。
- バックログ時間:バックログの重大度を理解するのに役立ちます。
- CPU使用率:リソース最適化をガイドします。
これらのシグナルは簡単に見えるかもしれませんが、その単純さが、スケーラブルでワークロードに依存しない自動スケーリングソリューションの鍵となります。
Flink上のApache Beamジョブの自動スケーリングポリシーの簡略化
Flink上で実行されているApache Beamジョブの世界では、いつスケールアップまたはスケールダウンするかを決定することは、忙しい厨房にいるシェフのようなものです。ワークロード、仮想マシン(VM)、およびそれらの相互作用など、いくつかの要素に目を光らせる必要があります。完璧なバランスを維持することが重要です。私たちの主な目標は何ですか?処理の遅延を回避し(バックログの増加がない)、既存のバックログが管理可能であることを確認し(短いバックログ時間)、リソース(CPUなど)を効率的に使用することです。
アップスケーリング:追いつき、追いつく
システムが一緒に働くシェフのチームのようなものだと想像してください。キッチンにもっとシェフを入れる(つまり、アップスケーリング)タイミングを決定する方法は次のとおりです。
追いつく:まず、現在のチームサイズ(VMの数)と処理量(スループット)を確認します。次に、受信した注文数(入力レート)に基づいてチームサイズを調整します。チームが現在の需要を処理できる大きさであることを確認することが重要です。
追いつく:場合によっては、注文のバックログがあるかもしれません。その場合、このバックログを目的の時間(60秒など)内にクリアするために必要な追加のシェフの数を決定します。このポリシーの一部は、迅速に軌道に戻るのに役立ちます。
スケーリングの例:実用的な視点
例を挙げて説明しましょう。最初は、処理能力(スループット)と一致する一定の注文の流れ(入力レート)があるため、バックログはありません。しかし、突然、注文が増加し、チームが遅れ始め、バックログが作成されます。これに対し、新しい注文レートに合わせてチームサイズを増やします。バックログはそれ以上増加しませんが、まだ存在します。最後に、チームにさらに数人のシェフを追加します。これにより、バックログを迅速にクリアし、新しいバランスの取れた状態に戻ることができます。
ダウンスケーリング:リソースを削減するタイミング
ダウンスケーリングは、ラッシュアワー後に一部のシェフが休憩できるタイミングを知っているようなものです。私たちは次の場合にこれを検討します。
- バックログが少ない場合 — 注文に追いついています。
- バックログが増加していない場合 — 受信した注文に追いついています。
- キッチン(CPU)が過度に稼働していない場合 — リソースを効率的に使用しています。
ダウンスケーリングとは、サービスの品質に影響を与えることなくリソースを削減することです。ラッシュアワーが終わったときに人員過剰にならないようにすることが重要です。
まとめ:効果的なスケーリングのレシピ
まとめると、私たちのスケーリングポリシーはスケールアップ用であり、最初にバックログを排出する時間がしきい値(120秒)を超えるか、CPUがしきい値(90%)を超えていることを確認します。
バックログの増加、つまりバックログの増加 > 0

一貫したバックログ、つまりバックログの増加 = 0

要約すると

スケールダウンするには、マシン使用率が低く(< 70%)、バックログの増加がなく、バックログを排出する現在の時間が制限時間(10秒)未満であることを確認する必要があります。
したがって、スケールダウン後に必要なリソースを計算する唯一の推進要因はCPUです。

自動スケーリングの決定の実行
私たちのセットアップでは、適応型スケジューラーと宣言型リソースマネージャーを使用するリアクティブモードを使用します。リソースをスロットに合わせることを目的としていました。ほとんどのFlinkドキュメントで推奨されているように、vCPUスロットごとに1つを設定しました。ほとんどのジョブでは、タスクマネージャーに1 vCPU 4GBメモリの組み合わせを使用しています。
適応型スケジューラーの独自の機能であるリアクティブモードは、アプリケーションモードで適用されるルールであるクラスターごとに1つのジョブの原則の下で動作します。このモードでは、ジョブはクラスター内のすべての利用可能なリソースを利用するように構成されています。タスクマネージャーを追加するとジョブのスケールが増加し、リソースを削除するとジョブのスケールが減少します。このセットアップでは、Flinkはジョブの並列処理を自律的に管理し、常に最大化します。
リスケーリングイベント中、リアクティブモードは最新のチェックポイントを使用してジョブを再起動します。これにより、手動でのジョブリスケーリングに必要なセーブポイントを作成する必要がなくなります。リスケーリング後に再処理されるデータ量は、チェックポイント間隔(私たちの場合10秒)の影響を受け、復元にかかる時間は状態のサイズによって異なります。
スケジューラーは、ジョブ内の各演算子の並列処理を決定します。この設定はユーザーが構成することはできず、個々の演算子またはジョブ全体に対して設定しようとしても無視されます。
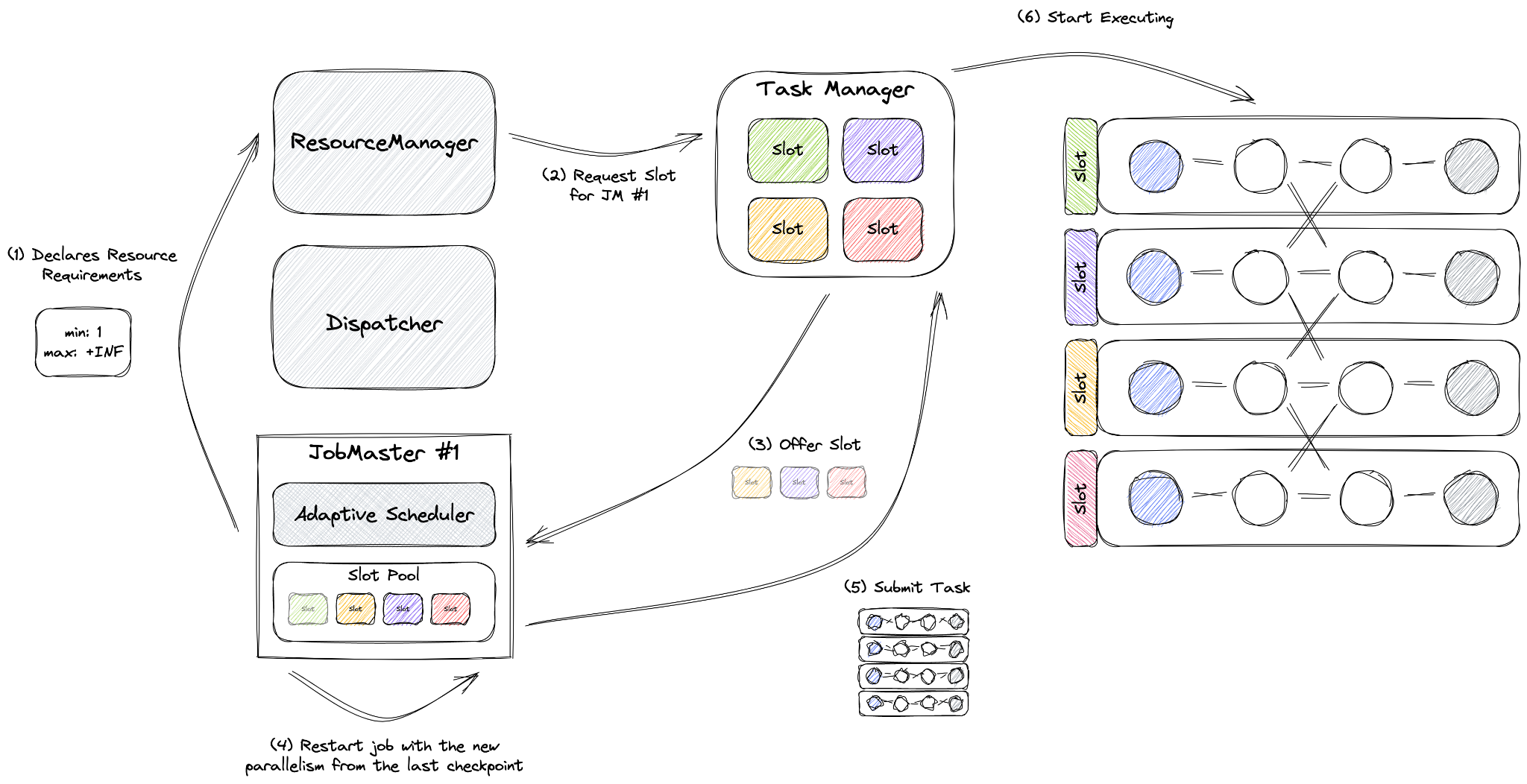
並列処理は、スケジューラが従うパイプラインの最大数を設定することによってのみ影響を与えることができます。当社の maxParallelism は、パイプラインが処理するパーティションの総数と、ジョブ自体によって制限されます。maxWorker カウントで TaskManager の最大数を制限し、maxParallelism を設定してシャッフルにおけるジョブのキー数を制御します。さらに、パイプラインごとの maxParallelism を設定して、パイプラインの並列処理を管理します。ジョブは、ワーカー数に関してジョブの maxParallelism を超えることはできません。
オートスケーラーの分析後、ジョブをスケールアップする必要があるか、アクションなし、またはスケールダウンする必要があるかをタグ付けします。ジョブと対話するために、Flink Kubernetes Operator をベースに構築したライブラリを使用します。このライブラリを使用すると、シンプルな Java メソッド呼び出しを介して Flink ジョブと対話できます。ライブラリは、メソッド呼び出しを Kubernetes コマンドに変換します。
Kubernetes の世界では、スケールアップの場合、呼び出しは次のようになります。
kubectl scale flinkdeployment job-name --replicas=100
Apache Flink がスケールアップに必要な残りの作業を処理します。
オートスケーリングによるステートフルストリーミングアプリケーションの状態の維持
オートスケーリングに対応するために Apache Flink の状態復旧メカニズムを適用するには、最大並列度、チェックポイント、およびアダプティブスケジューラなどの堅牢な機能を活用して、システムがさまざまな負荷に合わせて動的に調整される場合でも、効率的で耐障害性のあるストリーム処理を保証します。これらのコンポーネントがオートスケーリングのコンテキストでどのように連携するかを以下に示します。
- 最大並列度は、ジョブがスケールアウトできる上限を設定し、事前に定義された境界を超えることなく、より多いまたは少ないノード間で状態を再分配できるようにします。これは、ワークロードの変化に対応するためにタスクスロットの数が変化する場合でも、Flink が状態を効果的に管理できるようにするため、オートスケーリングにとって非常に重要です。
- チェックポイントは、Flink のフォールトトレランスメカニズムの中核であり、各ジョブの状態を耐久性のあるストレージ(この場合は GCS バケット)に定期的に保存します。オートスケーリングシナリオでは、チェックポイントにより、スケーリング操作後に Flink を一貫した状態に復旧させることができます。システムがスケールアウト(リソースの追加)またはスケールイン(リソースの削除)する場合、Flink はこれらのチェックポイントから状態を復元し、重要な情報を失うことなく、データの整合性と処理の継続性を保証できます。スケールダウンまたはスケールアップの状況では、最後のチェックポイントからデータを再処理する瞬間が発生する可能性があります。その量を減らすために、チェックポイントの間隔を 10 秒に短縮します。
- リアクティブモードは、アダプティブスケジューラ用の特別なモードであり、クラスターごとに単一のジョブを想定します(アプリケーションモードによって強制されます)。リアクティブモードは、ジョブが常にクラスターで使用可能なすべてのリソースを使用するように構成します。TaskManager を追加するとジョブがスケールアップし、リソースを削除するとスケールダウンします。Flink はジョブの並列処理を管理し、常に可能な限り高い値に設定します。ジョブがサイズ変更されると、リアクティブモードは、最新の成功したチェックポイントを使用して再起動をトリガーします。
結論
このブログシリーズでは、高トラフィックのストリーミング環境における Apache Beam 用のオートスケーラーの作成について深く掘り下げ、概念化から実装までの道のりを紹介しました。この取り組みは、動的なリソース割り当ての複雑さに取り組んだだけでなく、ストリーミングインフラストラクチャにおける効率と適応性の新しい基準を設定しました。インテリジェントなスケーリングポリシーと Apache Beam および Flink の堅牢な機能を組み合わせることで、リソースの使用を最適化し、さまざまな負荷の下でパフォーマンスを維持するスケーラブルなソリューションを紹介しました。このプロジェクトは、チームワーク、イノベーション、ストリーミングデータ処理に対する先進的なアプローチの力の証となります。このシリーズを締めくくるにあたり、すべての貢献者に感謝の意を表し、このテクノロジーの継続的な進化を楽しみにしています。コミュニティの皆様にも、さらなる議論と開発にご参加ください。
参考文献
[1] Google Cloud Dataflow でのストリーミングオートスケーリング https://www.infoq.com/presentations/google-cloud-dataflow/
[2] パイプラインのライフサイクル https://cloud.google.com/dataflow/docs/pipeline-lifecycle
[3] Flink エラスティック スケーリング https://nightlies.apache.org/flink/flink-docs-master/docs/deployment/elastic_scaling/
謝辞
これは、新しいインフラストラクチャを構築し、大規模な顧客ベースのアプリケーションをクラウドプロバイダーが管理するストリーミングインフラストラクチャから、大規模な自己管理型 Flink ベースのインフラストラクチャに移行する大きな取り組みです。この実現にご協力いただいた Palo Alto Networks CDL ストリーミングチーム(Kishore Pola、Andrew Park、Hemant Kumar、Manan Mangal、Helen Jiang、Mandy Wang、Praveen Kumar Pasupuleti、JM Teo、Rishabh Kedia、Talat Uyarer、Naitik Dani、David He)に感謝いたします。
詳細はこちら
- パート 1:Kubernetes 上で Apache Beam Flink サービスを構築および管理するための入門
- パート 2:Flink を使用したスケーラブルな自己管理型ストリーミングインフラストラクチャの構築:オートスケーリングの課題への取り組み - パート 2
コミュニティで会話に参加し、経験を共有するか、GitHubで進行中のプロジェクトに貢献してください。フィードバックは非常に貴重です。このシリーズに関するコメントや質問がある場合は、ユーザーメーリングリストを通じてお気軽にご連絡ください。
Apache Beam、Flink、および Kubernetes に関する最新情報については、引き続きお問い合わせください。