



ブログ
2023/12/18
BeamとFlinkを用いたスケーラブルなセルフマネージドストリーミングインフラストラクチャの構築:オートスケーリングの課題への取り組み - パート2
Flinkを用いたスケーラブルなセルフマネージドストリーミングインフラストラクチャの構築:オートスケーリングの課題への取り組み - パート2
Kubernetes上のApache Beam Flinkサービスの構築と管理に関する詳細シリーズのパート2へようこそ。このセグメントでは、オートスケーリングの実装中に遭遇した課題を詳しく見ていきます。これらの課題は単なる障害ではなく、システムを革新し強化する機会でした。これらの問題を分解し、そのコンテキストを理解し、開発したソリューションを探っていきましょう。
Flinkランナー環境におけるApache Beamバックログメトリクスの理解
課題:現在の設定では、Apache Flinkを使用してデータストリームを処理しています。しかし、不可解な問題に遭遇しました。FlinkジョブでApache Beamからのバックログメトリクスが表示されません。これらのメトリクスは、データパイプラインの状態とパフォーマンスを理解するために不可欠です。
発見したこと:興味深いことに、メトリクスは実際にはKafkaIOで生成されていることに気づきました。これはKafkaストリームを処理するデータパイプラインの一部です。しかし、Apache Flinkメトリクスシステムを通じてこれらのメトリクスを監視しようとすると、それらを見つけることができません。Apache BeamとApache Flinkの統合(または「配線」)に問題があるのではないかと疑いました。
詳細な調査:詳細に調査したところ、メトリクスはデータストリーム処理の「チェックポイント」フェーズ中に発行される必要があることがわかりました。この重要なステップでは、システムはストリームの状態のスナップショットを取得し、メトリクスは通常、無制限のソースに対して生成されるメトリクスです。無制限のソースとは、Kafkaのように継続的にデータをストリーミングするソースです。
潜在的な解決策:問題の根本原因は、チェックポイントフェーズでのメトリックコンテキストの設定方法にあると考えています。接続が切断されているため、BeamメトリクスがFlinkメトリクスシステムで適切にキャプチャされないようです。この問題に対する修正を提案しました。これは、GitHubのプルリクエストで確認し、貢献できます。Apache Beam PR #29793
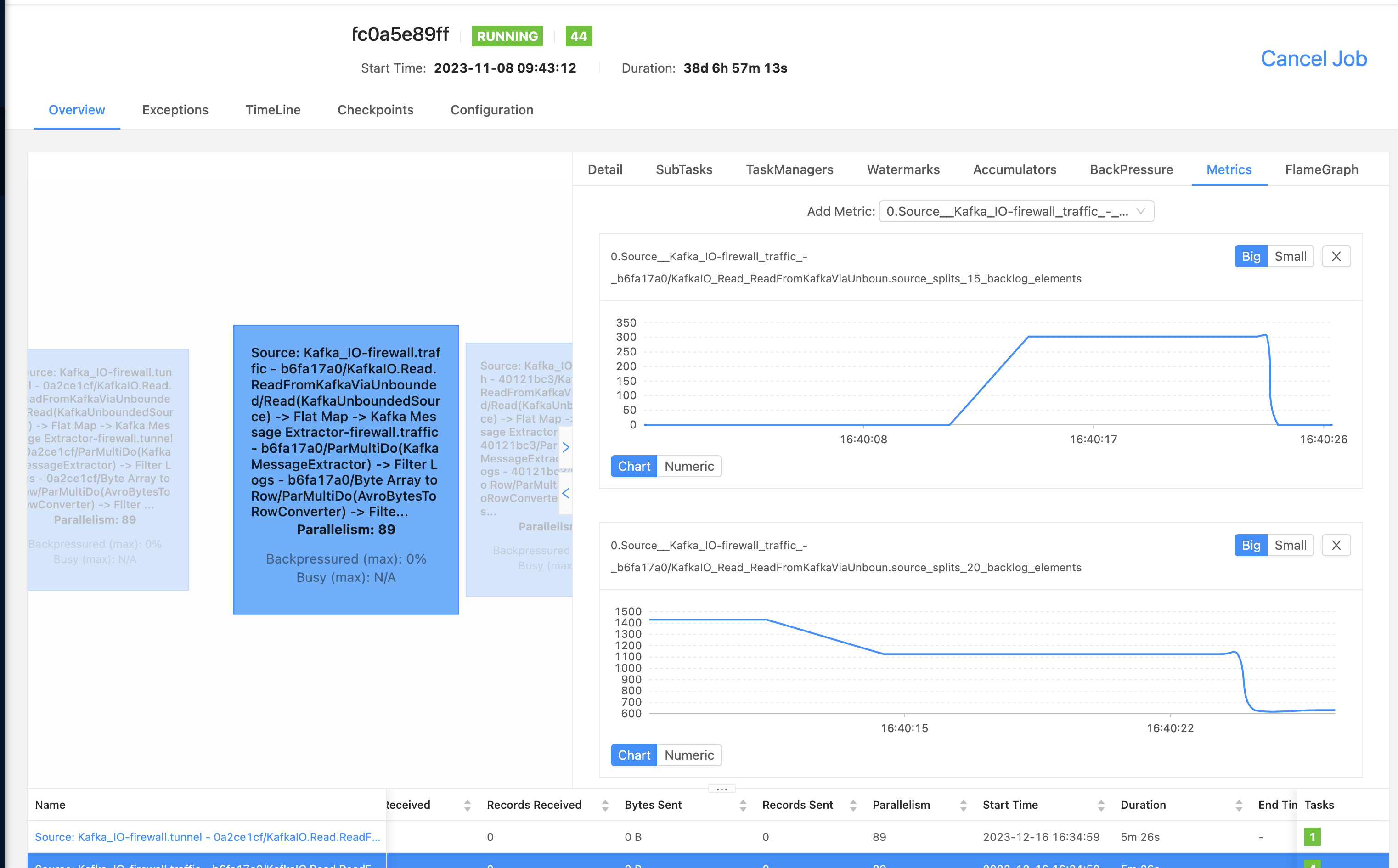
オートスケーリングBeamジョブのチェックポイントサイズ削減における課題の克服
このセクションでは、オートスケーリングApache Beamジョブにおけるチェックポイントサイズの削減戦略について説明します。Apache Flinkでの効率的なチェックポイントと、バンドルサイズとPipelineOptionsの最適化に焦点を当て、頻繁なチェックポイントタイムアウトと大規模ジョブの要件を管理します。
Apache Flinkにおけるチェックポイントの基本の理解
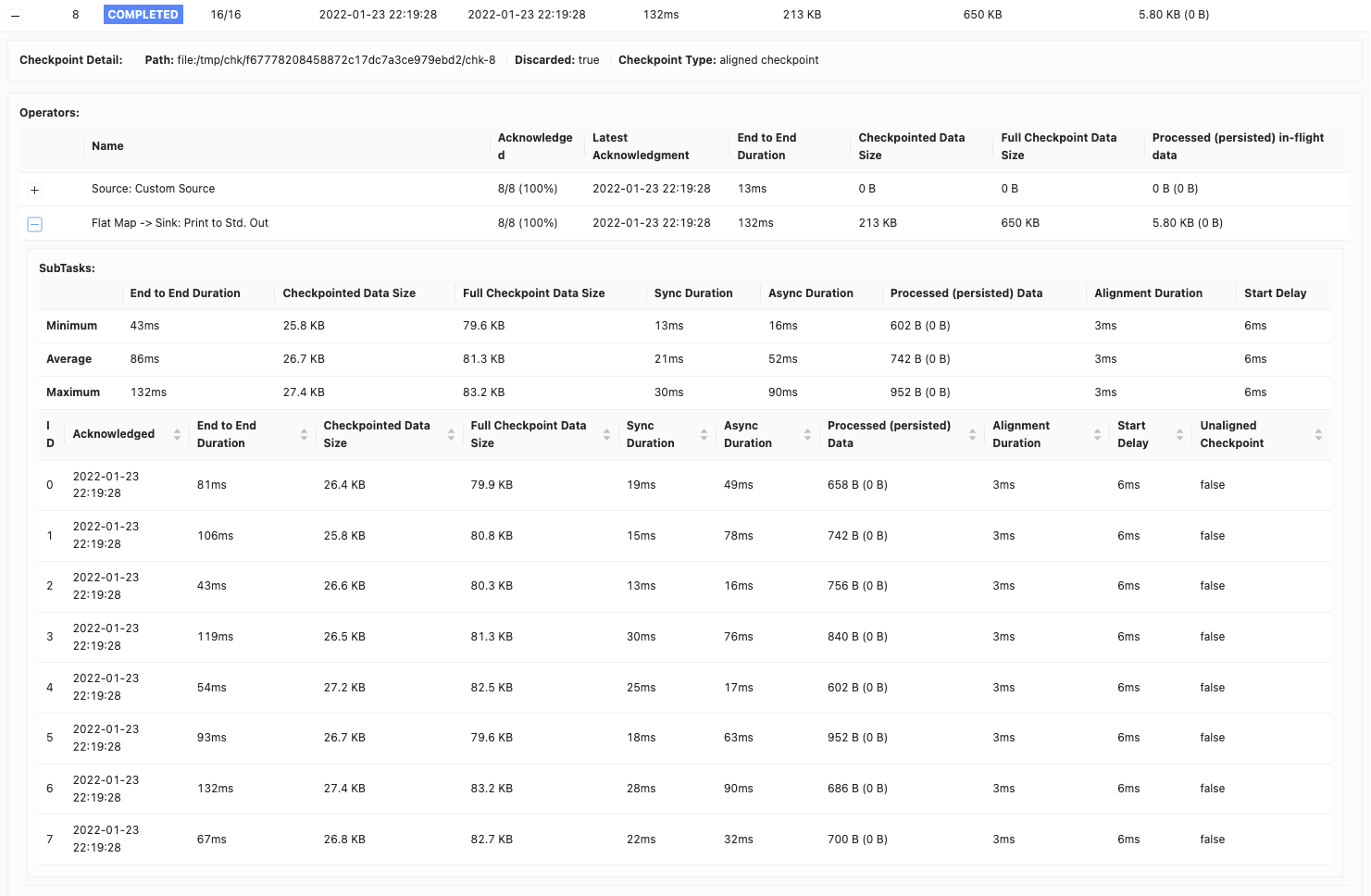
ストリーム処理では、状態の一貫性とフォールトトレランスを維持することが不可欠です。Apache Flinkは、チェックポイントと呼ばれるプロセスを通じてこれを実現します。チェックポイントでは、ジョブのオペレーターの状態を定期的にキャプチャし、Google Cloud StorageやAWS S3などの安定したストレージ場所に保存します。具体的には、Flinkは10秒ごとにジョブをチェックポイントし、このプロセスに最大1分間を許可します。このプロセスは、障害が発生した場合に、ジョブを最後のチェックポイントから再開し、正確に一度セマンティクスとフォールトトレランスを提供するために不可欠です。
Apache Beamにおけるバンドルの役割
Apache Beamは、バンドルという概念を導入しています。バンドルは基本的に、まとめて処理される要素のグループです。このステップにより、各要素を個別に処理するオーバーヘッドを削減することで、処理効率とスループットが向上します。詳細については、バンドリングと永続化を参照してください。Flinkランナーのデフォルト設定では、バンドルのデフォルトサイズは1000要素で、タイムアウトは1秒です。ただし、パフォーマンステストに基づいて、バンドルサイズを10,000要素でタイムアウトは10秒に調整しました。
課題:頻繁なチェックポイントタイムアウト
10秒ごとにチェックポイントを設定した場合、1分を超えることがよくある、頻繁なチェックポイントタイムアウトが発生しました。これは、チェックポイントのサイズが大きいためでした。
解決策:チェックポイントサイズの管理
Apache Beam Flinkジョブでは、finishBundleBeforeCheckpointingオプションが重要な役割を果たします。有効にすると、チェックポイントを開始する前にすべてのバンドルが完全に処理されるようになります。これにより、バンドル完了後の状態のみを含むチェックポイントが作成され、チェックポイントサイズが大幅に削減されます。当初、私たちのチェックポイントはパイプラインあたり約2MBでした。この変更により、一貫して150KBに減少しました。
大規模ジョブにおけるチェックポイントサイズへの対処
チェックポイントサイズを削減しても、10秒ごとの150KBのチェックポイントは、特に複数のパイプラインを実行するジョブでは依然として大きくなる可能性があります。たとえば、単一ジョブに100個のパイプラインがある場合、このサイズは10秒間隔あたり15MBに膨れ上がります。
さらなる最適化:PipelineOptionsによるチェックポイントサイズの削減
特定の問題(BEAM-8577)により、Flinkランナーが大きなPipelineOptionsオブジェクトをすべてのチェックポイントに含めていることがわかりました。この問題は、PipelineOptionsから不要なアプリケーション関連のオプションを削除することで解決し、チェックポイントサイズをパイプラインあたり10KBというより管理しやすいサイズにさらに削減しました。
Kafkaリーダーの待機時間:Beamジョブのオートスケーリングの課題の解決
非同期チェックポイントの理解
私たちのシステムでは、非同期チェックポイントを使用してチェックポイントのプロセスを高速化しています。これは、分散システムでのデータの一貫性を確保するために不可欠です。しかし、finishBundleBeforeCheckpointing機能を有効にしたところ、チェックポイントタイムアウトの問題とチェックポイントステップの遅延が発生し始めました。Apache Beamは、無制限のソースを処理するためにApache Flinkのレガシーソース実装を利用しています。Flinkでは、タスクはソースタスクと非ソースタスクの2つのタイプに分類されます。
- ソースタスク:外部システムからFlinkジョブにデータを取得します。
- 非ソースタスク:受信データを処理します。
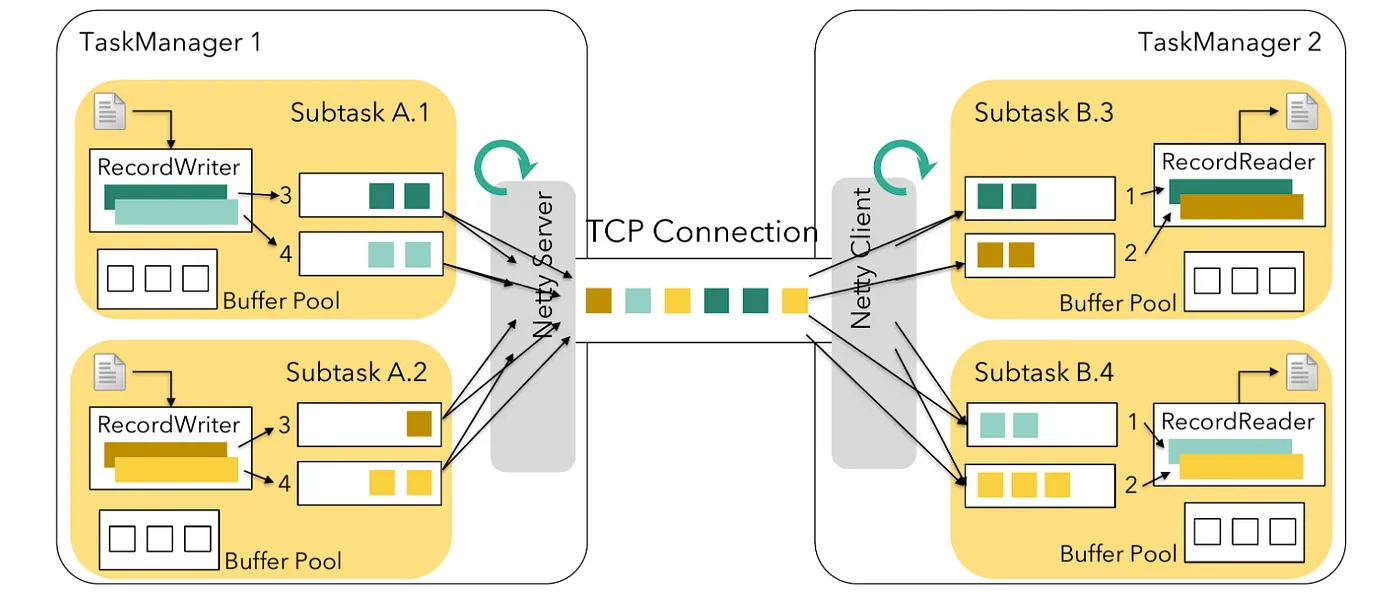
標準設定では、非ソースタスクはデータを取得する前に利用可能なバッファをチェックします。ソースタスクがこのチェックを実行しないと、出力バッファへのデータ書き込みにチェックポイントの遅延が発生する可能性があります。この遅延は、利用可能な出力バッファがある場合にのみレガシーソースタスクによって認識される非同期チェックポイントの効率に影響します。
BeamのUnboundedSourceWrapperによる課題への対処
この問題を解決するために、Apache Flinkはプルモードで動作する新しいソース実装を導入しました。このモードでは、タスクはデータを取得する前に空きバッファをチェックし、非ソースタスクのアプローチと一致させます。
しかし、Apache BeamのFlink Runnerでまだ使用されているレガシーソースは、プッシュモードで動作します。すぐにダウンストリームタスクにデータを送信します。この設定は、バッファがいっぱいになっている場合にボトルネックを作成し、非同期チェックポイントバリアの検出が遅れる可能性があります。
私たちの解決策
廃止予定にもかかわらず、Apache BeamのFlink Runnerはまだレガシーソース実装を使用しています。その問題に対処するために、FLINK-26759で提案された修正と迅速な回避策を実装しました。これらの機能強化は、プルリクエストに詳しく記載されています。Flink非同期チェックポイントのブログ投稿で、非同期チェックポイントの問題に関する詳細情報も見つけることができます。
高トラフィックシナリオでの遅い読み込みへの対処
Apache BeamとFlink Runnerを使用する中で、IntuitのAntonio SiによるApache BeamにおけるKafkaコンシューマラグのデバッグ方法の投稿で説明されているものと同様の大きな課題に遭遇しました。彼らのリアルタイムデータ処理パイプラインでは、特にメッセージトラフィックが多いトピックで、Kafkaコンシューマラグが増加していました。この問題は、UnboundedSourceWrapperとKafkaUnboundedReaderを通じてKafkaパーティションを処理するApache Beamの処理に起因していました。具体的には、トラフィックが少ないトピックの場合、処理スレッドが不必要に一時停止し、トラフィックが多いトピックの処理が遅れていました。私たちはシステムで同様の状況に直面し、トラフィックが多いトピックと少ないトピック間の処理速度の不均衡が非効率性を招いていました。
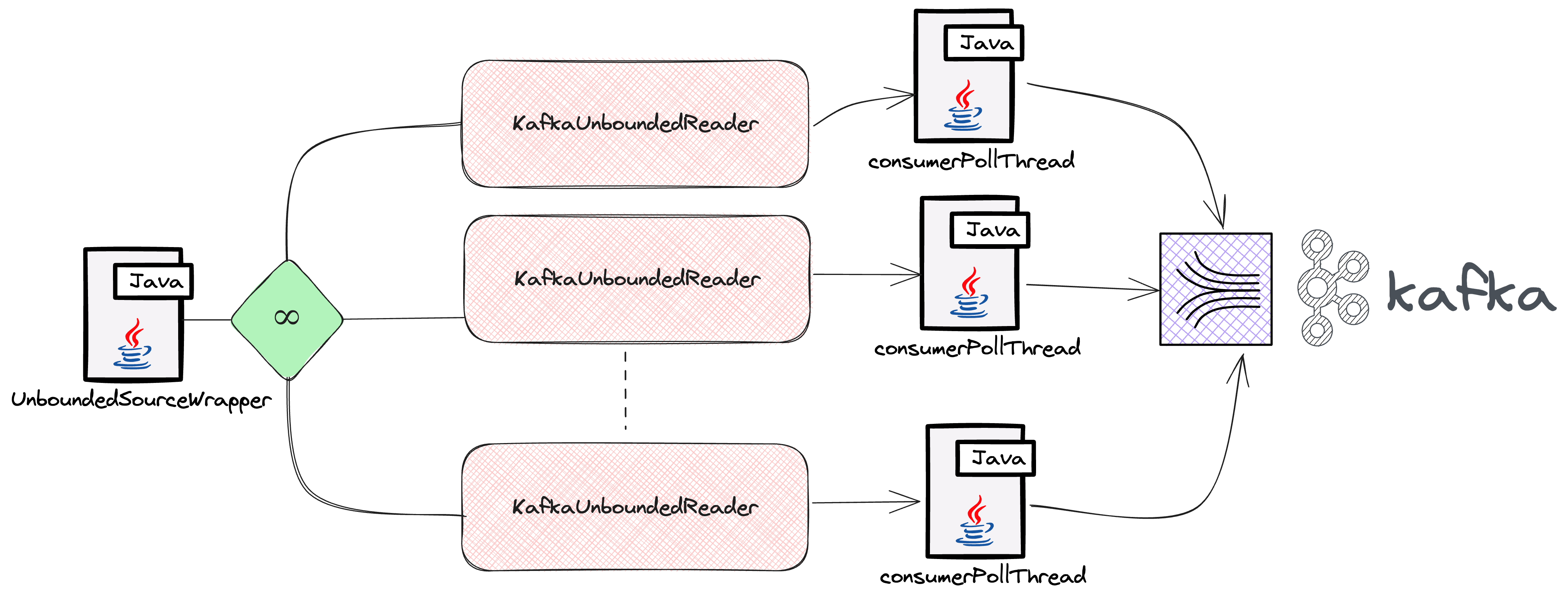
この問題を解決するために、革新的なソリューションを開発しました。KafkaIOのアダプティブタイムアウト戦略です。この戦略は、各トピックのトラフィックに基づいてタイムアウト期間を動的に調整します。トラフィックが少ないトピックでは、タイムアウトを短縮して不必要な遅延を防ぎます。トラフィックが多いトピックでは、タイムアウトを延長して、より多くの処理機会を提供します。このアプローチは、最近のプルリクエストに詳しく記載されています。
Beamジョブのオートスケーリングにおける不均衡なパーティション分散
このシステムの中核となるのは、アダプティブスケジューラです。これは、リソースの迅速な割り当てを目的として設計されたコンポーネントです。ジョブが実行する並列タスク数(並列度)を、コンピューティングスロットの可用性に基づいてインテリジェントに調整します。これらのスロットは、個々のワークステーションのようなもので、それぞれジョブの特定の部分を処理できます。
しかし、問題が発生しました。私たちのジョブは、それぞれ独自の資源セットを必要とする複数の独立したパイプラインで構成されています。当初、システムは最初のいくつかのワーカーに多くのタスクを割り当てることでそれらを過負荷にする傾向がありましたが、他のワーカーは未利用のままとなっていました。この問題は、Flinkがタスクを割り当てる方法、つまり各パイプラインの最初のワーカーを優先することに起因していました。

この問題に対処するために、タスクの分散を担当するFlinkのSlotSharingSlotAllocatorのカスタムパッチを開発しました。このパッチにより、すべての利用可能なワーカーにわたってよりバランスの取れたワークロード分散が確保され、効率が向上し、ボトルネックが防止されます。この改善により、各ワーカーはタスクを公平に共有し、Beamジョブのより良いリソース利用とスムーズな運用につながります。
FlinkによるKubernetes Operatorでのドレインサポート
課題
Apache Flinkを用いたデータ処理の世界において、一般的なタスクはデータ処理ジョブの管理と更新です。これらのジョブは、過去のデータを記憶するステートフルジョブと、記憶しないステートレスジョブのいずれかになります。
過去、Kubernetes Operatorで管理されるFlinkジョブを更新または削除する必要がある場合、システムはセーブポイントまたはチェックポイントを使用してジョブの現在の状態を保存していました。しかし、重要なステップが欠けていました。システムは新しいデータの処理をジョブに停止させていなかったのです(ジョブのドレインと呼んでいます)。この見落としは、2つの大きな問題につながる可能性がありました。
- ステートフルジョブの場合:ジョブがセーブポイントに考慮されていない新しいデータを処理する可能性があるため、データの不整合が発生する可能性があります。
- ステートレスジョブの場合:ジョブが既に処理したデータを再処理する可能性があるため、データの重複が発生する可能性があります。
解決策:ドレイン機能
ここで、FLINK-32700として参照される更新が必要になります。この更新により、ドレイン機能が導入されました。これは、ジョブに対して「現在処理中の作業を完了しますが、新しい作業は引き受けないでください」と指示するようなものです。その仕組みは以下のとおりです。
- 新しいデータの停止:ジョブは新しい入力の読み取りを停止します。
- ソースのマーク:ジョブは無限のウォーターマークでソースをマークします。このウォーターマークは、システムに処理する新しいデータがもうないことを伝えるマーカーと考えてください。
- パイプラインへの伝播:このマーカーはジョブの処理パイプラインを通過し、ジョブのすべての部分が新しいデータは期待できないことを確実にします。
この一見小さな変更は大きな影響を与えます。ジョブが更新または削除された場合、処理するデータの一貫性と正確性が維持されます。これは、データの整合性と信頼性を維持するため、あらゆるデータ処理タスクにとって非常に重要です。さらに、ドレインが失敗した場合、セーブポイントを必要とせずにジョブをキャンセルできるため、プロセス全体に柔軟性と安全性の層が追加されます。
結論
Kubernetes上のApache Beam Flinkサービスの構築と管理に関するシリーズの第2部を締めくくるにあたり、オートスケーリングの実装は、挑戦的で有益な道のりであったことは明らかです。Flinkランナー環境でのApache Beamバックログメトリクスの理解から、トラフィックの多いシナリオでの低速な読み込みへの対処まで、直面した障害は、革新的なソリューションの開発とストリーミングインフラストラクチャの理解を深める原動力となりました。
チェックポイント、Kafkaリーダーの待機時間、アンバランスなパーティション配分に関する詳細な調査により、Beamジョブのオートスケーリングの複雑さが明らかになりました。これらの課題に対処するために、`KafkaIO`の適応型タイムアウトや、Flinkの`SlotSharingSlotAllocator`におけるバランスの取れたワークロード配分などの戦略を考案しました。さらに、Flinkを搭載したKubernetes Operatorへのドレインサポートの導入は、ステートフルジョブとステートレスジョブを効果的に管理するための重要な進歩となります。
この取り組みは、システムの堅牢性と効率性を向上させただけでなく、Apache BeamとFlinkを使用するより広いコミュニティにも貴重な洞察を提供しました。私たちの経験と解決策が、同様の課題に直面している他の方々のプロジェクトに役立つことを願っています。
次回のブログ投稿では、Apache Beamのオートスケーリングの詳細について掘り下げます。Beamジョブを効果的にスケーリングするための概念、戦略、ベストプラクティスを解説します。このシリーズをフォローしていただきありがとうございます。今後の取り組みと学びを皆様と共有できるのを楽しみにしています。
謝辞
新しいインフラストラクチャを構築し、大規模な顧客ベースのアプリケーションをクラウドプロバイダーが管理するストリーミングインフラストラクチャから、自己管理型のFlinkベースのインフラストラクチャに大規模に移行するには、大きな努力が必要です。これを実現するために尽力してくれたPalo Alto Networks CDLストリーミングチームのKishore Pola、Andrew Park、Hemant Kumar、Manan Mangal、Helen Jiang、Mandy Wang、Praveen Kumar Pasupuleti、JM Teo、Rishabh Kedia、Talat Uyarer、Naitk Dani、David Heに感謝します。
詳細はこちら
コミュニティで経験を共有したり、GitHubで進行中のプロジェクトに貢献したりしてください。皆様からのフィードバックは非常に貴重です。このシリーズについてご意見やご質問がございましたら、ユーザーメーリングリストまでお気軽にお問い合わせください。
Apache Beam、Flink、Kubernetesに関する最新情報や洞察については、引き続きご注目ください。