



ブログ
2023/11/03
BeamとFlinkを用いたスケーラブルなセルフマネージドストリーミングインフラストラクチャの構築
このブログシリーズでは、タラット・ユヤレル(アーキテクト/シニアプリンシパルエンジニア)、リシャブ・ケディア(プリンシパルエンジニア)、およびデイビッド・ヘ(エンジニアリングディレクター)が、Apache BeamとFlinkを使用してセルフマネージドストリーミングプラットフォームを構築した方法について説明します。このシリーズでは、クラウド管理型ストリーミングサービスからの移行により、大規模なセルフマネージドストリーミングインフラストラクチャとサービスを構築した理由と方法について説明します。運用上のスケーラビリティと可観測性、パフォーマンス、費用対効果に関する教訓についても概説します。私たちの取り組みにおいて役立った技術をまとめます。
Flinkを用いたスケーラブルなセルフマネージドストリーミングインフラストラクチャの構築 - パート1
はじめに
Palo Alto Networks (PANW)は、サイバーセキュリティのリーダーであり、お客様に製品、サービス、ソリューションを提供しています。データは当社の製品およびサービスの中心です。ニアリアルタイムのデータ取り込み、データ変換、データストアへのデータ挿入、内部のMLベースのシステムおよび外部のSIEMへのデータ転送により、エクサバイト規模のデータをデータレイクにストリーミングおよび保存しています。各コンポーネントでマルチテナントをサポートすることで、テナントを分離し、最適なパフォーマンスとSLAを提供できます。ストリーミング処理はパイプラインで重要な役割を果たします。
このシリーズの第2部では、オートスケーラーなどのストリーミングインフラストラクチャの中核となる構成要素について、より詳細に説明します。また、高性能で、大規模なストリーミングシステムを構築するために有効だったカスタマイズについても詳しく説明します。最後に、私たちがどのように困難な問題を解決したかを説明します。
セルフマネージドストリーミングインフラストラクチャの重要性
Google Cloud上に大規模なデータプラットフォームを構築しました。マネージドストリーミングサービスとしてDataflowを使用しました。Dataflowでは、Apache Beamを使用してアプリケーションを実行するストリーミングエンジンと、Cloud LoggingやCloud Monitoringなどの可観測性ツールを使用しました。詳細については、[1]を参照してください。このシステムは、毎秒1500万件のイベント、1日1兆件のイベント、1日4ペタバイトのデータ量を処理できます。約3万件のDataflowジョブを実行しています。各ジョブには、顧客のイベントスループットに応じて、1つまたは数百のワーカーが含まれる場合があります。
さまざまなエンドポイントを使用して、さまざまなアプリケーションをサポートしています。BigQueryデータストア、HTTPSベースの外部SIEMまたは内部エンドポイント、SyslogベースのSIEM、Google Cloud Storageエンドポイントなどです。お客様と製品は、このデータプラットフォームに依存して、サイバーセキュリティの姿勢と対応を処理しています。ストリーミングインフラストラクチャは、ストリーミングジョブのサブスクリプションを通じて、ユースケースの追加、更新、削除を柔軟に行うことができます。たとえば、顧客がファイアウォールデバイスからのログイベントをKafkaトピックにバッファリングされたデータレイクに取り込みたいとします。ストリーミングジョブは、データの抽出とフィルタリング、データ形式の変換、リアルタイムでのBigQueryデータウェアハウスエンドポイントへのストリーミング挿入を行うためにサブスクライブされます。顧客は、このファイアウォールによってキャプチャされたトラフィックまたはスレッドを表示するために、当社の可視化およびダッシュボード製品を使用できます。次の図は、イベントプロデューサー、ユースケースサブスクリプションワークフロー、ストリーミングプラットフォームの主要コンポーネントを示しています。
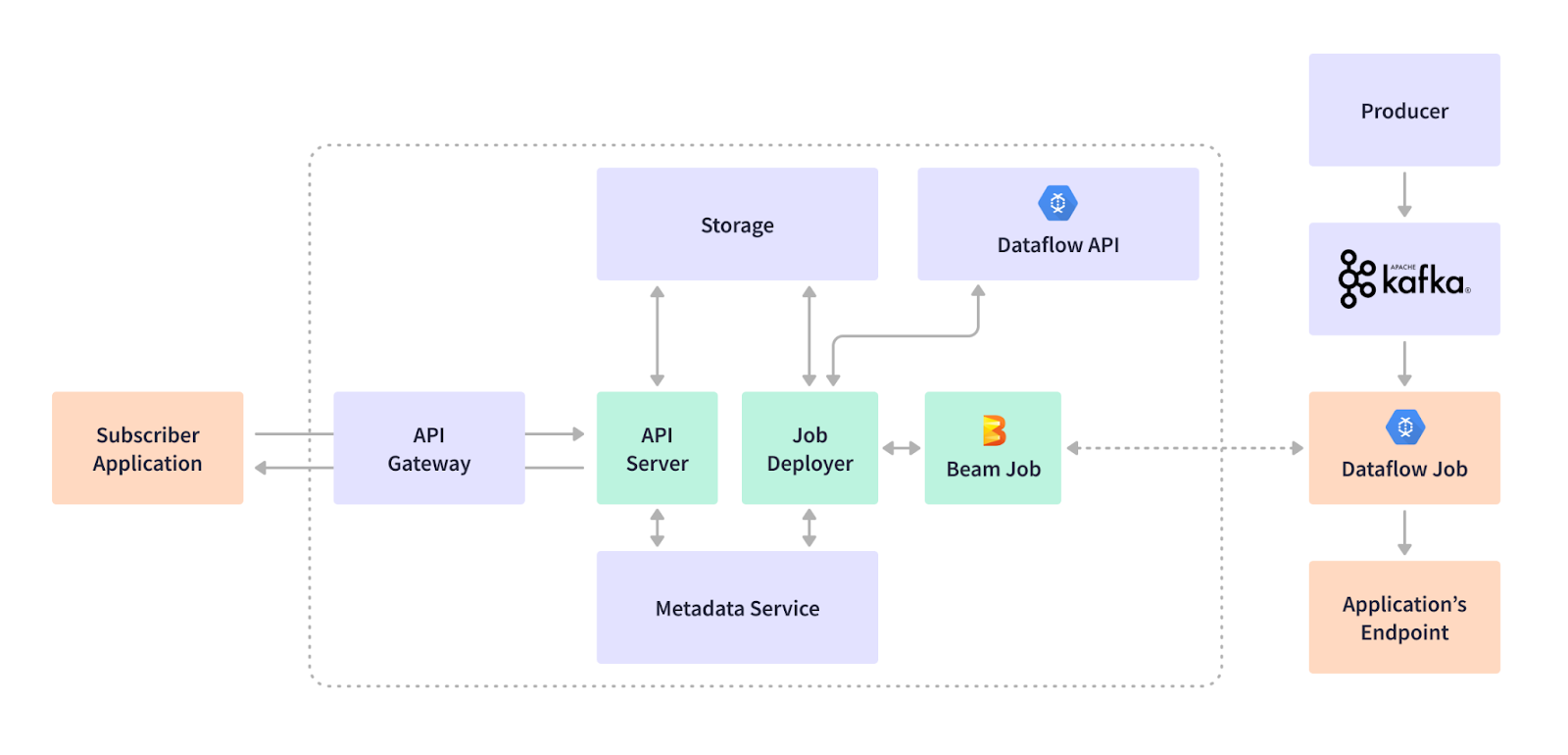
このマネージド型Dataflowベースのストリーミングインフラストラクチャは正常に動作しますが、いくつかの注意点があります。
- マネージドサービスであるため、コストが高くなります。vCPUやメモリなどのDataflowアプリケーションで使用されるリソースの場合、同じBeamアプリケーションコードを実行するFlinkなどのオープンソースストリーミングエンジンを使用する場合よりもはるかに高価です。
- 機能を拡張することが困難なため、レイテンシとSLAの目標を達成するのは容易ではありません。たとえば、異なるアプリケーション、エンドポイント、または1つのアプリケーション内の異なるパラメーターに基づくオートスケーリングなどです。
- パイプラインはGoogle Cloud上でのみ実行されます。
PANWのストリーミングユースケースの独自性は、セルフマネージドサービスを使用するもう1つの理由です。マルチテナントをサポートしています。テナント(顧客)は、非常に高いレート(秒間10万件を超えるリクエスト)または非常に低いレート(秒間100件未満のリクエスト)でデータを取り込むことができます。DataflowジョブはKubernetesではなくVM上で実行されるため、最小で1つのvCPUコアが必要です。小規模なテナントでは、これはリソースの無駄になります。ストリーミングインフラストラクチャは数千のジョブをサポートしており、ジョブに1つのコアを使用する必要がない場合、CPUの利用率はより効率的です。たとえば、½ vCPUコア以下のGoogle Kubernetes Engine(GKE)ポッドを使用して、小規模なテナントに最小限のリソースを割り当てることができるため、Kubernetes上で実行されるストリーミングエンジンを使用するのは自然です。
Apache FlinkとKubernetesの選択
すでに述べた問題に対処し、最も効率的な解決策を見つけるために、Dataflowに対してApache Samza、Apache Flink、Apache Sparkを含むさまざまなストリーミングフレームワークを評価しました。
パフォーマンス
- 注目すべき要因の1つは、Apache FlinkのネイティブKubernetesサポートでした。ネイティブKubernetesサポートがなく、調整にApache Zookeeperを必要とするSamzaとは異なり、FlinkはKubernetesとシームレスに統合されました。この統合により、不要な複雑さが排除されました。パフォーマンスに関しては、SamzaとFlinkはどちらも競合する製品でした。
- Apache Sparkは人気がありますが、私たちのテストでは大幅に遅くなりました。Beamサミットでのプレゼンテーションでは、Apache BeamのSpark RunnerはネイティブApache Sparkよりも約10倍遅いことが明らかになりました[3]。私たちは、そのような劇的なパフォーマンスの低下を許容できませんでした。特に、過去4年間でApache Beamを使用して構築してきた広範なコードベースを考えると、Beamコードベース全体をネイティブSparkで書き直すことは現実的な選択肢ではありませんでした。
コミュニティ
コミュニティサポートの堅牢性も、意思決定において重要な役割を果たしました。Dataflowは優れたサポートを提供しましたが、オープンソースフレームワークの選択において確信を持つ必要がありました。Apache Flinkの活気のあるコミュニティと、複数の企業からの積極的な貢献は、他に類を見ない自信を与えてくれました。この協調的な環境では、バグの特定と修正は継続的なプロセスでした。実際、私たちの取り組みでは、コミュニティからの多くのFlink修正を使用してシステムにパッチを適用しました。
- Google Cloud Storageファイル読み取りの例外を、Flink 1.15オープンソース修正FLINK-26063(1.13を使用)をマージすることで修正しました。
- ステートフルジョブの状態でのワーカー再起動の問題をFLINK-31963から修正しました。
また、Flink Kubernetes Operatorのオープンソースコードのバグを発見・修正することにより、取り組みを通してコミュニティに貢献しました。詳細については、FLINK-32700を参照してください。また、Kubernetesクライアント用の新しいGKE認証サポートを作成し、[4]のGitHubにマージしました。
統合
Apache FlinkとKubernetesのシームレスな統合により、オーケストレーションのための柔軟でスケーラブルなプラットフォームが提供されました。Apache FlinkとKubernetesの相乗効果により、データ処理ワークフローが最適化され、システムの将来性も確保されました。
アーキテクチャとデプロイメントワークフロー
リアルタイムデータ処理と分析の分野では、Apache Flinkは強力で多用途なフレームワークとして際立っています。業界標準のコンテナオーケストレーションシステムであるKubernetesと組み合わせることで、Flinkアプリケーションは水平方向にスケールし、堅牢な管理機能を備えることができます。Apache Flink Kubernetes Operatorのおかげで、Apache FlinkとKubernetesがシームレスに連携する最先端の設計について説明します。
中心となるのは、Flink Kubernetes Operatorが制御プレーンとして機能し、Flinkデプロイメントを管理する人間のオペレーターの知識と行動を反映していることです。従来の方法とは異なり、Operatorはアプリケーションの開始と停止からアップグレードとエラーの処理まで、重要なアクティビティを自動化します。その多様な機能セットには、完全に自動化されたジョブライフサイクル管理、さまざまなFlinkバージョンのサポート、アプリケーションクラスタやセッションジョブなどの複数のデプロイメントモードが含まれています。さらに、Operatorの運用能力は、メトリクス、ロギング、ジョブオートスケーラーを使用した動的なスケーリングにも及びます。
シームレスなデプロイメントワークフローの構築
Flinkジョブが簡単にデプロイされ、注意深く監視され、積極的に管理される堅牢なシステムを想像してください。私たちのチームは、Apache Flink、Apache Flink Kubernetes Operator、Kubernetesを統合することで、このワークフローを作成しました。この設定の中心となるのは、カスタムビルドのApache Flink Kubernetes Operatorクライアントライブラリです。このライブラリはブリッジとして機能し、Flinkジョブの開始、停止、更新、キャンセルなどのアトミック操作を可能にします。
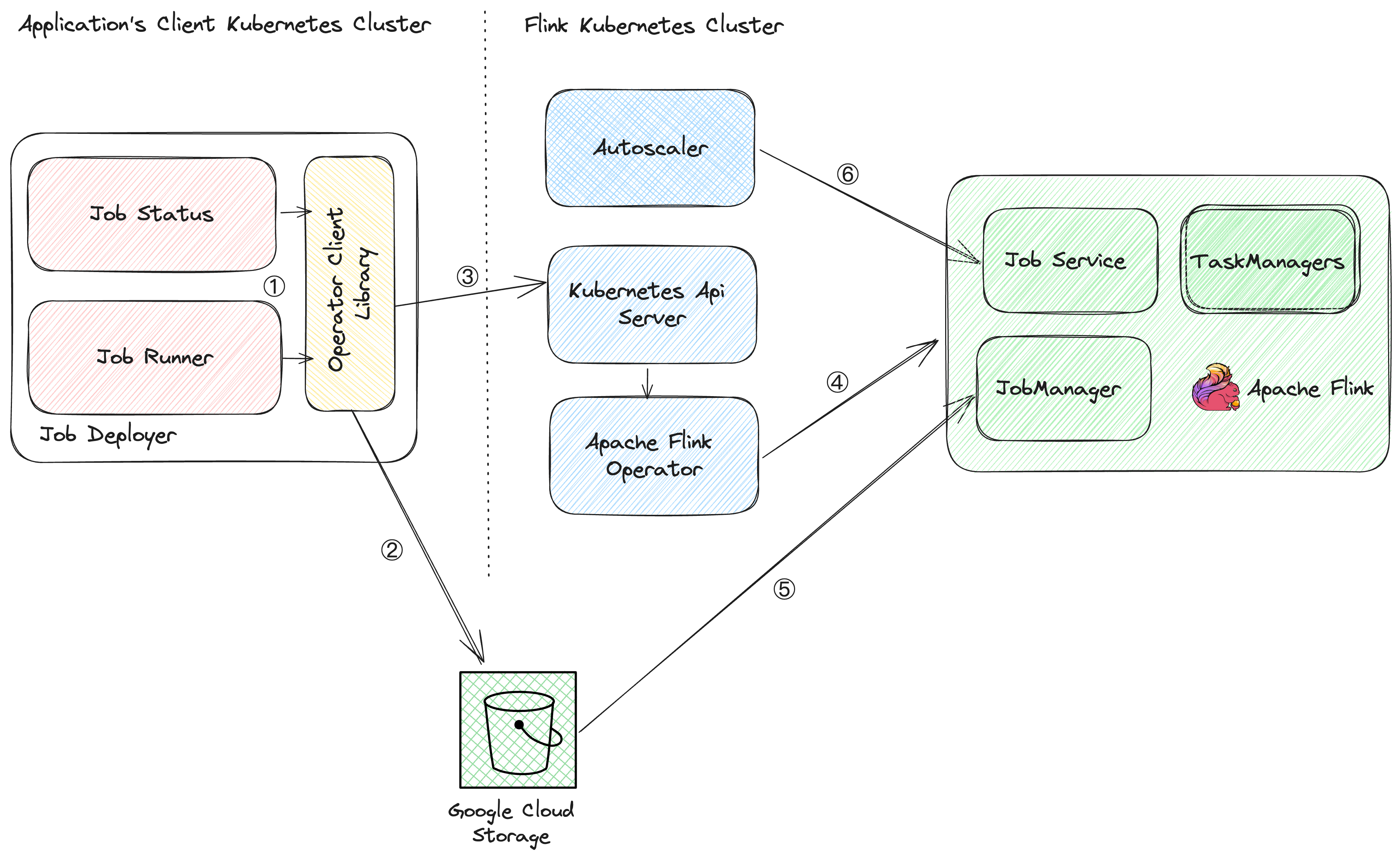
デプロイメントプロセス
コードでは、クライアントは、KubernetesクラスタのAPIエンドポイント、認証の詳細、JARファイルをアップロードするためのGoogle Cloud/S3の一時的な場所、ワーカートイプの仕様など、重要な情報を含むApache Beamパイプラインオプションを提供します。Kubernetes Operatorライブラリは、この情報を使用して、シームレスなデプロイメントプロセスをオーケストレートします。次のセクションでは、実行された手順について説明します。ほとんどのコアステップはコードベースで自動化されています。
ステップ1
- クライアントは、顧客と特定のアプリケーションのジョブを開始します。
ステップ2
- **一意のジョブIDの生成:** ライブラリは、Kubernetesラベルとして設定される一意のジョブIDを生成します。この識別子は、デプロイされたFlinkジョブの追跡と管理に役立ちます。
- **設定とコードのアップロード:** ライブラリは、必要なすべての設定とユーザーコードをGoogle Cloud StorageまたはAmazon S3の指定された場所にアップロードします。この手順により、Flinkアプリケーションのリソースがデプロイメントに使用できるようになります。
- **YAMLペイロードの生成:** アップロードプロセスが完了すると、ライブラリはYAMLペイロードを構築します。このペイロードには、指定されたワーカートイプに基づいたリソース設定など、重要なデプロイメント情報が含まれています。
ワーカーVMインスタンスタイプの名前付けには、規則を使用しました。私たちの規則は、Google Cloudが使用する名前付け規則に似ています。名前`n1-standard-1`は、特定の事前に定義されたVMマシンタイプを参照しています。名前の各コンポーネントの意味を分解してみましょう。
- n1 はインスタンスのCPUタイプを示します。この場合、N1シリーズのインスタンスに基づくIntelプロセッサを指します。Google Cloudには、ハードウェアとパフォーマンス特性が異なる複数世代のインスタンスがあります。
- standard はマシンタイプのファミリを表します。標準マシンタイプは、Task Managerに対して1仮想CPU(vCPU)と4GBのメモリ、Job Managerに対して0.5 vCPUと2GBのメモリというバランスの取れた比率を提供します。
- 1 はインスタンスで使用可能なvCPUの数です。n1-standard-1の場合、インスタンスは1つのvCPUを備えていることを意味します。
ステップ3
- Fabric8を使用したKubernetes APIの呼び出し:デプロイを開始するために、ライブラリはFabric8を使用してKubernetes APIとやり取りします。Fabric8は当初、Google Kubernetes EngineまたはAmazon Elastic Kubernetes Service(EKS)での認証をサポートしていませんでした。この制限に対処するために、チームは必要な認証サポートを実装しました。これはGitHub PR [4]のmerge requestで見つけることができます。
ステップ4
- Flink Operatorのデプロイ:YAMLペイロードを受信すると、Flink OperatorはFlinkジョブのさまざまなコンポーネントのデプロイを担当します。タスクには、リソースのプロビジョニングと、Flink Job Manager、Task Manager、Job Serviceのデプロイの管理が含まれます。
ステップ5
- ジョブの送信と実行:Flink Job Managerが実行されると、指定されたGoogle Cloud StorageまたはS3の場所からJARファイルと構成を取得します。必要なリソースがすべて揃うと、スタンドアロンのFlinkクラスタにFlinkジョブを送信して実行します。
ステップ6
- 継続的な監視:デプロイ後、オペレーターは実行中のFlinkジョブの状態を継続的に監視します。このリアルタイムのフィードバックループにより、発生した問題に迅速に対処し、Flinkアプリケーション全体の健全性と最適なパフォーマンスを確保できます。
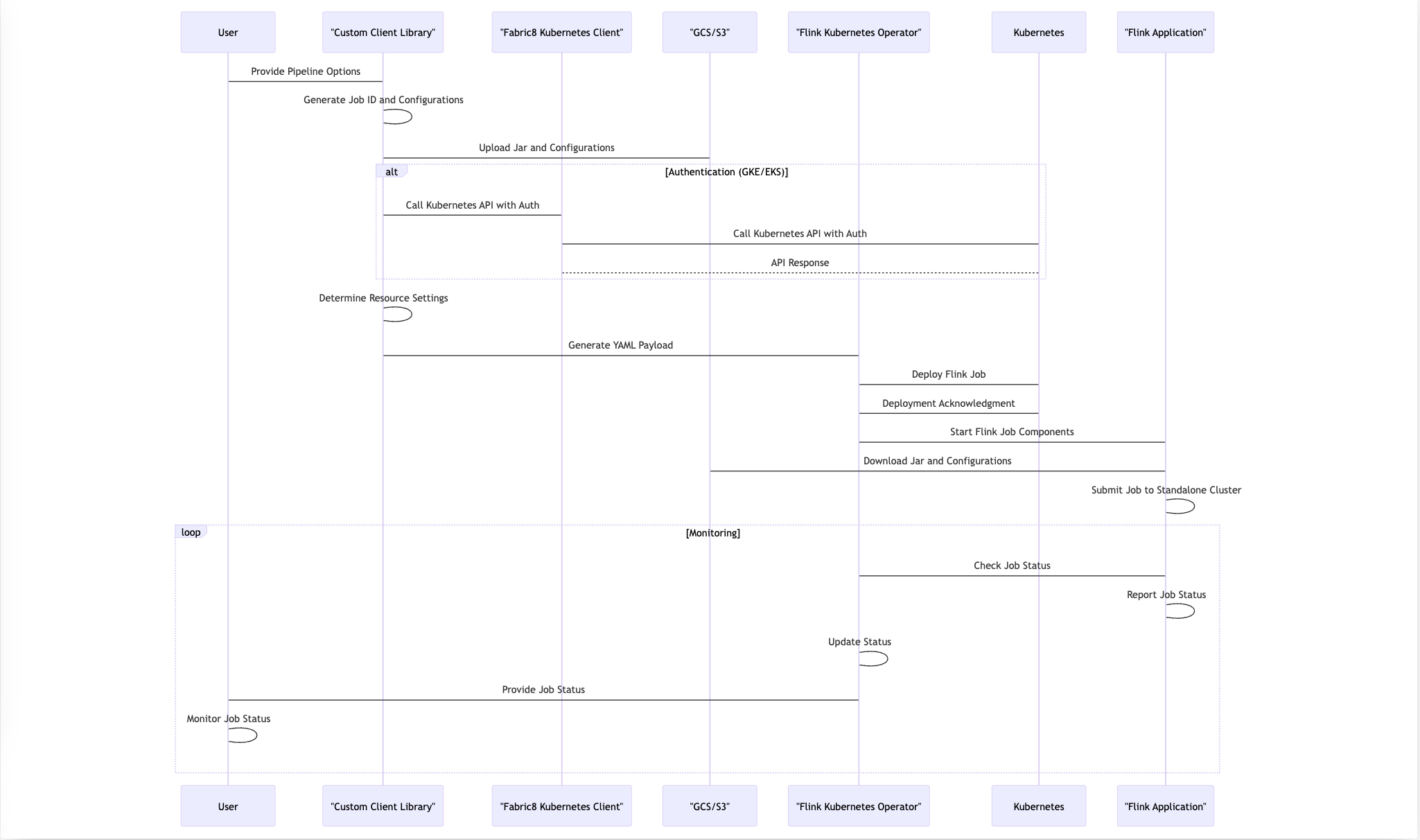
要約すると、私たちのデプロイプロセスはApache Beamパイプラインオプションを活用し、KubernetesとFlink Operatorとシームレスに統合し、構成のアップロードと認証を処理するためのカスタムロジックを使用します。このエンドツーエンドのワークフローにより、スムーズな運用のための継続的な監視を維持しながら、KubernetesクラスタへのFlinkアプリケーションの信頼性が高く効率的なデプロイが保証されます。以下のシーケンス図は、手順を示しています。
オートスケーラーの開発
自己管理型ストリーミングサービスを実現するには、オートスケーラーが不可欠です。独自のオートスケーラーの構築方法を学ぶための十分なリソースがインターネット上にはなく、このワークフローの一部が困難になっています。
オートスケーラーは、遅延を解消し、スループットを維持するために、タスクマネージャーの数をスケールアップします。また、着信トラフィックを処理するために必要な最小限のリソースにスケールダウンして、コストを削減します。処理の中断を最小限に抑えながら、頻繁にこれを行う必要があります。
レイテンシのSLAを満たすために、オートスケーラーを徹底的に調整しました。この調整には、コストのトレードオフが含まれていました。また、特定のアプリケーションの特定のニーズを満たすために、オートスケーラーをアプリケーション固有のものにしました。すべての決定には隠れたコストがあります。このブログの後半では、オートスケーラーの詳細について説明します。
ストリーミングジョブ開発用のクライアントライブラリの作成
Flink Kubernetes Operatorを使用してジョブをデプロイするには、Kubernetesの仕組みについて理解する必要があります。次の手順では、単一のFlinkジョブを作成する方法を説明します。
- 適切な仕様を記述したYAMLファイルを作成します。次の図に例を示します。
apiVersion: flink.apache.org/v1beta1
kind: FlinkDeployment
metadata:
name: basic-reactive-example
spec:
image: flink:1.13
flinkVersion: v1_13
flinkConfiguration:
scheduler-mode: REACTIVE
taskmanager.numberOfTaskSlots: "2"
state.savepoints.dir: file:///flink-data/savepoints
state.checkpoints.dir: file:///flink-data/checkpoints
high-availability: org.apache.flink.kubernetes.highavailability.KubernetesHaServicesFactory
high-availability.storageDir: file:///flink-data/ha
serviceAccount: flink
jobManager:
resource:
memory: "2048m"
cpu: 1
taskManager:
resource:
memory: "2048m"
cpu: 1
podTemplate:
spec:
containers:
- name: flink-main-container
volumeMounts:
- mountPath: /flink-data
name: flink-volume
volumes:
- name: flink-volume
hostPath:
# directory location on host
path: /tmp/flink
# this field is optional
type: Directory
job:
jarURI: local:///opt/flink/examples/streaming/StateMachineExample.jar
parallelism: 2
upgradeMode: savepoint
state: running
savepointTriggerNonce: 0
mode: standalone
- FlinkクラスタにSSH接続し、次のコマンドを実行します。
kubectl create -f job1.yaml
- 次のコマンドを使用して、ジョブの状態を確認します。
kubectl get flinkdeployment job1
このプロセスは、スケーラビリティに影響を与えます。ジョブを頻繁に更新するため、実行中のすべてのジョブに対してこれらの手順を手動で実行することはできません。そうすると、非常にエラーが発生しやすく、時間がかかります。YAML内のスペースが1つ間違っていても、デプロイが失敗する可能性があります。このアプローチは、Flinkジョブとやり取りするにはKubernetesについて知っている必要があるため、イノベーションの障壁にもなります。
ジョブの開始、削除、更新、状態の取得をしたいチームやアプリケーションのためのインターフェースを提供するライブラリを構築しました。
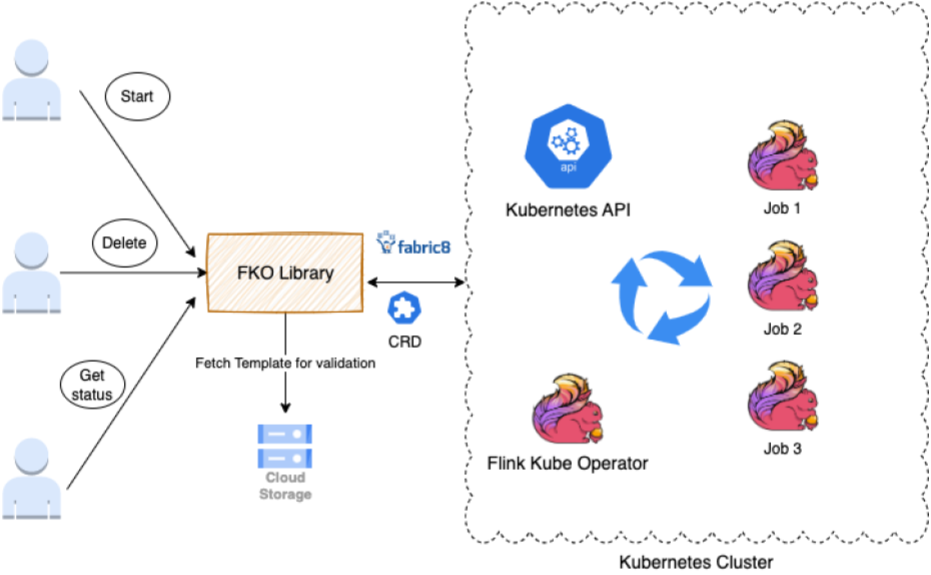
このライブラリは、Fabric8クライアントとFlinkDeployment CRDを拡張します。FlinkDeployment CRDはFlink Kubernetes Operatorによって公開されています。CRDを使用すると、構造化データを保存および取得できます。CRDを拡張することで、POJOにアクセスできるようになり、YAMLファイルの操作が容易になります。
ライブラリは次のタスクをサポートします。
- Flinkクラスタでアクションを実行する権限があることを確認するための認証。
- 検証(AWS/Google Cloud Storageからテンプレートを取得して検証)は、ユーザーの変数入力を取り、ポリシー、ルール、YAML形式に対して検証します。
- アクションの実行は、Kubernetes操作を呼び出すJava呼び出しに変換します。
このプロセスを通して、次の教訓を学びました。
- アプリケーション固有のオペレーターサービス:大規模なため、オペレーターはこれほど多くのジョブを処理できませんでした。Kubernetesの呼び出しがタイムアウトして失敗し始めました。この問題を解決するために、トラフィック量の多い地域に複数のオペレーター(約4つ)を作成して、各アプリケーションを処理しました。
- Kube呼び出しのキャッシング:オーバーロードを防ぐために、Kubernetes呼び出しの結果を30〜60秒間キャッシュしました。
- ラベルのサポート:クライアント固有の変数を使用してジョブを検索するためのラベルのサポートを提供することで、Kubeへの負荷を軽減し、ジョブ検索速度を5倍向上させました。
ライブラリを公開することで実現した最大の成果の一部を以下に示します。
- 標準化されたジョブ管理:ユーザーは、単一のライブラリを使用して、Kubernetes環境でFlinkジョブの状態の開始、削除、更新を行うことができます。
- Kubernetesの複雑さの抽象化:チームは、Kubernetesの内部動作やジョブデプロイYAMLファイルのフォーマットについて心配する必要がなくなりました。ライブラリはこれらの詳細を内部的に処理します。
- 簡素化されたアップグレード:基礎となるKubernetesインフラストラクチャにより、ライブラリはFlinkジョブ管理に堅牢性とフォールトトレランスをもたらし、ダウンタイムを最小限に抑え、効率的な復旧を保証します。
可観測性とアラート
大規模な運用システムを実行する際には、可観測性が重要です。PANWには約3万のストリーミングジョブがあります。各ジョブは、特定のアプリケーションの顧客にサービスを提供します。各ジョブは、Kafkaの複数のトピックからデータを読み取り、変換を実行してから、さまざまなシンクとエンドポイントにデータを書き込みます。
顧客API、BigQueryなど、パイプラインまたはそのエンドポイントのどこにでも制約が発生する可能性があります。ストリーミングのレイテンシがSLAを満たしていることを確認したいと考えています。したがって、ジョブが正常に動作し、SLAを満たしているかどうかを理解し、必要に応じてアラートを発して介入することは非常に困難です。
運用目標を達成するために、洗練された可観測性とアラート機能を構築しました。次のセクションで説明する3種類の可観測性とデバッグツールを提供します。
PrometheusとGrafanaからのFlinkジョブリストとジョブのインサイト
各Flinkジョブは、アプリケーション名、顧客ID、リージョンなどのカーディナリティの詳細を伴うさまざまなメトリクスをPrometheusに送信するため、各ジョブを確認できます。重要なメトリクスには、入力トラフィックレート、出力スループット、Kafkaのバッファ、タイムスタンプベースのレイテンシ、タスクのCPU使用率、タスク数、OOMカウントなどがあります。
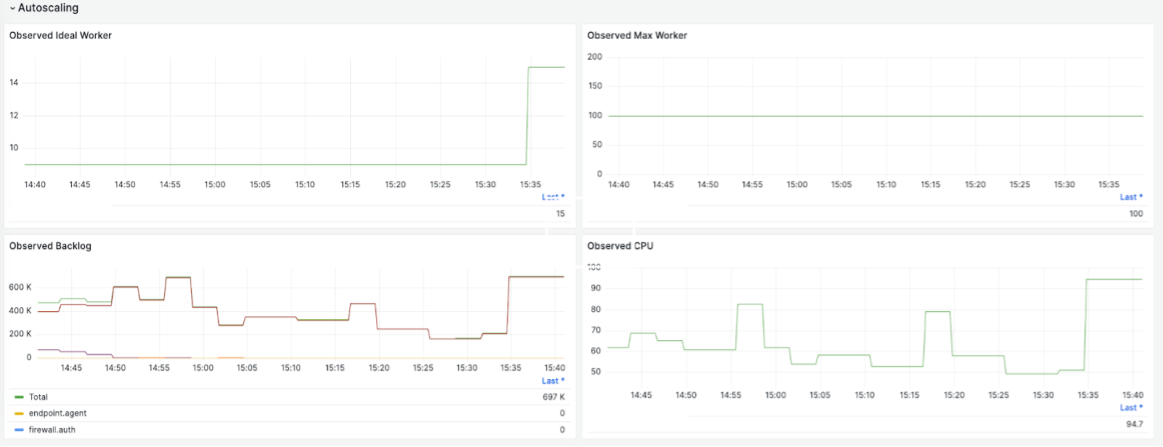
次のチャートは、いくつかの例を示しています。チャートは、特定の顧客へのKafkaへの取り込みトラフィックレート、ストリーミングジョブ全体のスループット、各vCPUのスループット、Kafkaのバッファ、観測されたバッファに基づくワーカーの自動スケーリングに関する詳細を提供します。
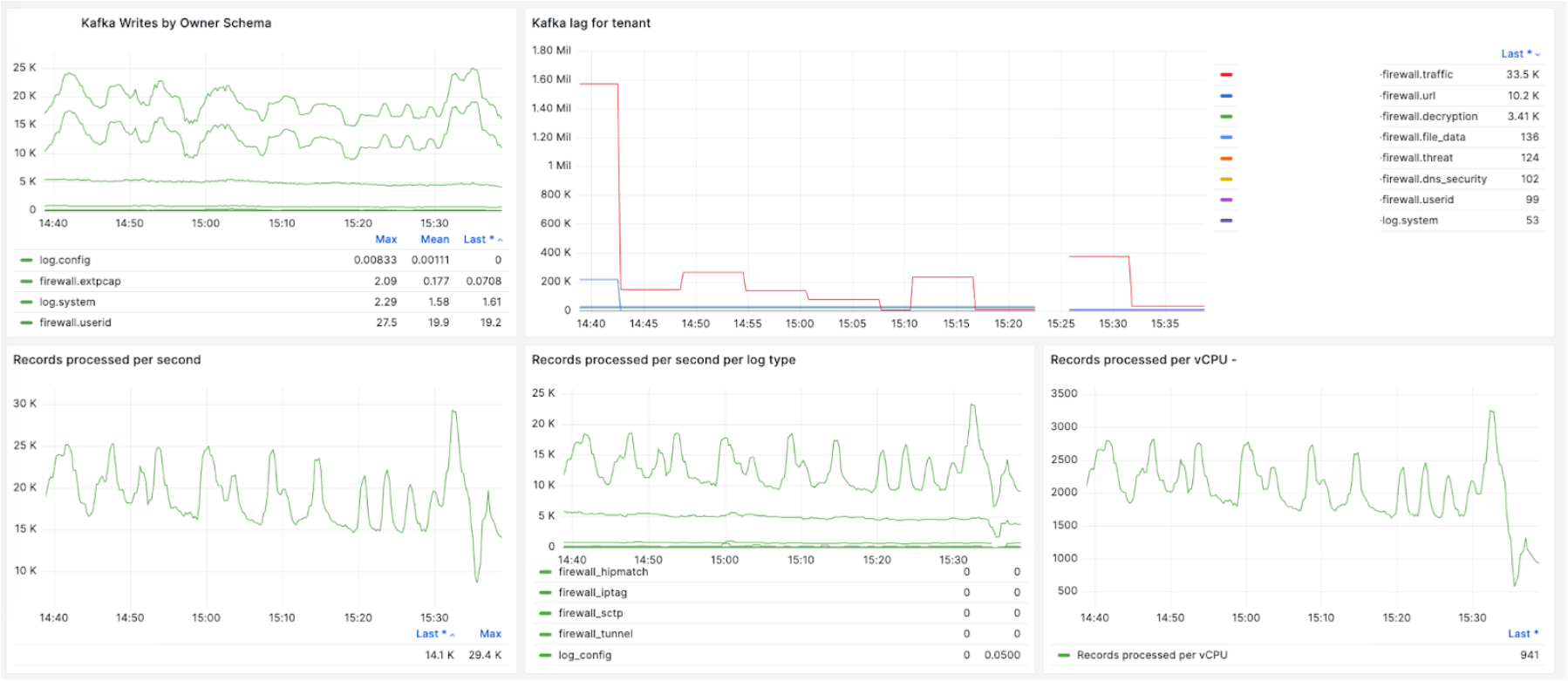
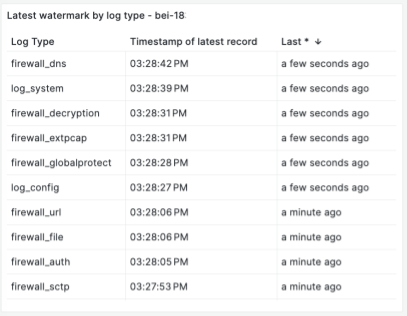
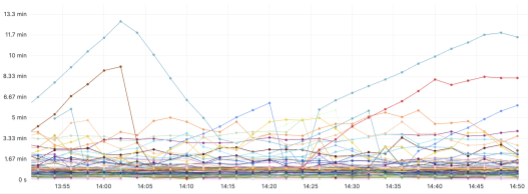
次のチャートは、タイムスタンプウォーターマークに基づいたストリーミングレイテンシを示しています。Kafkaのバッファとしてイベントの数に加えて、SLAを定義および監視するために、エンドツーエンドのストリーミングの時間レイテンシを知ることも重要です。レイテンシは、取り込みタイムスタンプからストリーミングエンドポイントへの送信タイムスタンプまでのストリーミング処理にかかった時間として定義されます。ウォーターマークは、最後に処理されたイベントの時間です。ウォーターマークを使用すると、P100レイテンシを追跡しています。各イベントのストリームレイテンシを追跡するため、各Kafkaトピックとパーティション、またはFlinkジョブパイプラインの問題を理解できます。次の例は、各イベントストリームとそのレイテンシを示しています。
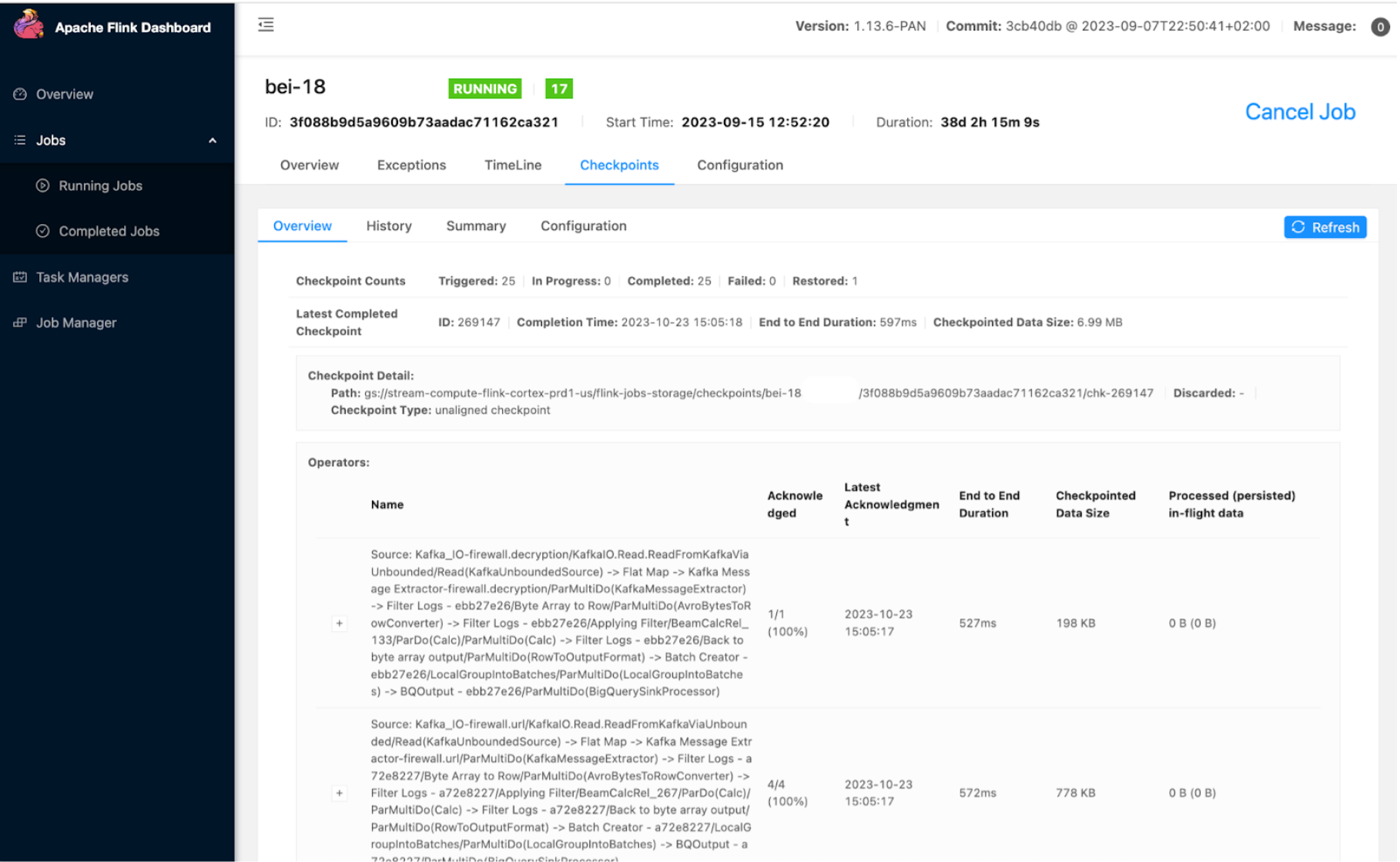
FlinkオープンソースUI
Apache FlinkダッシュボードUIを使用して、チェックポイントの期間、サイズ、失敗などのジョブとタスクを監視します。使用した重要な拡張機能の1つは、ジョブの開始と更新のタイムラインと詳細を確認できるジョブ履歴ページです。これにより、問題のデバッグに役立ちます。
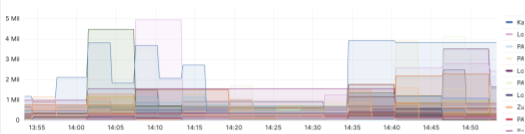
バッファとレイテンシのダッシュボードとアラート
約3万のジョブがあり、ジョブを綿密に監視し、異常な状態のジョブに対してアラートを受信して介入できるようにしたいと考えています。レイテンシが最も高いジョブのリストを表示し、アラートのしきい値を作成できるように、各アプリケーションのダッシュボードを作成しました。次の例は、1つのアプリケーションのタイムスタンプベースのレイテンシダッシュボードを示しています。レイテンシが10分などのしきい値を超えて一定時間継続した場合に、アラートを設定できます。
次の例は、さらにバッファベースのダッシュボードを示しています。
アラートはしきい値に基づいており、メトリクスを頻繁にチェックします。しきい値に達し、一定回数継続すると、内部SlackチャンネルまたはPagerDutyにアラートを送信して、すぐに対応します。精度が高くなるようにアラートを調整します。
コスト最適化戦略とチューニング
コスト効率を向上させるために、自己管理型ストリーミングサービスに移行しました。いくつかのマイナーなチューニングにより、コストを半分に削減することができ、さらに改善の余地があります。
役に立ったヒントをいくつか以下に示します。
- チェックポイントストレージとしてGoogle Cloud Storageを使用します。
- Google Cloud Storageへの書き込み頻度を削減します。
- 適切なマシンタイプを使用します。たとえば、Google Cloudでは、N2DマシンはN2マシンよりも15%安価です。
- レイテンシのSLAを維持しながら、最適なリソースを使用するためにタスクを自動スケーリングします。
次のセクションでは、最初の2つのヒントについて詳しく説明します。
Google Cloud Storageとチェックポイント
コスト効率が高く、スケーラブルで耐久性があるため、チェックポイントストアとしてGoogle Cloud Storageを使用しています。Google Cloud Storageを使用する際には、次の設計上の考慮事項とベストプラクティスにより、スケーリングとパフォーマンスを最適化できます。
- 特定の属性に基づいてデータを分割する範囲パーティショニングや、ハッシュ関数を使用してデータを均等に分散するハッシュパーティショニングなどのデータパーティショニング方法を使用します。
- ホットスポットとデータの不均一な分散を避けるために、特にタイムスタンプなどのシーケンシャルなキー名は避けてください。代わりに、オブジェクトの分散のためにランダムなプレフィックスを導入します。
- 階層的なフォルダ構造を使用して、データ管理を改善し、単一のディレクトリ内のオブジェクト数を減らします。
- 読み取りスループットを向上させるために、小さなファイルを大きなファイルに結合します。小さなファイルの数を最小限に抑えることで、非効率的なストレージの使用とメタデータ操作を削減します。
Google Cloud Storageへの書き込み頻度の調整
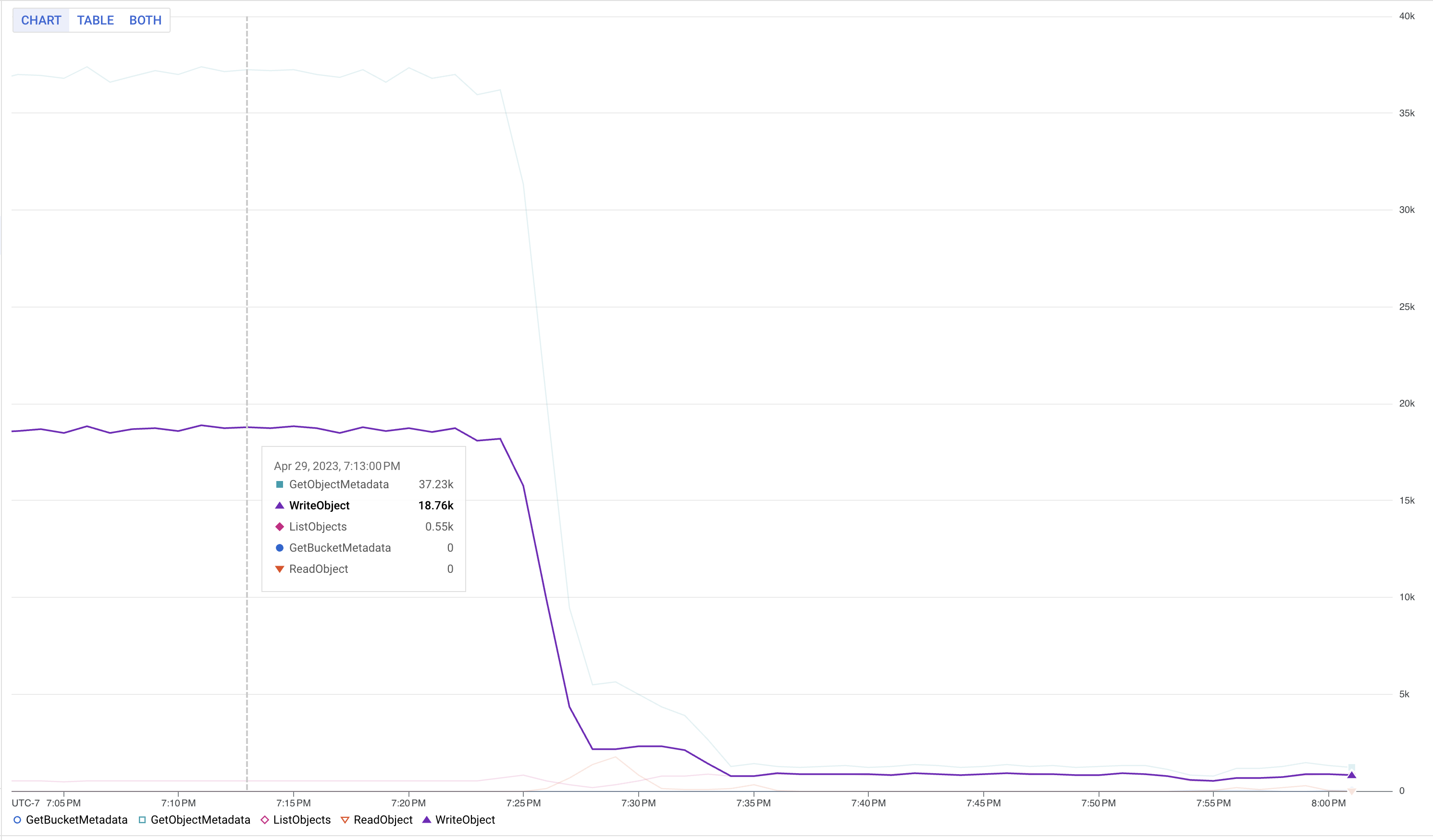
ジョブの効率的なスケーリングは、私たちの主要な課題の1つでした。比較的単純なステートレスジョブでも、Flinkが膨大な数のワーカーを処理する必要があるシナリオでは、特に障害が発生します。この課題を克服するために、state.storage.fs.memory-threshold設定を20KBから1MBに増やしました(??)。この設定により、ジョブマネージャーレベルで小さなチェックポイントファイルを大きなファイルに結合し、メタデータ呼び出しを削減することができました。
Google Cloud操作のパフォーマンスの最適化も別の課題でした。Google Cloud Storageは大量のデータをストリーミングするのに優れていますが、高頻度のI/Oリクエストを処理する際には制限があります。この問題を軽減するために、キー名にランダムなプレフィックスを導入し、シーケンシャルなキー名を避け、Google Cloud Storageのシャーディングテクニックを最適化しました。これらの方法により、Google Cloud Storageのパフォーマンスが大幅に向上し、ステートレスジョブのスムーズな動作が可能になりました。
次のチャートは、memory-thresholdを変更した後のGoogle Cloud Storageへの書き込みの削減を示しています。
結論
Palo Alto Networks® Cortex Data Lakeは、DataflowストリーミングエンジンからFlink自己管理型ストリーミングエンジンインフラストラクチャへの完全移行を完了しました。これにより、システムをよりコスト効率的に運用する(コストを半分以上に削減)こと、GCPやAWSなどの複数のクラウド上でインフラストラクチャを運用することが実現しました。オープンソースに基づいた大規模で信頼性の高い本番システムの構築方法を学ぶことができました。オープンソースコードと設定を自由にカスタマイズできるため、特定のニーズに基づいてシステムをカスタマイズする大きな可能性があると認識しています。次回のPart 2の記事では、自動スケーリングとパフォーマンスチューニングの詳細について説明します。本経験が、同様のソリューションを自組織で検討されている読者の皆様のお役に立てれば幸いです。
追加リソース
同様のソリューションの実装に関心のある読者の皆様のために、関連プレゼンテーションへのリンクをさらに読むための資料としてここに掲載しています。このセクションを追加することで、完全に管理されたストリーミングインフラストラクチャを構築するための詳細情報を見つけていただき、読者の皆様が私たちの取り組みと学びをより簡単に理解できることを願っています。
[1] Apache Beamで公開されたPANWのストリーミングフレームワーク:https://beam.dokyumento.jp/case-studies/paloalto/
[2] Beam Summit 2023でのPANWプレゼンテーション:https://youtu.be/IsGW8IU3NfA?feature=shared
[3] Beam Summit 2021で発表されたベンチマーク:https://2021.beamsummit.org/sessions/tpc-ds-and-apache-beam/
[4] GKE認証サポートのためのFlinkへのPANWオープンソース貢献:https://github.com/fabric8io/kubernetes-client/pull/4185
謝辞
クラウドプロバイダーが管理するストリーミングインフラストラクチャから、自己管理型のFlinkベースのインフラストラクチャへの大規模な顧客ベースのアプリケーションの移行、および新しいインフラストラクチャの構築は、大規模な取り組みでした。この実現に貢献してくれたPalo Alto Networks CDLストリーミングチームのKishore Pola、Andrew Park、Hemant Kumar、Manan Mangal、Helen Jiang、Mandy Wang、Praveen Kumar Pasupuleti、JM Teo、Rishabh Kedia、Talat Uyarer、Naitk Dani、David Heに感謝します。